






1、模型结构
class NeuralNet(nn.Module):
def __init__(self,dropout_p=0.3):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(4, 32)
self.BN1 = nn.BatchNorm1d(32)
self.fc2 = nn.Linear(32, 16)
self.dropout = nn.Dropout(p=dropout_p)
self.fc3 = nn.Linear(16, 3)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.BN1(x)
x = torch.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
调参实验
a组(只改学习率)、batchsize=128 epochs=25000 relu
dropout=0.4 ir=0.001 SGD weight_decay = 1e-8
ir=0.001 
ir=0.01
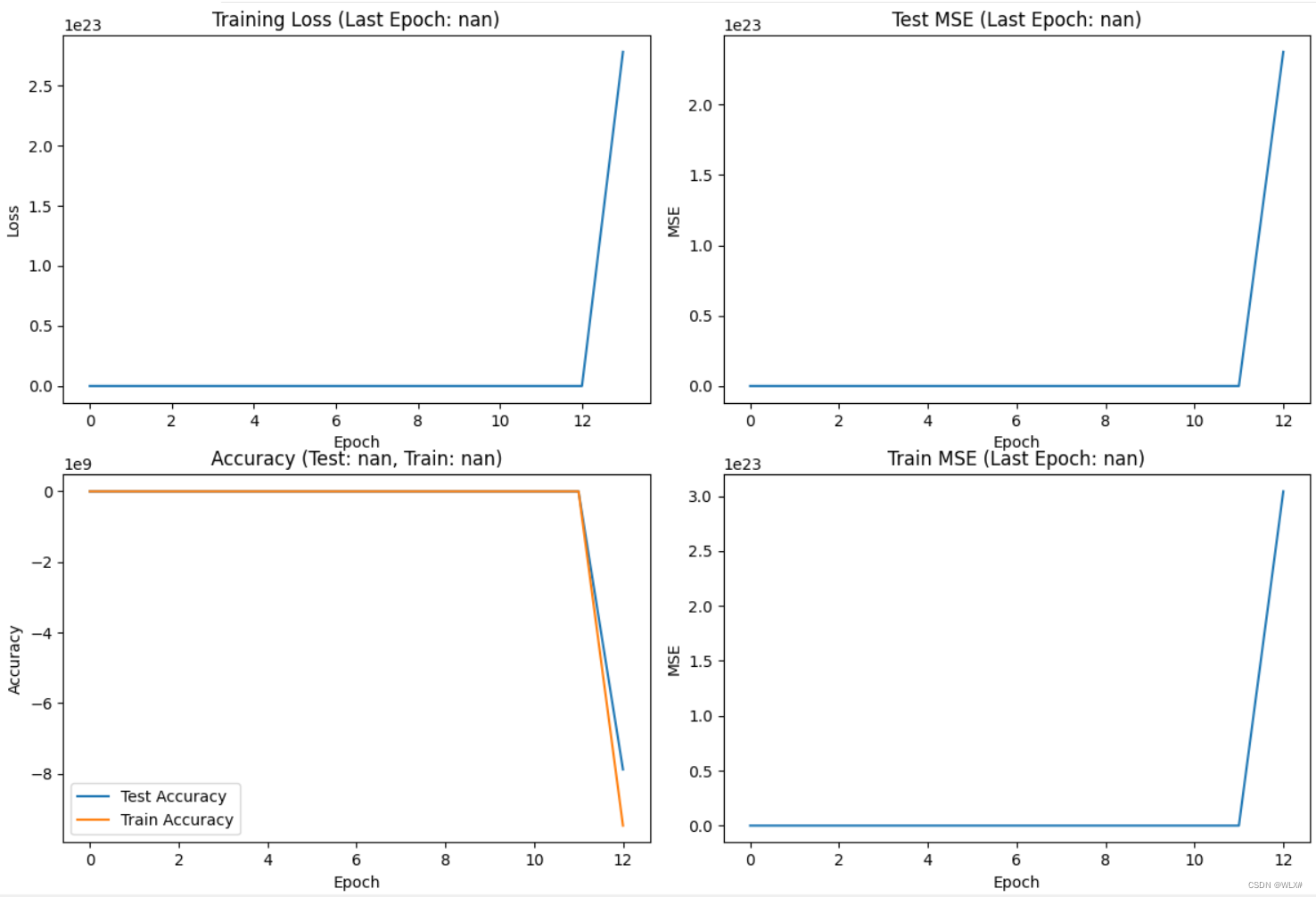
目前来看 学习率低一点较好 思路:尝试一下ir设置成0.0001
0.0001

此时MSE比较接近,但是Loss没有降下来
再试一下0.00001(不常见)
