






说明:
本文会实现自定义模型实现对MINIST数据集的训练,训练完之后还会使用测试集进行测试。所依托的训练集和测试集都是由datasets.MNIST获取到的。
步骤
下载数据
现在来介绍加载 MNIST 数据集并准备训练和测试数据的逻辑。
-
数据预处理:
-
transforms.Compose创建了一个数据预处理管道,将多个数据转换操作组合在一起。将图像转换为 PyTorch 的张量(tensor).对图像进行标准化,使其均值为 0.1307,标准差为 0.3081。
-
-
创建数据集:
-
我们指出指定MINIST数据集的存储位置,表示如果数据集不存在,便自动下载,从而创建
MNIST数据集的实例train_dataset。 另使用了transform=transform指出要使用之前定义的数据预处理管道。
-
-
加载数据:
-
使用 DataLoader 实例批量加载数据,使用
batch_size=batch_size指定每个批次的样本数量,并在每个 epoch 开始时随机打乱数据。
-
//表示每个训练或测试批次中的样本数量。
batch_size = 64
//进行数据库处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
//创建训练集
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
//加载训练集
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
//创建测试集
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
//加载测试集
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)定义神经网络模型
这段代码定义了一个简单的前馈神经网络模型,用于分类手写数字。 首先,我们定义了一个名为 Net 的类,继承自 torch.nn.Module。(torch.nn.Module是一个基类,用于构建神经网络模型。)
在 init 方法中,我们初始化了五个全连接层(self.l1 到 self.l5):
self.l1:输入层到第一个隐藏层,输入维度为 784(对应 MNIST 图像的像素数),输出维度为 512。
self.l2:第一个隐藏层到第二个隐藏层,输出维度为 256。
self.l3:第二个隐藏层到第三个隐藏层,输出维度为 128。
self.l4:第三个隐藏层到第四个隐藏层,输出维度为 64。
self.l5:最后一个隐藏层到输出层,输出维度为 10(对应手写数字的类别数)。
在 forward 方法中,我们定义了数据在网络中的流动:
首先,输入数据 x 被展平为形状 (batch_size, 784)。然后,通过 ReLU 激活函数依次传 递给每个隐藏层。最后,输出层不使用激活函数,直接返回结果。
最后,创建了一个名为 model 的实例,即我们定义的神经网络模型。
注:这里详细介绍一下x.view(-1, 784)
x.view(-1, 784)
x是一个张量。
.view(-1, 784)的作用是将x转换为一个新的形状,其中-1表示自动计算该维度的大小,而784是我们指定的另一个维度的大小。这里是将
x从原始形状(三维图片)转换为一个形状为(batch_size, 784)的二维张量。
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()构造损失函数和优化器
-
torch.nn.CrossEntropyLoss()是一个损失函数,通常用于分类任务。它计算模型预测与真实标签之间的交叉熵损失。 -
optim.SGD(model.parameters(), lr=0.01, momentum=0.5)创建了一个随机梯度下降(SGD)优化器。它用于更新模型的参数,以最小化损失函数。
具体来说:
-
lr=0.01表示学习率为 0.01,控制参数更新的步长。 -
momentum=0.5是动量项,有助于加速收敛。
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)训练模型
这段代码是一个训练循环,用于训练神经网络模型。让我详细解释一下它的逻辑:
-
初始化
running_loss为 0.0。
-
对于每个批次(batch)的数据,执行以下操作:
-
将
running_loss重置为 0.0。 -
如果当前批次的索引
batch_idx是 300 的倍数(即每 300 个批次),则打印平均损失:print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))。 -
累积当前批次的损失到
running_loss。 -
更新模型参数:
optimizer.step()。 -
反向传播计算梯度:
loss.backward()。 -
计算模型输出与目标之间的损失:
loss = criterion(outputs, target)。 -
前向传播计算模型的输出:
outputs = model(inputs)。 -
将优化器的梯度缓存清零:
optimizer.zero_grad()。 -
从
train_loader中获取输入数据inputs和目标数据target。
-
注:
我这里解释一下为什么通过inputs, target = data语句便可直接将特征,标签分出来。
因为
train_loader已经自动将输入数据inputs和目标数据target分开了。在训练循环中,我们可以直接使用这两个变量,无需手动分离它们。另外再来分析一下input和target的存在形式。举个例子,如果我们的数据集中有 100 张图像,每张图像有 3 个通道(RGB),我们的目标是分类任务(共有 10 个类别),那么:
inputs的维度是 (100, 3, 图像高度, 图像宽度)
target的维度是 (100,)
另外我再阐述一点: 下述代码每次 for 循环迭代都处理一个批次的训练数据。当 for 循环执行完毕,即所有批次都被处理后,表示一个 epoch 的训练完成。
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0测试模型
-
首先,我们初始化两个变量:
correct和total,分别用于记录正确预测的样本数和总样本数。 -
然后,我们使用
torch.no_grad()上下文管理器,以确保在测试阶段不会计算梯度。在测试时,我们只关心模型的预测结果,而不需要更新权重。 -
接下来,我们遍历测试数据集中的每个批次。每个批次包含一组图像和对应的标签。
-
对于每个批次,我们使用模型对图像进行预测,得到输出
outputs。 -
使用
torch.max(outputs.data, dim=1),我们获取每个样本预测的最大值及其对应的索引。这里的索引就是预测的类别。 -
