






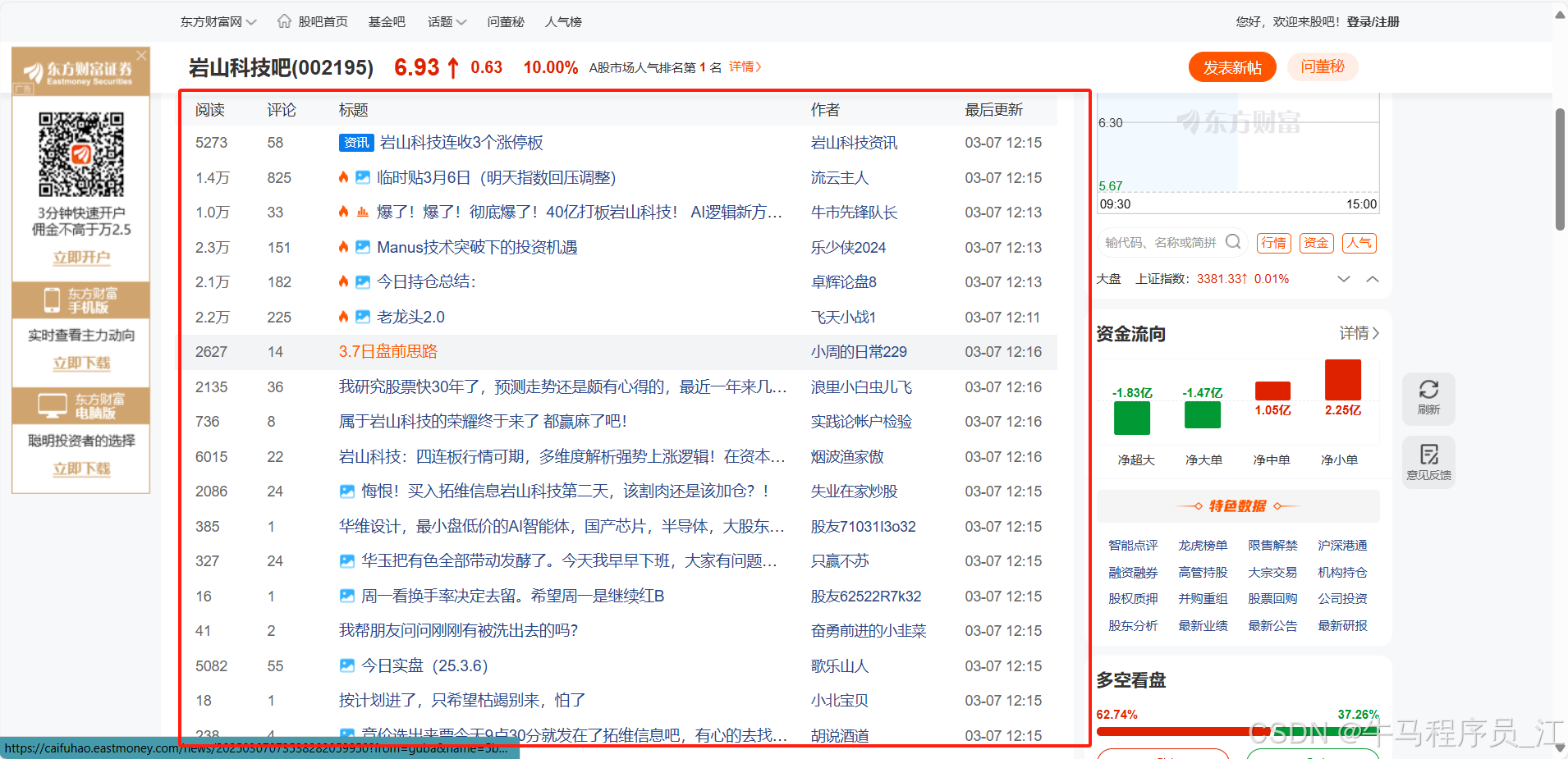
代码可多线程采集大量评论(千万级别),完整源码请私信有偿获取
# 技术博客:使用 Feapder 爬取东方财富股吧评论数据
## 引言
在数据分析和挖掘的过程中,获取高质量的数据是至关重要的。本文将介绍如何使用 `Feapder` 框架爬取东方财富股吧的评论数据,并将数据存储到 MySQL 数据库中。我们将详细讲解代码的各个部分,包括如何发送请求、解析 HTML 内容、处理 JSON 数据以及将数据存储到数据库中。
## 1. 环境准备
在开始之前,确保你已经安装了以下 Python 库:
```bash
pip install feapder fake_useragent mysqlclient
```
## 2. 代码解析
### 2.1 导入必要的库
```python
import time
from feapder.db.mysqldb import MysqlDB
from fake_useragent import UserAgent
import re
import json
from datetime import datetime
import feapder
```
• `feapder`:一个强大的 Python 爬虫框架,支持分布式爬取、任务调度等功能。
• `fake_useragent`:用于生成随机的 User-Agent,避免被网站反爬虫机制检测到。
• `re`:正则表达式库,用于从 HTML 中提取数据。
• `json`:用于解析 JSON 数据。
• `datetime`:用于处理日期和时间。
### 2.2 提取 JSON 数据
```python
def extract_article_list(html_content):
pattern = r'var\s+article_list\s*=\s*({.*?});'
match = re.search(pattern, html_content, re.DOTALL)
if match:
json_str = match.group(1)
try:
article_list = json.loads(json_str)
return article_list
except json.JSONDecodeError as e:
print(f"JSON 解析错误: {e}")
return None
else:
print("未找到 article_list 的 JSON 数据")
return None
```
该函数使用正则表达式从 HTML 内容中提取 `article_list` 的 JSON 数据。如果找到匹配的 JSON 数据,则将其解析为 Python 字典并返回;否则返回 `None`。
### 2.3 判断日期是否在指定范围内
```python
def is_between_2020_and_2025(date_str):
date = datetime.strptime(date_str, "%Y-%m-%d %H:%M:%S")
start_date = datetime(2020, 1, 1)
end_date = datetime(2025, 12, 31, 23, 59, 59)
return start_date <= date <= end_date
```
该函数用于判断给定的日期字符串是否在 2020 年到 2025 年之间。如果是,则返回 `True`;否则返回 `False`。
### 2.4 从文件中读取 ID 列表
```python
def read_ids_from_file(filename='id.txt'):
try:
with open(filename, 'r', encoding='utf-8') as file:
lines = [line.strip() for line in file.readlines() if line.strip()]
return lines
except FileNotFoundError:
print(f"错误:文件 '{filename}' 未找到。")
return []
except Exception as e:
