









论文链接:Visual Instruction Tuning![]() https://arxiv.org/pdf/2304.08485
https://arxiv.org/pdf/2304.08485
1. LLaVA简介:
LLaVA的模型架构基于CLIP(Contrastive Language-Image Pre-training)的视觉编码器和LLaMA(一个开源的大语言模型)的语言解码器。通过将这两个强大的模型连接起来,LLaVA能够在视觉和语言两个维度上进行高效的信息处理与融合。具体来说,CLIP的视觉编码器负责提取图像中的视觉特征,而LLaMA的语言解码器则负责理解和生成自然语言文本。通过端到端的微调,LLaVA能够学会如何将视觉特征转换为语言描述,实现视觉与语言的双向交互。
2. LLaVA的相关背景
2023年的时候,自然语言处理(NLP)领域有一个很大的进步,就是“指令微调”。最典型的就是GPT,它可以通过指令微调来更好地理解人类的语言指令。简单来说,就是给模型一些指令和对应的答案,让模型学会怎么根据指令来回答问题。但是,这种指令微调在“图像和文本”的多模态任务里还没有被应用,因为这种任务需要同时处理图像和文字,而相关的指令微调数据很少。
在2023年,有一个很厉害的多模态大语言模型叫BLIP-2。它虽然很强,但在视觉问答(VQA)任务中有一个缺点:它没有上下文学习能力。也就是说,它只能理解单个图像和对应的文本,而不能理解图像和文本之间的上下文关系。举个例子,假设有一系列图像和文本,图像a和文本a、图像b和文本b、图像c和文本c。BLIP-2在处理这些图像和文本时,是独立地处理每个图像和对应的文本。也就是说:当处理图像A和文本A时,BLIP-2只关注图像A和文本A之间的关系,不会考虑其他图像和文本。当处理图像B和文本B时,BLIP-2只关注图像B和文本B之间的关系,不会考虑图像A和文本A,也不会考虑图像C和文本C。当处理图像C和文本C时,BLIP-2只关注图像C和文本C之间的关系,不会考虑图像A和文本A,也不会考虑图像B和文本B。
而在复杂的多模态任务中,比如处理一系列相关的图像和文本,模型需要能够理解这些图像和文本之间的关系。例如:
-
图像A:一只猫在草地上玩耍。
-
图像B:一只狗在公园里跑步。
-
图像C:一只猫和一只狗在公园里玩耍。
如果模型能够利用上下文信息,它可能会更好地理解图像C中的猫和狗与图像A和图像B中的猫和狗之间的关系。例如,它可能会意识到图像C中的猫和狗可能是图像A和图像B中的猫和狗的组合。
LLaVA的作者就想解决这个问题,他们想构造一个“上下文学习的场景”,让多模态大语言模型能够学习到图像和文本之间的上下文关系。具体怎么做呢?当时ChatGPT已经出来了,作者就利用ChatGPT来生成这种上下文学习的数据。他们把图像的描述(Caption)和标注框(Bounding Box)交给ChatGPT,通过Prompt让ChatGPT生成一系列从简单到复杂的问答对。这些问答对可以帮助模型学习到图像和文本之间的上下文关系。需要注意的是,作者并没有把图像本身交给ChatGPT,只是把图像的描述和标注框交给它。
下图是图像的描述(Caption)和标注框(Bounding Box),语言模型通过这些数据为基础来扩充数据集,生成一系列从简单到复杂的问答对。

下图是ChatGPT生成的一系列从简单到复杂的问答对 ,分为对话、详细描述以及复杂推理(结合之前的对话和详细描述)。


以上的问答对是作者通过恰当的Prompt让ChatGPT生成的。那么如何设置Prompt?以下是论文中给出的例子,这个prompt是一个用于训练或测试AI助手的模板,它指导AI助手如何根据图片内容与用户进行对话。通过这种方式,AI助手可以学习如何更好地理解和回答关于视觉内容的问题。