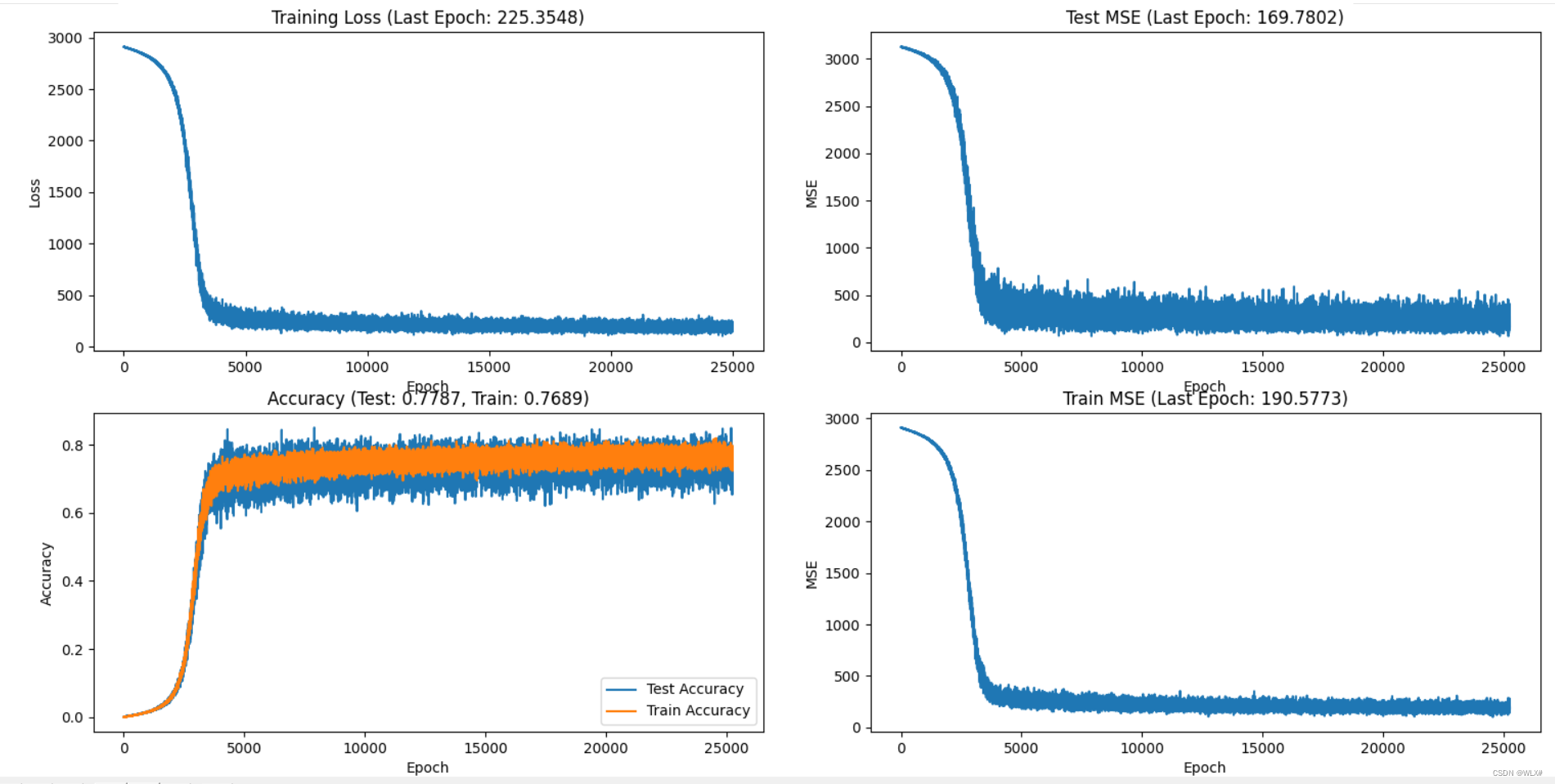
总结,训练更细腻(曲线圆滑),但是损失更高,因此,把ir设置成0.0001
b组(调整训练轮数)
ir=0.0001下 epochs=25000原始参数不变
20000:
效果不理想
加大ir 50000epochs
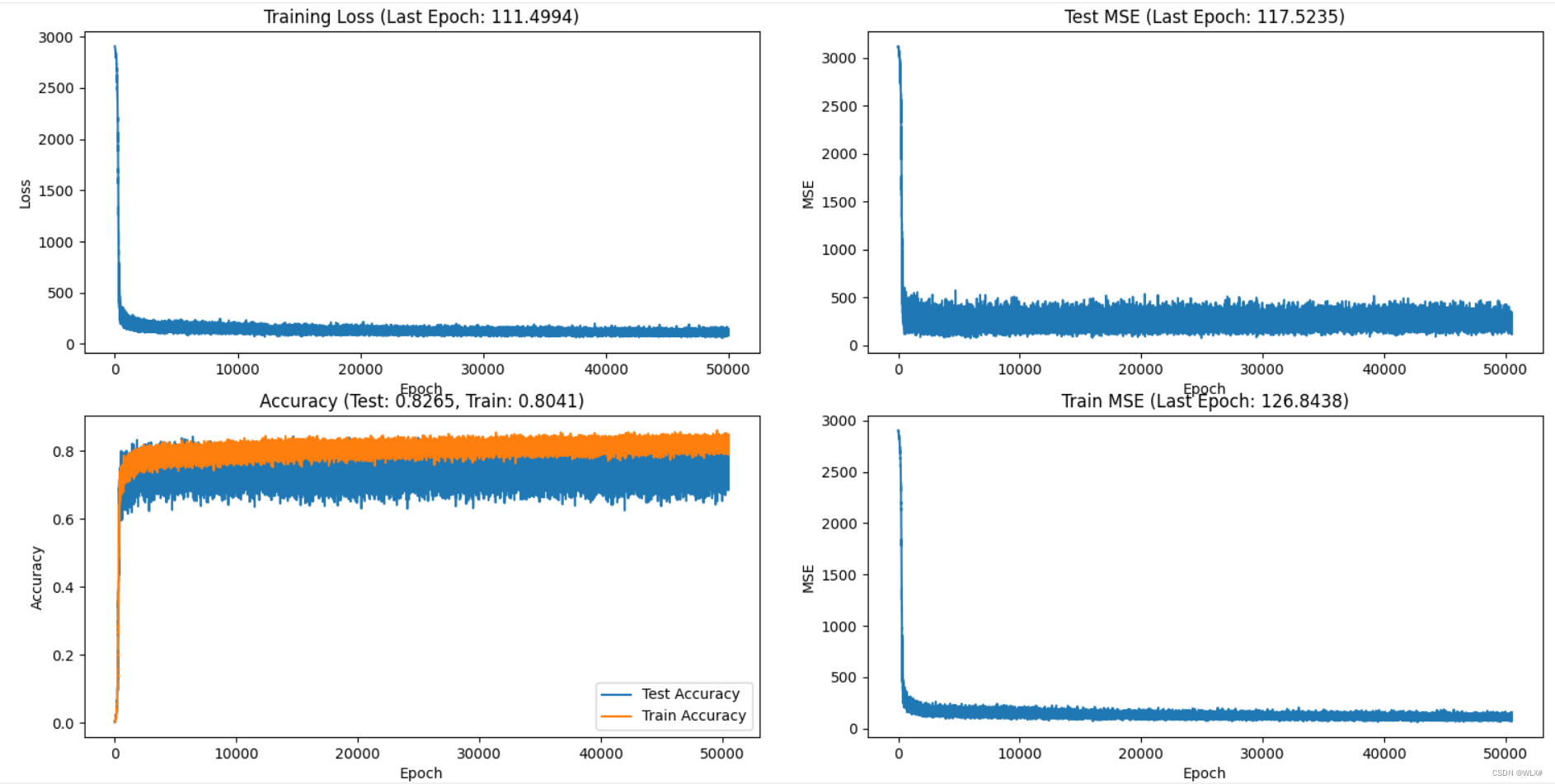
瞎搞一下、没耐心了 8000epochs dropout 0.5
















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









