







一、背景意义
猫咪作为广泛受欢迎的宠物,相关研究可以引起广泛的社会关注,同时也可以促进人们对于动物保护和关爱的认识。深度学习在图像分类领域取得了显著的成就,对于动物的分类也有广泛的应用。针对猫咪这一常见的宠物动物,构建猫咪分类数据集可以为深度学习项目提供丰富的训练样本。猫咪作为人类日常生活中的重要伴侣动物,其种类繁多,外貌特征各异,因此对其进行准确分类具有重要意义。通过深度学习模型对猫咪进行分类,可以为宠物饲养提供指导,帮助兽医识别不同种类的猫咪,提供更好的医疗保健服务。研究猫咪分类数据集可以促进图像识别技术在动物分类领域的应用,推动深度学习算法在实际场景中的应用和发展。
二、数据集
2.1数据采集
在收集到大量猫咪图像数据后,对这些原始数据进行了精心的清洗和筛选。首先,通过去除低质量图片,包括模糊、分辨率过低或存在其他物体干扰的图片,确保每张图片都清晰展示猫咪的特征,从而提高数据的质量和可用性。这一步骤是关键的,因为只有高质量的图片才能有效地帮助深度学习模型准确地学习和识别目标。
其次,进行了统一格式的处理,将所有图片转换为JPEG格式,并统一调整每张图片的分辨率为256x256像素。这样的处理不仅有助于减少后续训练过程中的图像处理复杂度,也确保了数据集的一致性和规范性。通过统一格式和分辨率,可以更方便地进行数据处理和模型训练,提高整个数据集的可管理性和可用性。
最后,对图像数据进行了分类整理。将所有图片按照猫咪的不同类别进行分类,分门别类地放入对应的文件夹中。每个类别的文件夹下只包含对应类别的图片,避免数据集混乱和混杂。这种分类整理的方式有助于保持数据集的结构清晰,方便后续的数据管理和模型训练,确保数据的有序性和可用性。通过这些清洗和整理工作,构建了高质量、规范化的猫咪图像数据集,为后续的深度学习模型训练提供了坚实的基础。
2.2数据标注
在标注猫咪数据集时,我选择了使用LabelImg这一功能强大的标注工具,以解决数据集中的复杂性和庞大的工作量。该数据集主要包含以下分类:猫咪(cat):
- 选择使用LabelImg标注工具处理猫咪数据集。
- 确定数据集分类为猫咪(cat)。
- 面对复杂场景和大量图像,保持专注和耐心。
- 使用LabelImg绘制边界框、添加标签,快速导航和编辑图像。
- 处理猫咪重叠、姿势变化和不同背景下的情况。
- 确保每只猫咪准确标注,保持标注的一致性和准确性。
- 完成整个数据集的标注任务,提升数据质量和可用性。
- 为深度学习模型训练提供重要支持。

