








阅读文章之前请温习以下四篇文章,避免云里雾里:
轻松读懂FlashAttention上<矩阵分块加载,改写softmax算法>
轻松读懂FlashAttention-2<优化循环体,减少非矩阵运算>
GPU的基础认知<GEMM是最佳的选择!最好都改写为矩阵运算!>

加速Hopper GPU
注意力机制是Transformer架构的核心能力,也是大型语言模型和长上下文应用的瓶颈。FlashAttention(和 FlashAttention-2)开创了一种通过最小化内存读/写来加速 GPU 注意力的方法,现在大多数库都使用它来加速 Transformer 训练和推理。
这导致了过去两年上下文LLM长度的大幅增加,从2-4K(GPT-3,OPT)增加到128K(GPT-4),甚至1M(Llama 3)。然而,尽管取得了成功,但 FlashAttention 尚未利用现代硬件中的新功能,FlashAttention-2在H100 GPU上仅实现了35%的理论最大FLOP 利用率。
在这篇博文中介绍了三种主要技术来加快对Hopper GPU的关注:利用 Tensor Core和TMA的异步性。
1) 通过扭曲专业化重叠整体计算和数据移动
2)交错块matmul和softmax操作
3)利用硬件支持实现 FP8 低精度的非连贯处理

快速了解
FlashAttention-3比使用FP16的FlashAttention-2快1.5-2.0倍,高达740 TFLOPS,即H100理论最大FLOPS利用率为 75%。使用FP8时,FlashAttention-3达到接近 1.2 PFLOPS,误差比基线FP8注意小2.6倍。
-
更高效的GPU利用率:新技术可利用高达75%的H100 GPU最大功能,而之前仅为35%。这导致在训练和运行大型语言模型方面,比以前的版本快得多(1.5-2 倍LLMs)。
-
以较低的精度获得更好的性能:FlashAttention-3可以处理精度较低的数字FP8,同时保持精度。这样可以实现更快的处理速度,并可能降低内存使用率,从而为运行大规模AI操作的客户节省成本并提高效率。
-
能够在以下位置LLMs使用更长的上下文:通过加速注意力机制,FlashAttention-3使AI模型能够更有效地处理更长的文本片段。这可以使应用程序能够在不减慢速度的情况下理解和生成更长、更复杂的内容。

