






近几年,大模型推动人工智能技术迅猛发展,极大地拓展了机器智能的边界,展现出通用人工智能的“曙光”。如何准确、客观、全面衡量当前大模型能力,成为产学研用各界关注的重要问题。设计合理的任务、数据集和指标,对大模型进行基准测试,是定量评价大模型技术水平的主要方式。大模型基准测试不仅可以评估当前技术水平,指引未来学术研究,牵引产品研发、支撑行业应用,还可以辅助监管治理,也有利于增进社会公众对人工智能的正确认知,是促进人工智能技术产业发展的重要抓手。全球主要学术机构和头部企业都十分重视大模型基准测试,陆续发布了一系列评测数据集、框架和结果榜单,对于推动大模型技术发展产生了积极作用。然而,随着大模型能力不断增强和行业赋能逐渐深入,大模型基准测试体系还需要与时俱进,不断完善。
本研究报告首先回顾了大模型基准测试的发展现状,对已发布的主要大模型评测数据集、体系和方法进行了梳理,分析了当前基准测试存在的问题和挑战,提出了一套系统化构建大模型基准测试的框架——“方升”大模型基准测试体系,介绍了基于“方升”体系初步开展的大模型评测情况,并对未来大模型基准测试的发展趋势进行展望。面向未来,大模型基准测试仍存在诸多开放性的问题,还需要产学研各界紧密合作,共同建设大模型基准测试标准,为大模型行业健康有序发展提供有力支撑。






