







上一篇具体讲解了Batch Normalization的原理,如果没看的小伙伴可以移步了解:
如果真正明白了Batch Normalization的原理,那么理解Layer Normalization就不在话下。本篇博文将从以下几个方面进行讲解:
1. BN用于CV, LN用于NLP?
2.LN:与BN的对比学习
3.Pytorch的LayerNorm类
4.使用Pytorch进行验证
5. Vision Transformer 中使用 LN 的原因
太阳花的小绿豆:Layer Normalization解析![]() https://blog.csdn.net/qq_37541097/article/details/117653177
https://blog.csdn.net/qq_37541097/article/details/117653177
1. BN用于CV, LN用于NLP?
可能很多人都知道BatchNorm一般用于CV领域,而LayerNorm一般用于NLP领域。那为什么会这么暴力地进行归纳呢?其实是有一定道理的:
1. 归一化的对象不一样
-
BatchNorm:它是在“一整批数据”上做归一化。想象有一堆照片,BatchNorm 是把每张照片的同一个位置(比如左上角的像素)放在一起,计算它们的平均值和标准差,然后调整每个像素的值。这样做的好处是,它能够利用整批数据的信息来稳定训练,但缺点是如果批量太小,计算出来的平均值和标准差就不够准确。
-
LayerNorm:它是在“单个样本”上做归一化。还是用照片举例,LayerNorm 是把一张照片的所有像素放在一起,计算这张照片的平均值和标准差,然后调整每个像素的值。它不依赖于批量大小,哪怕只有一张照片也能工作得很好。
2. 对批量大小的依赖不一样
-
BatchNorm:它很依赖批量大小。如果批量太大,计算出来的统计量会比较准确,训练效果就好;但如果批量太小,统计量就不够稳定,训练效果就会变差。在计算机视觉(CV)任务中,我们通常可以使用比较大的批量,所以 BatchNorm 很适合。
-
LayerNorm:它完全不依赖批量大小。不管批量有多大或多小,它都能正常工作。这在自然语言处理(NLP)任务中特别有用,因为 NLP 的数据通常是变长的(比如句子有长有短),很难使用很大的批量,而且有些任务可能一次只处理一个样本。
3. 适合的任务类型不一样
-
BatchNorm:它更适合处理图像数据。图像数据是规则的网格结构,每张图片的大小和形状都一样,不同图片的同一个位置(比如左上角)的像素值可以放在一起比较。BatchNorm 可以很好地利用这种规律性来加速训练。
-
LayerNorm:它更适合处理文本数据。文本数据是变长的序列,每个句子的长度可能不一样,而且句子内部的单词之间有语义关系。LayerNorm 可以独立地对每个句子进行归一化,不会因为句子长度不同而受到影响,因此在 NLP 任务中表现更好。
2.LN:与BN的对比学习
下面将通过与BatchNorm的对比来学习LayerNorm:
2.1 公式形式相似,但归一化的范围不同
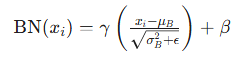
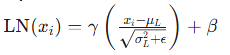
-
公式:LayerNorm 和 BatchNorm 的公式看起来很像,都是“减去均值,除以标准差”,并且都加了一个很小的量 ϵ(默认值为 10−5)来防止分母为零。它们也都引入了两个可训练参数 β 和 γ,用于调整归一化后的结果。
-
关键区别:
-
BatchNorm 是对一个批次(batch)中的每个特征通道(channel)进行归一化。它计算的是整个批次的均值和标准差。
-
LayerNorm 是对单个样本的指定维度进行归一化,与批次(batch)无关。它只关心单个样本内部的特征分布。
-
2.2 BatchNorm 需要累计统计量,LayerNorm 不需要
-
BatchNorm:
-
在训练时,BatchNorm 需要计算每个特征通道的均值和方差,并且会累计两个变量:
moving_mean(滑动平均均值)和moving_var(滑动平均方差)。这是为了在推理(测试)阶段能够使用这些统计量来归一化数据。 -
因此,BatchNorm 总共有 4 个参数:
moving_mean、moving_var、β 和 γ。
-
-
LayerNorm:
-
它不需要累计任何统计量,因为它只对单个样本进行操作,不需要考虑批次之间的统计信息。
-
LayerNorm 只有 β 和 γ 两个可训练参数。
-
2.3 适用场景不同
-
BatchNorm:
-
依赖于批次大小,适合处理规则的、批量化的数据,比如图像数据(每个批次的图像大小和通道数固定)。
-
它通过利用整个批次的统计信息来归一化数据,适合需要大规模并行计算的场景。
-
-
LayerNorm:
-
不依赖于批次大小,适合处理变长的、单个样本内部的特征归一化,比如文本数据(句子长度可能不同)。
-
它更适合处理单个样本内部的特征关系,不会受到批次大小的影响。
-
3.Pytorch的LayerNorm类
现在来详细讲解 PyTorch 的 LayerNorm 中的 normalized_shape 参数。
3.1 normalized_shape 参数的作用
normalized_shape 是 LayerNorm 的一个关键参数,它决定了要对输入数据的哪些维度进行归一化处理。具体来说:
-
normalized_shape指定的是从输入张量的最后一维开始的若干个维度。 -
这些维度将被用来计算均值和标准差,并进行归一化。
3.2 normalized_shape 的规则
-
必须从最后一维开始:
normalized_shape只能指定输入张量的最后若干个维度。 -
不能跳过中间维度:不能指定中间维度,只能从最后一维开始连续指定。
3.3 示例解释
假设输入数据的形状是 [4, 2, 3],我们来分析不同 normalized_shape 的情况:
(1) normalized_shape=[3]
-
解释:只对最后一维(大小为 3 的维度)进行归一化。
-
输入数据的形状:
[4, 2, 3] -
归一化的范围:对每个
[4, 2]的子张量(即每个 2×3 的矩阵)的最后一维进行归一化。 -
结果:每个 2×3 的矩阵的每一行都会被独立归一化。
(2) normalized_shape=[2, 3]
-
解释:对最后两个维度(大小为 2 和 3 的维度)进行归一化。
-
输入数据的形状:
[4, 2, 3] -
归一化的范围:对每个
[4]的子张量(即每个 2×3 的矩阵)的全部元素进行归一化。 -
结果:每个 2×3 的矩阵会被整体归一化。
(3) normalized_shape=[4, 2, 3]
-
解释:对整个输入张量的所有维度进行归一化。
-
输入数据的形状:
[4, 2, 3] -
归一化的范围:对整个
[4, 2, 3]的张量的所有元素进行归一化。 -
结果:整个张量会被整体归一化。
3.4 为什么 normalized_shape=[2] 会报错?