GEMM和SOFTMAX
注意力有两个主要操作GEMMs(GEMMs是指广义矩阵乘法General Matrix Multiply),例如注意力机制中Q和K之间以及注意力矩阵P和V之间的矩阵乘法。
GPU上面现代加速器上,非matmul操作比matmul操作慢得多。例如softmax中的指数运算等特殊函数的吞吐量远远低于浮点乘加。这些特殊运算(函数)SF一般是由多功能(计算)单元负责,多功能(计算)单元是独立于浮点乘-加(例如y=wx+b)或矩阵乘加之外。
例如,H100 GPU SXM5具有989TFLOPS的FP16矩阵乘法,但对于特殊的函数SF,只有 3.9TFLOPS的吞吐,吞吐量低 256 倍。
CUDA 编程指南规定,特殊函数的吞吐量为每个时钟周期每个流式多处理器 (SM) 16次操作。将16乘以132SM和1830 Mhz(用于计算 FP16 matmul 的989TFLOPS 的时钟速度)得到 3.9TFLOPS!
假如注意力机制的head维度为128,matmul FLOPS比指数运算多512倍,这意味着与matmul运算相比,花费在指数运算的时间需要比矩阵运算多50%的时间。Matmul在FP8的精度下速度比FP16还要快多两倍,这样一来就被指数运算严重的拖后腿!能有魔法棒实现两者并行么?
上面文绉绉的话翻译成白话就是:GEMM比Softmax快,如何让两者并驾齐驱?
Warp是SM中的基本概念,可以先回去温习下GPU的组成。Warp其实已经做了一些调度的事宜,某些Warp被阻塞,其他翘曲可以运行。
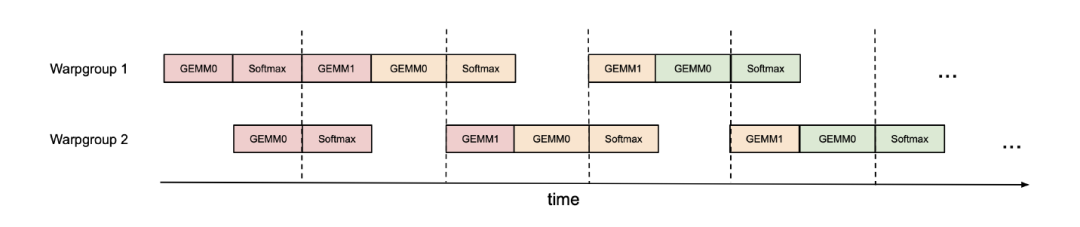
例如存在 2个warpgroup(标记为 1 和 2),每个warpgroup是4个warp 的组),这时候通过使用同步屏障 (bar.sync),以便warpgroup 1首先执行它的GEMM。例如,一次迭代的GEMM1和下一次迭代的 GEMM0。然后warpgroup 2执行它的GEMM,而warpgroup 1执行它的softmax, 等等。这个类似乒乓球的调度方式,确保了两者并驾齐驱。上图相同颜色的为相同的迭代。
这种方式在实践中,调度并不是真的这么妥帖,但是这样的调度可以将 FP16 注意力前向传递从大约 570 TFLOPS提高到620 TFLOPS(头部head 128维,序列长度8K)。
即使在一个Warpgroup中,可以在这个群组运行GEMM的时候运行softmax的某些部分。如下图所示:
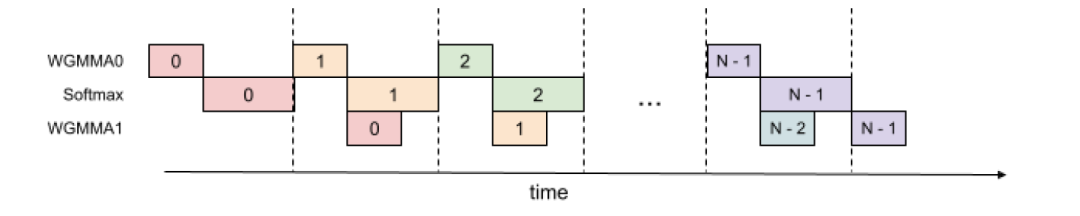
<非工科读者跳过!>具体的原理在于在注意力算法中,内部循环(主循环)内的操作具有顺序依赖性,这些依赖性会阻碍单次迭代中的并行化。例如,(本地)softmax 18-19行依赖于第一个 GEMM 的输出,而第二个 GEMM 将其结果作为操作数。实际上,算法 1 的第 17- 21行中的等待语句序列化了softmax 和GEMM的执行。但是可以通过寄存器中的额外缓冲区在迭代之间流水线来打破这些依赖关系。遵循这一思路,FL3提出了以下两阶段GEMM-softmax流水线算法:


<继续>这种流水线将吞吐量从大约620 TFLOPS提高到大约640-660 TFLOPS,用于FP16注意力向前转移,但代价是更高的寄存器压力,因为需要更多的寄存器来容纳GEMM的累加器和softmax的输入/输出。
扩展上述 2 阶段算法,FL3继续提出了一个3阶段变体,该变体将进一步重叠第二个WGMMA与softmax。虽然这种方法提供了更高的 Tensor Core 利用率的潜力,但它需要更多的寄存器。

FP8的量化支持

FP8和FP32在寄存器中的存储布局的不一致给FL3的算法带来了挑战。
对于 FP8 FlashAttention-3, 𝐕在将分片加载到SMEM后进行内核内转置。对于内核内转置,我们利用了LDSM ( ldmatrix ) 和STSM ( stmatrix )指令,它们涉及一系列线程共同加载 SMEM到RMEM,并以 128 字节的粒度存储 RMEM 到 SMEM。
LDSM/STSM指令都是高效的,允许在warpgroup中执行,并且能够在执行内存复制时转置布局。在第一次迭代之后,可以在前一个𝐕切片和当前 𝐊切片的WGMMA运算中,加入下一个𝐕切片的转置。
使用 FP8 (e4m3) 格式,仅使用3位来存储尾数,使用4位来存储指数。这导致比FP16/BF16更高的数值误差。此外,大型模型通常具有异常值,它的量级比大多数其他值大得多,这使得量化变得困难。为了减少 FP8中注意力机制的误差,FL3采用了两种技术:
-
块量化:为每个块保留一个标量,以便对于每个Q,K,V 将其张量拆分为大小𝐵𝑟×𝑑 𝐵𝑐×𝑑 块,然后独立量化。这种量化可以与注意力之前的操作融合,而不会额外减慢速度。由于FlashAttention-3算法都是基于快进行计算,因此可以缩放每个S块进行量化,而无需计算成本。
-
利用QuIP的非相干处理,将Q和K与随机正交矩阵相乘,以“分散”异常值并减少量化误差。<不明白可以跳过,后面专栏介绍这种算法>。
在实验中,Q、K、V是由标准正态分布生成的,但0.1%的条目具有较大的量级(模拟异常值),我们发现非相干处理可以将量化误差减少 2.6倍。下表为数值误差比较。