更多关于数据集构成及数据收集细节,可以查看该链接中的内容【多模态大模型】llava系列:llava、llava1.5、llava-next
3. LLaVa的应用场景
然后我们再来看一下LLaVA的应用场景,了解它可以用来做什么。
-
图像理解与描述:LLaVA能够分析图像内容,并生成详细的描述性文本。这一功能在图像搜索、内容审核等领域具有广泛的应用前景。例如,在电商平台上,LLaVA可以帮助用户快速找到符合描述的商品图片;在社交媒体上,它可以自动为用户上传的图片添加标签和描述。
-
视觉问答与推理:通过结合视觉与语言理解能力,LLaVA能够回答关于图像的问题,并进行复杂的推理。这一功能在医疗影像分析、法律文件审查等领域具有重要价值。例如,在医疗领域,医生可以利用LLaVA快速获取影像报告的关键信息;在法律领域,律师可以使用LLaVA辅助审查案件相关的图像证据。
-
跨模态创作与生成:LLaVA还具备跨模态创作与生成的能力。它可以根据用户的文字描述生成相应的图像,或者根据图像生成相关的文字描述。这一功能在艺术创作、广告设计等领域具有广泛的应用潜力。例如,艺术家可以利用LLaVA快速生成创作灵感;广告商可以使用LLaVA生成更具吸引力的广告文案和图片。
4. LLaVA的网络结构
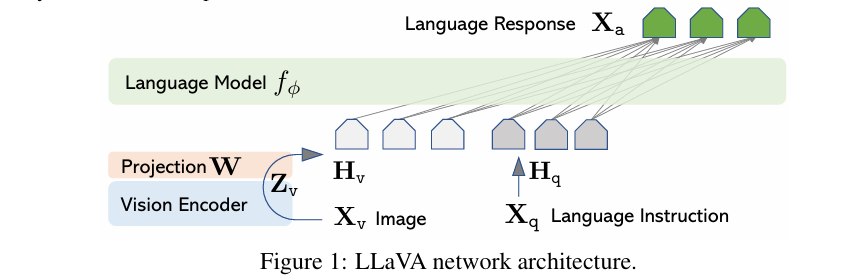
LLaVA 主要由三部分构成,也就是上图中的:视觉编码器(Vision Encoder)、对齐层(Projection,直翻是“投影层”)、语言模型(Language Model)。LLaVA模型的架构,是将一个预训练的视觉编码器(CLIP ViT-L/14)与一个大规模语言模型(Vicuna)连接在一起。
- 视觉编码器(Vision Encoder): LLaVa 架构的视觉部分是预训练的 CLIP 视觉编码器,具体来说是 ViT-L/14 变体。该组件通过 Transformer 层处理输入图像 (Xv) 以提取特征 (Zv),使模型能够有效地理解视觉信息。
- ViT-L/14是CLIP(Contrastive Language-Image Pre-training)模型的一个变体,它采用了Vision Transformer(ViT)架构,具有强大的图像编码能力。"L"代表模型的规模,为“Large”,表示这是一个大型模型,通常有24层Transformer。"14"表示每个patch的分辨率为14X14,例如在224x224像素的图像上,总共有
(224 / 14) x (224 / 14) = 16 x 16 = 256个patch。ViT模型将输入图像分割成固定大小的patch(例如14x14),ViT-L/14即表示patch大小为14。这种模型在处理大规模数据时,能够更好地捕捉图像的全局特征,从而提高分类的准确性和效率。
- ViT-L/14是CLIP(Contrastive Language-Image Pre-training)模型的一个变体,它采用了Vision Transformer(ViT)架构,具有强大的图像编码能力。"L"代表模型的规模,为“Large”,表示这是一个大型模型,通常有24层Transformer。"14"表示每个patch的分辨率为14X14,例如在224x224像素的图像上,总共有
- 对齐层(Projection W): 视觉编码器输出的特征向量(Zv)需要被转换成语言模型能够理解的形式。这是通过一个投影矩阵(W)实现的,它将视觉特征映射到与语言模型的词嵌入空间相同的维度,生成视觉特征的表示(Hv)。
- 语言模型: 主要是 LLaMA文本模型,LLaVa 的语言能力依赖于 Vicuna,它是大型语言模型 (LLM) 的一种。负责处理语言指令(Xq)和生成语言响应(Xa)。语言模型接收视觉特征的表示(Hv)和语言指令(Hq),并生成相应的语言输出。