我们累加正确预测的样本数,即
correct += (predicted == labels).sum().item()。这里比较predicted和labels是否相等,以判断预测是否正确。 -
同时,我们累加总样本数,即
total += labels.size(0)。 -
最后,我们计算准确率并打印出来:
print('Accuracy on test set: %d %%' % (100 * correct / total))。
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))main函数运行
最后我们在main函数中运行以下代码:
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()补充:
一.数据标准化
当我们在处理图像数据时,常常需要对其进行预处理,其中之一就是使用 transforms.Normalize进行数据的标准化。
执行完的效果是:
-
零均值:通过减去每个通道的均值,使数据的平均值接近零。
-
单位方差:通过除以每个通道的标准差,使数据的方差接近 1。
这样做的好处包括:
-
更稳定的训练:标准化可以帮助模型更快地收敛,减少梯度爆炸或梯度消失的问题。
-
更好的特征表示:标准化有助于模型更好地学习图像特征,提高分类、检测和分割等任务的性能。
我们会使用 transforms.ToTensor() 将输入的图像数据从形状 (H, W, C) 转换为 (C, H, W),然后,我们将所有像素值除以 255,将数据归一化到 [0, 1] 的范围。
下面具体介绍transforms.Normalize:
-
这一步通过公式
x = (x - mean) / std来进行标准化。具体来说,对于每个通道,我们将数据减去该通道的平均值,再除以标准差,将归一化后的数据变换到 [-1, 1] 之间。
-
所以我们需要先计算一批数据的均值和标准差,然后带入公式进行标准化。
再具体讲一下:
对于图像数据,我们使用均值和标准差来对每个通道进行标准化。例如,对于灰度图像,我们只有一个通道,所以只需计算一个均值和一个标准差。对于彩色图像,我们有三个通道(红、绿、蓝),因此需要计算三个通道的均值和标准差。
二.CrossEntropyLoss和LogSoftmax+NLLLoss的区别
在分类任务中,我们的神经网络会输出一个概率分布,表示每个类别的概率。这些概率通常是将原始输出(logits)通过 softmax 函数计算得出的。
进而我们需要利用损失函数计算这些概率与中真实标签的差距。这里介绍两个损失函数:CrossEntropyLoss和LogSoftmax+NLLLoss。
-
CrossEntropyLoss是一个整合了nn.LogSoftmax()和nn.NLLLoss()的损失函数。它的输入是原始网络输出(也称为 logits),而不是 softmax 函数的输出。因此,我们可以说CrossEntropyLoss 是一步到位的损失函数。
-
LogSoftmax函数,能将输入的每一行转换为带有负号的数字。
-
NLLLoss 是负对数似然损失函数,用于计算预测结果与真实标签之间的差异。
在 LogSoftmax+NLLLoss 中:
我们首先应用 LogSoftmax,将预测的概率分布转换为对数概率,再取这个概念的负数作为损失。
然后使用 NLLLoss 计算损失。
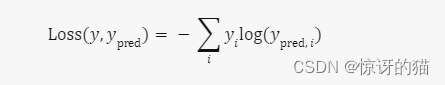
我们的目标是最小化 NLLLoss,使模型的预测结果更接近真实标签。
总结:
以上介绍了LogSofrmax搭配NLLoss计算损失函数的过程,而CrossEntropyLoss函数便是讲这个两个函数进行整合的一个函数。
三.Python部分语法说明
在上述定义神经网络时,我们通过 super(Net, self).__init__(),我们调用了父类(nn.Module)的构造函数,初始化继承自父类的属性。
下面让我们具体来介绍一下这个语法:
1.构造方法:
在创建类时,我们可以手动添加一个 init() 方法,该方法是一个特殊的类实例方法,称为构造方法。
def __init__(self,...):
代码块 另外,init() 方法可以包含多个参数,但必须包含一个名为 self 的参数,且必须作为第一个参数。也就是说,类的构造方法最少也要有一个 self 参数。
即便不手动为类添加任何构造方法,Python 也会自动为类添加一个仅包含 self 参数的构造方法。
仅包含 self 参数的 init() 构造方法,又称为类的默认构造方法。
self 参数是特殊参数,不需要手动传值,Python 会自动传给它值。
2.self是什么?
-
在 Python 类中,函数的第一个参数约定俗成为
self,表示实例对象。 -
self可以理解为 Java 中的this。在类的方法中,self不可省略。
也就是说,同一个类可以产生多个对象,当某个对象调用类方法时,该对象会把自身的引用作为第一个参数自动传给该方法,换句话说,Python 会自动绑定类方法的第一个参数指向调用该方法的对象。如此,Python解释器就能知道到底要操作哪个对象的方法了。
四. torch.optim.SGD
torch.optim.SGD 是 PyTorch 中用于实现随机梯度下降(Stochastic Gradient Descent,SGD)优化算法的类。SGD 是一种常用的优化算法,尤其在深度学习中被广泛应用。
我们上述在构造优化器时:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)其中的几个参数说明如下:
params(必须参数): 这是一个包含了需要优化的参数(张量)的迭代器,例如模型的参数 model.parameters()。
lr(必须参数): 学习率(learning rate)。它是一个正数,控制每次参数更新的步长。较小的学习率会导致收敛较慢,较大的学习率可能导致震荡或无法收敛。
momentum(默认值为 0): 动量(momentum)是一个用于加速 SGD 收敛的参数。它引入了上一步梯度的指数加权平均。通常设置在 0 到 1 之间。当 momentum 大于 0 时,算法在更新时会考虑之前的梯度,有助于加速收敛。
五.梯度缓存清除
在每个 epoch 开始之前,我们需要将优化器的梯度缓存清零,这样可以确保在后续的梯度计算中,梯度不会累积并导致不准确的权重更新。
默认情况下,PyTorch在调用 .backward() 时会累积梯度,而不是覆盖它们。每次调用 .backward() 时,梯度会被添加到缓冲区中,而不是被重置。这意味着如果不清零,梯度会在每个迭代中累积,导致不正确的梯度更新。















 2074
2074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