性能对比
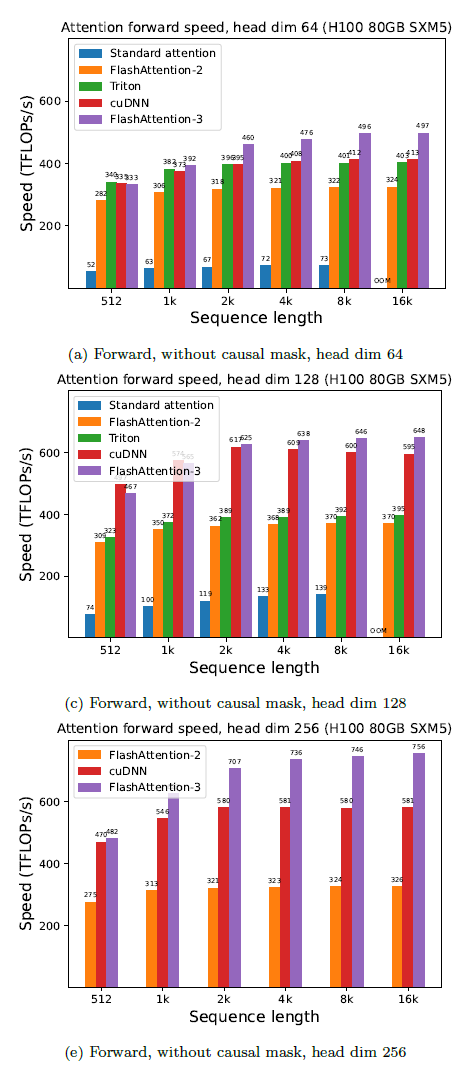
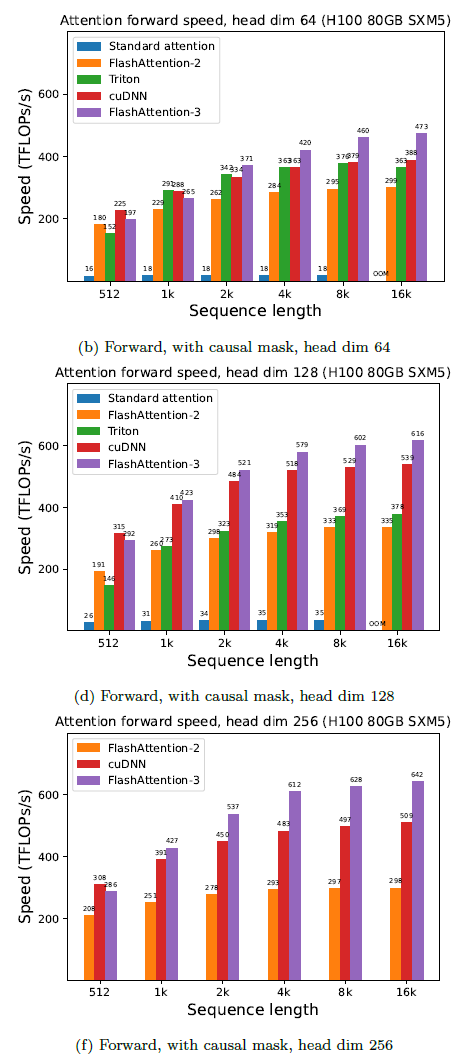
下面展示了FlashAttention-3的一些结果,并将其与FlashAttention-2以及 Triton和cuDNN中的实现进行了比较(两者都已经使用了Hopper GPU 的新硬件功能)。对于FP16,FlashAttention-2的加速约为1.6倍至 2.0倍。















 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









