




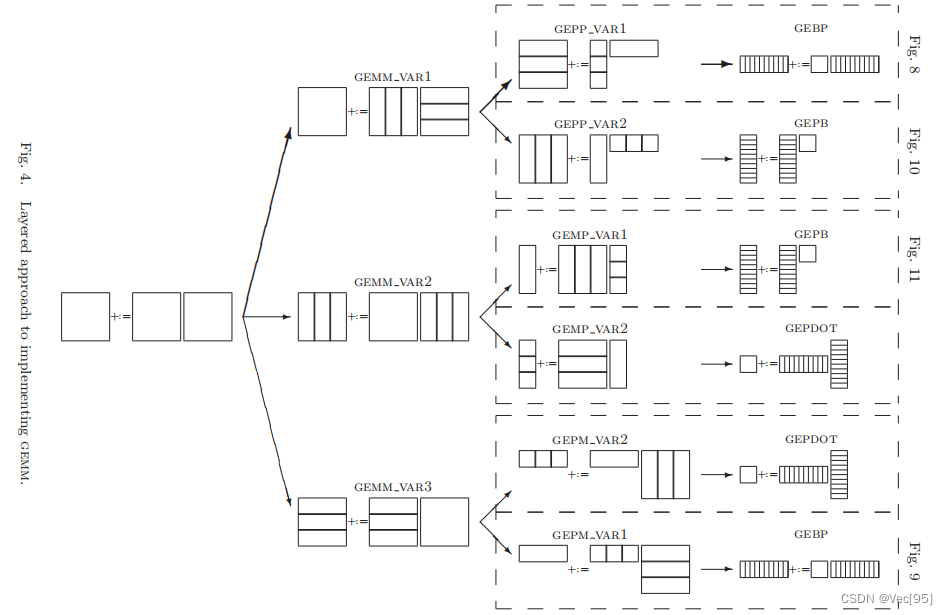
从上图中我们可以看到三种处理方法。第一种是将A和B矩阵分块(竖切和横切),第二种方法是将C和B矩阵分块(竖切和竖切),第三种方法是将C和A矩阵分块(横切和横切):

GEMM的子任务是GEPP或GEMP;最小粒度的任务是GEBP或GEPB或点乘。
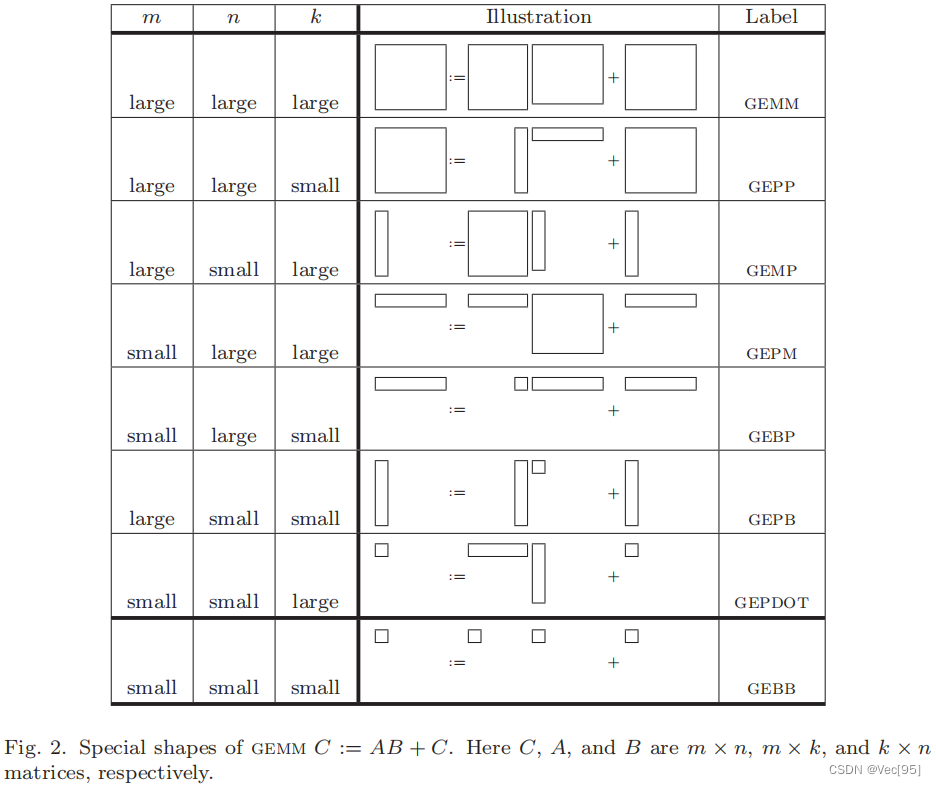