- Vicuna和LLaMA是什么关系?Vicuna是基于LLaMA模型进行微调的版本。LLaMA(Large Language Model Family of AI)是一种基于Transformer架构的大规模语言模型,具有强大的自然语言处理能力,能够在对话系统、文本生成、情感分析等多个领域发挥重要作用。然而,对于特定任务,通常需要对模型进行微调以提升性能。Vicuna通过这种微调方式,能够更好地理解并执行特定任务,如文本生成、问答、文本分类等自然语言处理任务,进一步提升了模型的实用性和灵活性。Vicuna是由UC伯克利团队开发的,通过对LLaMA模型进行指令微调,使得模型在保持通用性的同时,更加注重任务的适应性。
综上所述, Xv 为输入图像,而 Xq 为输入文本指令。 Xv 经过冻结的预训练视觉编码器(例如CLIP的视觉编码器)转换为视觉特征: Zv=g(Xv) , Zv 又进一步经过一个简单的线性层 W 转换为文本特征: Hv=W⋅Zv ,便可和文本指令特征 Hq 一起送入LLM进行处理,语言模型根据这些输入生成语言响应(Xa),这个响应是对用户指令的文本回答。
5. LLaVA两阶段训练
5.1 Stage 1: Pre-training for Feature Alignment 特征对齐预训练
目标: 这一阶段的主要目标是将视觉特征与语言模型的嵌入空间对齐。这意味着要确保图像的视觉表示(通过视觉编码器提取)能够与语言模型处理的文本信息在同一个特征空间中有效交互。
过程:
-
数据准备: 使用大量的图像-文本对数据,这些数据不需要是指令跟随格式,而是普通的描述性文本,例如使用数据集CC3M(595k数量),一个包含300万对图像和文本描述的数据集。
-
特征提取: 利用预训练的视觉编码器(如CLIP的ViT-L/14)从图像中提取视觉特征。
-
特征投影: 通过一个可训练的投影矩阵(W),将视觉特征(Zv)转换为与语言模型的词嵌入空间维度相同的表示(Hv)。
-
对齐训练: 在此阶段,视觉编码器和语言模型的权重被冻结(即不更新),只有投影矩阵的参数被训练。通过最大化视觉特征和文本描述之间的一致性,使得模型学会如何将视觉信息有效地映射到语言空间中。
5.2 Stage 2: Fine-tuning End-to-End. 端到端微调
目标: 这一阶段的目标是在预训练的基础上,进一步训练模型以处理多模态指令跟随任务,即模型需要根据给定的图像和语言指令生成合适的语言响应。
过程:
-
数据准备: 使用多模态指令跟随数据,这些数据包括图像、相关的语言指令和预期的语言响应。本文主要是分别用之前基于COCO数据集使用GPT4生成的视觉指令跟随数据(158k数量)和ScienceQA两个数据集微调两个版本(多模态聊天机器人和ScienceQA),其中ScienceQA数据集是多模态科学问题数据集,它的输入除了问题还会有相应的上下文信息,模型的回答需要提供推理过程,以及从多个选择中确定答案。
COCO数据集:COCO数据集包含了超过330,000张图像,80个不同的对象类别,如人、汽车、猫、狗等,覆盖了日常生活中的常见物体,不仅提供了图像和对象标注(类别和边界框),还有图像描述(captions),这些描述以自然语言的形式描述了图像内容,为图像描述生成任务提供了丰富的资源。 -
端到端训练: 在这一阶段,视觉编码器的权重仍然保持冻结,但投影层和整个语言模型的参数都会更新。模型被训练来预测给定图像和指令下的正确语言响应。
-
多模态交互: 模型学习如何结合视觉信息(Hv)和语言指令(Hq)来生成语言响应(Xa)。
-
特定任务优化: 根据具体的应用场景(如多模态聊天机器人、科学问答等),模型可以在不同的任务上进行微调,以优化其性能。
参考链接:
LLaVA系列①——LLaVA的快速学习和简单调用(附详细代码+讲解)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