print(f"读取文件时发生错误:{e}")
return []
```
该函数从指定的文件中读取 ID 列表,并返回一个包含每行内容的列表。如果文件不存在或读取时发生错误,则返回空列表。
### 2.5 爬虫类 `Guba`
```python
class Guba(feapder.AirSpider):
def start_requests(self):
ids = read_ids_from_file()
params = {
"": ""
}
for id in ids:
for i in range(1, 50):
link = f'https://guba.eastmoney.com/list,{id}_{i}.html'
print(link)
yield feapder.Request(link, params=params, method="GET", meta={"code": id})
def download_midware(self, request):
request.headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36",
"sec-ch-ua": "\"Chromium\";v=\"134\", \"Not:A-Brand\";v=\"24\", \"Google Chrome\";v=\"134\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
return request
def parse(self, request, response):
code = request.meta.get("code")
datas = []
json_data = extract_article_list(response.text)
items = json_data['re']
for item in items:
code = code
title = item['post_title']
try:
author = item['post_user']['user_nickname']
except:
author = item['user_nickname']
read_count = item['post_click_count']
comment_count = item['post_comment_count']
update_time = item['post_publish_time']
if is_between_2020_and_2025(date_str=update_time):
data = {
'code': code,
'title': title,
'author': author,
'read_count': read_count,
'comment_count': comment_count,
'update_time': update_time
}
print(data)
datas.append(data)
number = db.add_batch_smart(table='guba_comments', datas=datas)
print(f'本次写入{number}条数据')
time.sleep(2)
```
• `start_requests`:生成初始请求,从文件中读取 ID 列表,并构造请求 URL。
• `download_midware`:设置请求头,避免被反爬虫机制检测到。
• `parse`:解析响应内容,提取评论数据,并将数据存储到 MySQL 数据库中。
### 2.6 启动爬虫
```python
if __name__ == "__main__":
Guba(thread_count=1).start()
```
在 `__main__` 中启动爬虫,设置线程数为 1。
## 3. 运行结果
运行代码后,爬虫将开始爬取东方财富股吧的评论数据,并将数据存储到 MySQL 数据库中。每次写入数据后,程序会暂停 2 秒,以避免对服务器造成过大压力。



















 7101
7101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