这里面M表示横向和纵向维度都很大的矩阵,P表示横向或纵向有一个维度很小的矩阵(或者就是一个向量),B表示横向和纵向维度都很大的矩阵(或者就是只有一个元素的矩阵或向量)。
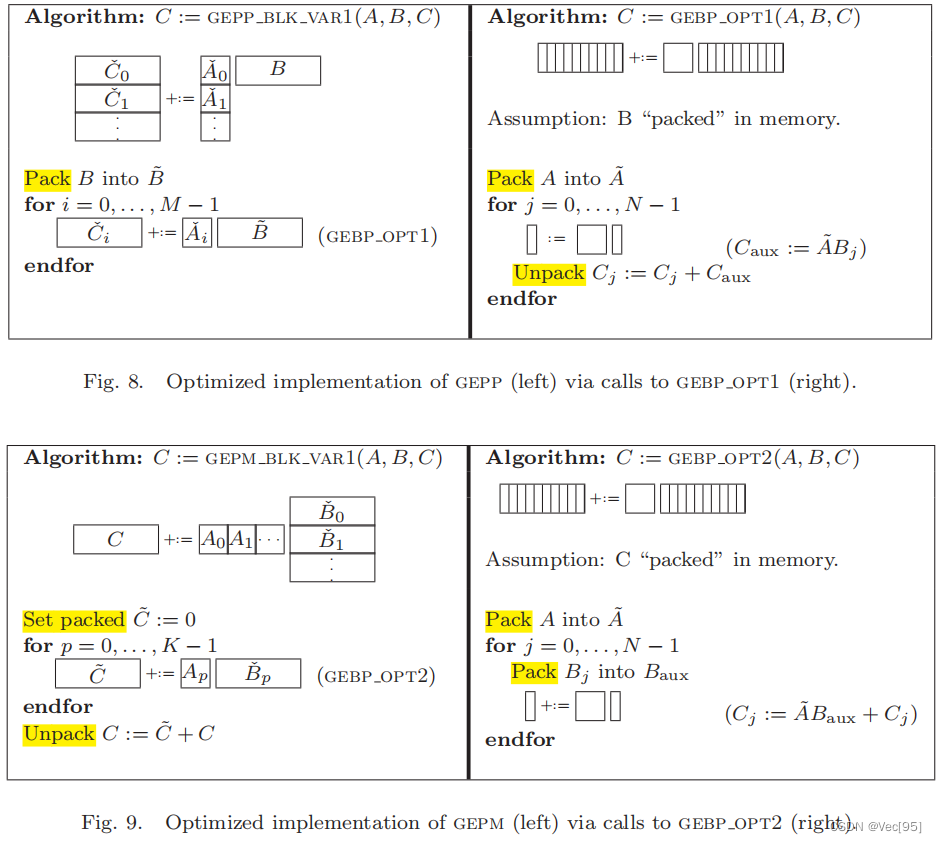
其各自计算方法大致如下:
对于内存和线程结构:
 文章详细介绍了GEMM(GeneralMatrixMultiply)操作的优化方法,包括矩阵的分块处理(如A和B的竖切和横切),以及如何通过线程块和CUDA架构提高计算效率。关键在于将矩阵乘法转换为向量乘法,通过块点乘提升运算访存比,优化内存访问和计算性能。文章还讨论了不同级别的BLAS操作和矩阵划分策略。
文章详细介绍了GEMM(GeneralMatrixMultiply)操作的优化方法,包括矩阵的分块处理(如A和B的竖切和横切),以及如何通过线程块和CUDA架构提高计算效率。关键在于将矩阵乘法转换为向量乘法,通过块点乘提升运算访存比,优化内存访问和计算性能。文章还讨论了不同级别的BLAS操作和矩阵划分策略。
从上图中我们可以看到三种处理方法。第一种是将A和B矩阵分块(竖切和横切),第二种方法是将C和B矩阵分块(竖切和竖切),第三种方法是将C和A矩阵分块(横切和横切):
GEMM的子任务是GEPP或GEMP;最小粒度的任务是GEBP或GEPB或点乘。
这里面M表示横向和纵向维度都很大的矩阵,P表示横向或纵向有一个维度很小的矩阵(或者就是一个向量),B表示横向和纵向维度都很大的矩阵(或者就是只有一个元素的矩阵或向量)。
其各自计算方法大致如下:
对于内存和线程结构:
 712
738
712
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