包含1159张猫咪图片,数据集中包含以下几种类别
- 猫:家养动物,常见的哺乳动物,通常被人类作为宠物饲养,具有灵活的身体和独特的咪咪叫声。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 图像清洗:对采集到的图像进行去噪处理,去除不必要的背景信息,确保图像质量。
- 图像裁剪:根据需要,对图像进行裁剪和调整大小,使其符合模型训练的要求。
- 数据增强:可以应用数据增强技术,如翻转、旋转、缩放等,增加数据样本的多样性和数量,提高模型的泛化能力。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
在深度学习中,适合用于猫咪图像检测的算法之一是目标检测中的卷积神经网络(Convolutional Neural Network,CNN)。CNN在计算机视觉任务中表现出色,特别适用于目标检测任务,包括猫咪的检测。卷积神经网络是一种专门设计用于处理具有类似网格结构的数据,如图像和视频的深度学习架构。CNN通过卷积层、池化层和全连接层等组件来学习图像的特征并进行分类或定位。
CNN的原理基于以下几个核心组件:
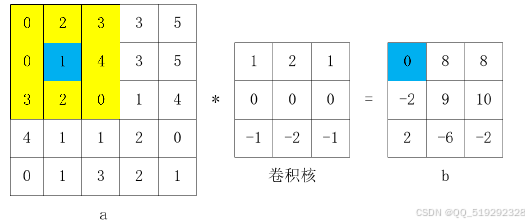
- 卷积层:卷积操作通过滤波器在输入图像上进行滑动,提取局部特征。滤波器的权重参数通过训练学习,用于检测不同特征,如边缘、纹理等。卷积操作可以保留空间结构信息,减少参数数量,提高模型的效率。
- 池化层:池化操作用于降采样,减小特征图的尺寸,保留主要特征。常见的池化方式包括最大池化(Max Pooling)和平均池化(Average Pooling)。池化层有助于减少模型对位置的敏感性,提高模型的鲁棒性。
- 激活函数:激活函数引入非线性,使得神经网络可以学习复杂的模式。常用的激活函数包括ReLU、Sigmoid和Tanh。
- 全连接层:全连接层将卷积层和池化层提取的特征进行展平,并连接到输出层。输出层通常采用Softmax函数进行分类,或直接输出预测结果。
- 反向传播算法:CNN通过反向传播算法更新网络参数,使得模型预测结果与实际标签更加接近。通过梯度下降等优化算法,调整网络参数以最小化损失函数。
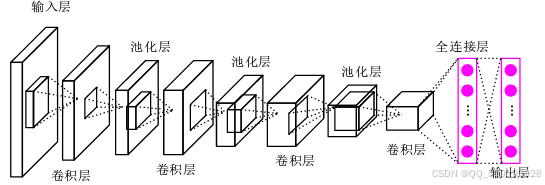
卷积神经网络(CNN)在猫咪图像检测中的适用性体现在几个关键方面。首先,CNN能够通过层层学习提取图像中的抽象特征,包括边缘、纹理和形状等,这对于准确检测猫咪的位置至关重要。其次,CNN具有空间层次结构,能够有效捕捉图像不同区域的特征,对于具有特定形态和特征的猫咪目标尤为有效。此外,CNN对于大规模数据集的训练效果显著,而猫咪数据集通常需要大量样本来训练有效的检测模型,CNN能够充分利用这些数据提高模型的准确性和泛化能力。
3.2模型训练
开发一个基于YOLO(You Only Look Once)算法的猫咪图像识别项目可以分为以下几个步骤。每个步骤都会配有示例代码,帮助你更好地理解和实现。
在开始之前,确保你的开发环境安装了所需的库和工具。通常需要安装Python、OpenCV、NumPy、TensorFlow或PyTorch等库。
# 安装必要的库
pip install opencv-python numpy tensorflow
在准备好猫咪图像识别数据集后,通常将数据集划分为训练集、验证集和测试集。以下是一个简单的示例代码,用于划分数据集。
import os
import shutil
import random
def split_dataset(dataset_dir, train_dir, val_dir, test_dir, train_ratio=0.7, val_ratio=0.2):
# 创建目标目录
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
images = [f for f in os.listdir(dataset_dir) if f.endswith('.jpg')] # 假设数据集是jpg格式
random.shuffle(images)
total_images = len(images)
train_count = int(total_images * train_ratio)
val_count = int(total_images * val_ratio)
# 复制文件到相应目录
for i, img in enumerate(images):
src = os.path.join(dataset_dir, img)
if i < train_count:
shutil.copy(src, train_dir)
elif i < train_count + val_count:
shutil.copy(src, val_dir)
else:
shutil.copy(src, test_dir)
# 示例调用
split_dataset('path/to/dataset', 'path/to/train', 'path/to/val', 'path/to/test')
YOLO需要图像的标注文件,每个标注文件包含每个目标的位置和类别。以下是一个示例代码,演示如何将标注信息保存为YOLO格式。
import cv2
def create_yolo_annotation(image_path, label, bbox):
# bbox格式为[x_center, y_center, width, height],均为相对坐标
img = cv2.imread(image_path)
height, width, _ = img.shape
x_center, y_center, w, h = bbox
# 转换为YOLO格式
yolo_format = f"{label} {x_center/width} {y_center/height} {w/width} {h/height}\n"
return yolo_format
# 示例调用
annotation = create_yolo_annotation('path/to/image.jpg', 0, [0.5, 0.5, 0.2, 0.2])
with open('path/to/annotation.txt', 'a') as f:
f.write(annotation)
在YOLOv5中,模型配置涉及多个关键参数,以确保网络有效训练和推理。其中包括指定训练集和验证集的路径,以便加载图像和标注文件;定义类别数,通常对于猫咪图像识别设为1;列出类别名称以便在推理时识别目标;以及调整超参数,如学习率、批量大小和图像尺寸,以优化模型性能。
# yolov5/data/cats.yaml
train: path/to/train # 训练集路径
val: path/to/val # 验证集路径
nc: 1 # 类别数
names: ['cat'] # 类别名称
使用YOLO框架(如YOLOv5)进行模型训练是构建图像识别系统的关键步骤。在开始训练之前,确保数据集已经准备妥当,并且配置文件正确无误。YOLOv5提供了一种直观的命令行接口,使得训练过程简单易行。
# 使用YOLOv5进行训练
!python train.py --img 640 --batch 16 --epochs 50 --data cats.yaml --weights yolov5s.pt
训练完成后,评估模型的性能,查看准确率、召回率和F1分数等指标。
import torch
# 加载训练好的模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt')
# 进行评估
results = model.val()
print(results)
使用训练好的模型进行推理,并可视化结果。以下是示例代码。
import cv2
def detect_objects(image_path):
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt')
# 读取图像
img = cv2.imread(image_path)
# 进行推理
results = model(img)
# 可视化结果
results.show()
# 示例调用
detect_objects('path/to/test/image.jpg')
最后,将训练好的模型部署到应用程序中,或者将其集成到实时监测系统中。
# 假设使用Flask进行简单的Web部署
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
file = request.files['file']
img_path = f'temp/{file.filename}'
file.save(img_path)
# 调用推理函数
results = detect_objects(img_path)
return jsonify(results)
if __name__ == '__main__':
app.run(debug=True)
四、总结
猫咪识别数据集是专为深度学习和计算机视觉研究而设计的,旨在促进猫咪图像分类和识别技术的发展。该数据集包含多种猫咪品种的图像,每张图像均配有详细的标注信息,涵盖了不同的姿态、颜色和背景,使其成为训练卷积神经网络(CNN)和YOLO等模型的理想选择。通过使用猫咪识别数据集,研究人员可以探索图像处理、特征提取和智能识别等技术,推动相关领域的创新与发展。

















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