如果输入数据的形状是 [4, 2, 3],而 normalized_shape=[2],这表示你希望对倒数第二维(大小为 2 的维度)进行归一化。然而,根据 LayerNorm 的规则:
-
normalized_shape必须从最后一维开始,不能单独指定倒数第二维。 -
系统会期望输入数据的形状是
[*, 2],即最后一维的大小必须是 2。 -
但实际输入的形状是
[4, 2, 3],最后一维的大小是 3,因此会报错。
4.使用Pytorch进行验证
通过自定义layer_norm_process函数,与PyTorch 官方的LayerNorm 模块进行对比验证。
import torch
import torch.nn as nn
#自己定义一个计算LayerNorm的函数
def layer_norm_process(feature: torch.Tensor, beta=0., gamma=1., eps=1e-5):
#计算输入张量feature在指定维度(这里是最后一维 dim=-1)上的方差和均值。
#返回值var_mean是一个包含两个元素的元组
var_mean = torch.var_mean(feature, dim=-1, unbiased=False)
# 均值
mean = var_mean[1]
# 方差
var = var_mean[0]
# 归一化过程
#mean[..., None]:通过在 mean 的最后一维添加一个新的维度(使用 None 或 unsqueeze),使其形状与 feature 的最后一维对齐。
#e.g.: 如果 mean 的形状是 [batch_size, feature_dim],那么 mean[..., None] 的形状会变成 [batch_size, feature_dim, 1]。
feature = (feature - mean[..., None]) / torch.sqrt(var[..., None] + eps)
feature = feature * gamma + beta
return feature
def main():
t = torch.rand(4, 2, 3)
print(t)
# 官方layer norm处理
# 仅在最后一个维度上做norm处理
norm = nn.LayerNorm(normalized_shape=t.shape[-1], eps=1e-5)
t1 = norm(t)
# 自己实现的layer norm处理
t2 = layer_norm_process(t, eps=1e-5)
print("t1:\n", t1)
print("t2:\n", t2)
if __name__ == '__main__':
main()输出结果,可见两个结果一致:
tensor([[[0.8947, 0.4506, 0.6332],
[0.6751, 0.5315, 0.5019]],
[[0.2671, 0.4455, 0.3127],
[0.8801, 0.6446, 0.5402]],
[[0.9030, 0.7113, 0.8915],
[0.3900, 0.4035, 0.4836]],
[[0.5544, 0.3215, 0.6418],
[0.5021, 0.7900, 0.2064]]])
t1:
tensor([[[ 1.2903, -1.1460, -0.1443],
[ 1.3949, -0.5025, -0.8924]],
[[-0.9858, 1.3695, -0.3837],
[ 1.3488, -0.3073, -1.0415]],
[[ 0.7713, -1.4113, 0.6400],
[-0.8624, -0.5349, 1.3974]],
[[ 0.3586, -1.3637, 1.0050],
[ 0.0108, 1.2192, -1.2300]]], grad_fn=<NativeLayerNormBackward0>)
t2:
tensor([[[ 1.2903, -1.1460, -0.1443],
[ 1.3949, -0.5025, -0.8924]],
[[-0.9858, 1.3695, -0.3837],
[ 1.3488, -0.3073, -1.0415]],
[[ 0.7713, -1.4113, 0.6400],
[-0.8624, -0.5349, 1.3974]],
[[ 0.3586, -1.3637, 1.0050],
[ 0.0108, 1.2192, -1.2300]]])5. Vision Transformer 中使用 LN 的原因
之前有提到,在图像处理领域中BN比LN是更有效的,但现在很多人将自然语言领域的模型用来处理图像,比如Vision Transformer,此时还是会涉及到LN。Vision Transformer 将图像分割成多个小块(patches),然后将这些块视为序列输入到 Transformer 中。在这种情况下,LN 的归一化方式更适合处理这些变长的序列数据。LN 不依赖于批次大小,这使得它在处理小批次数据时比 BN 更稳定。这对于 ViT 的训练尤为重要,因为 ViT 通常需要较大的模型和较小的批次大小。在 Transformer 架构中,LN 能够更好地处理长序列数据,减少内部协变量偏移。这种特性使得 LN 在处理图像块序列时表现更好。在 Vision Transformer 中使用 LN 是为了适应其架构特点,而不是因为 LN 在图像处理中比 BN 更有效。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