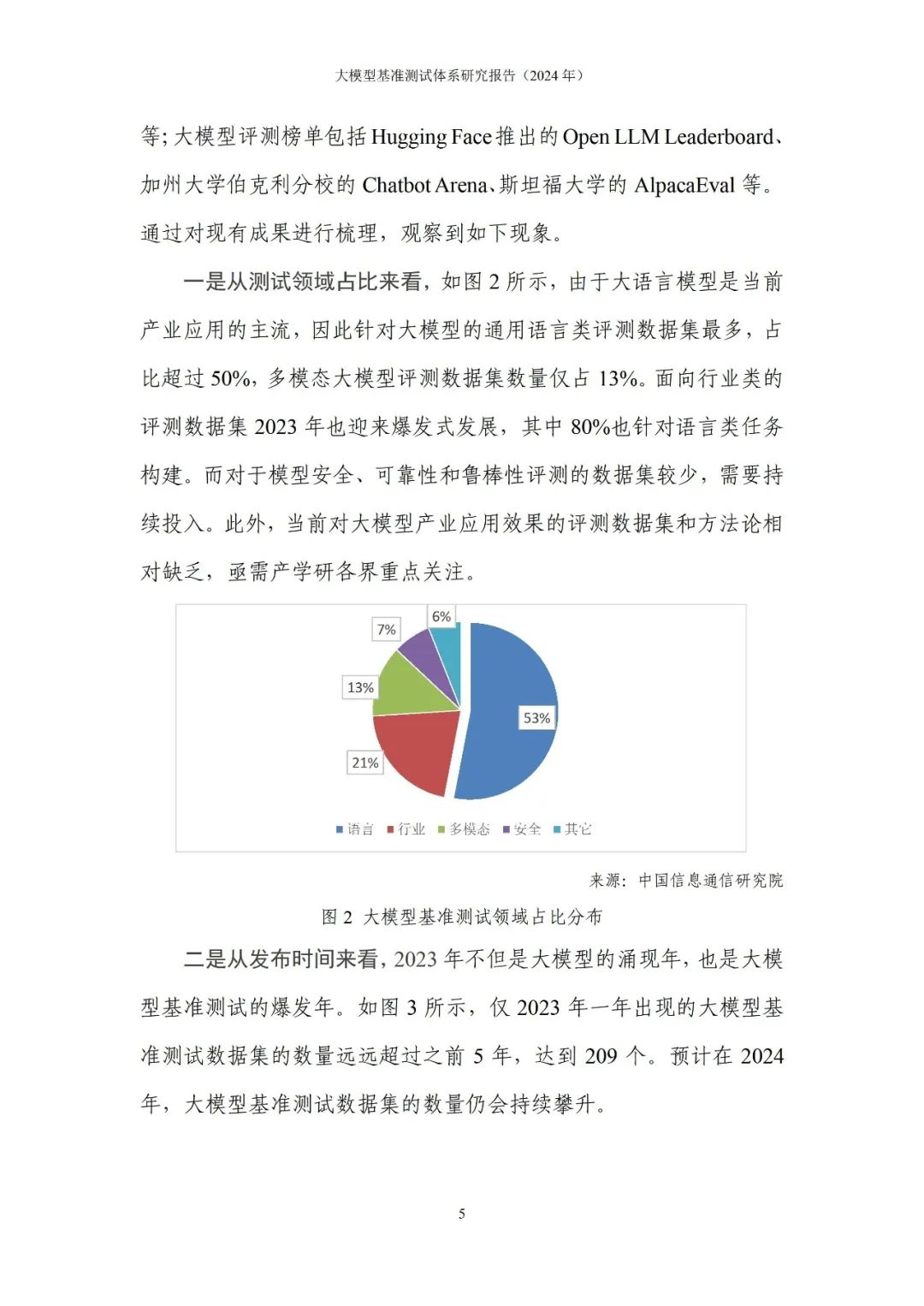

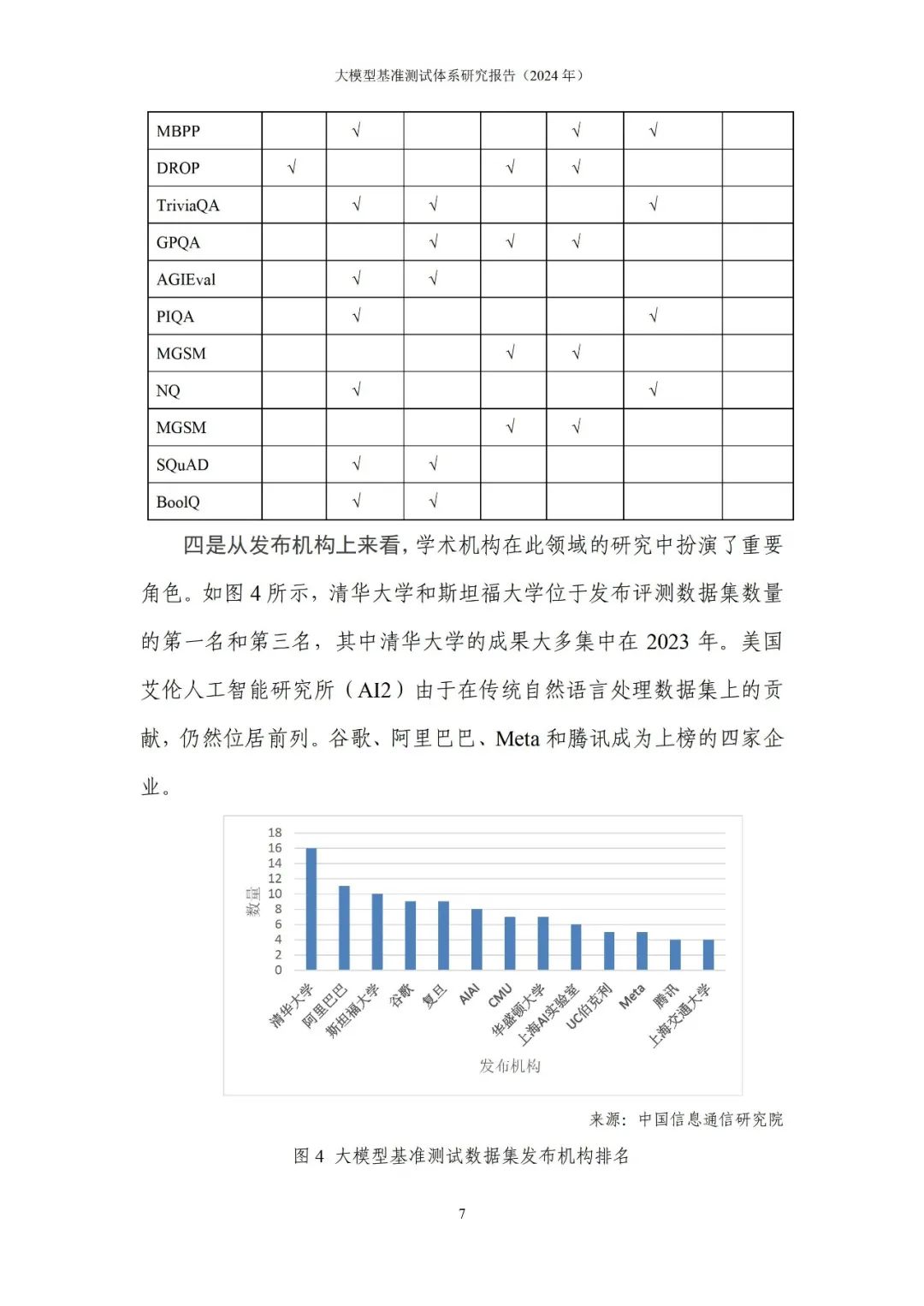
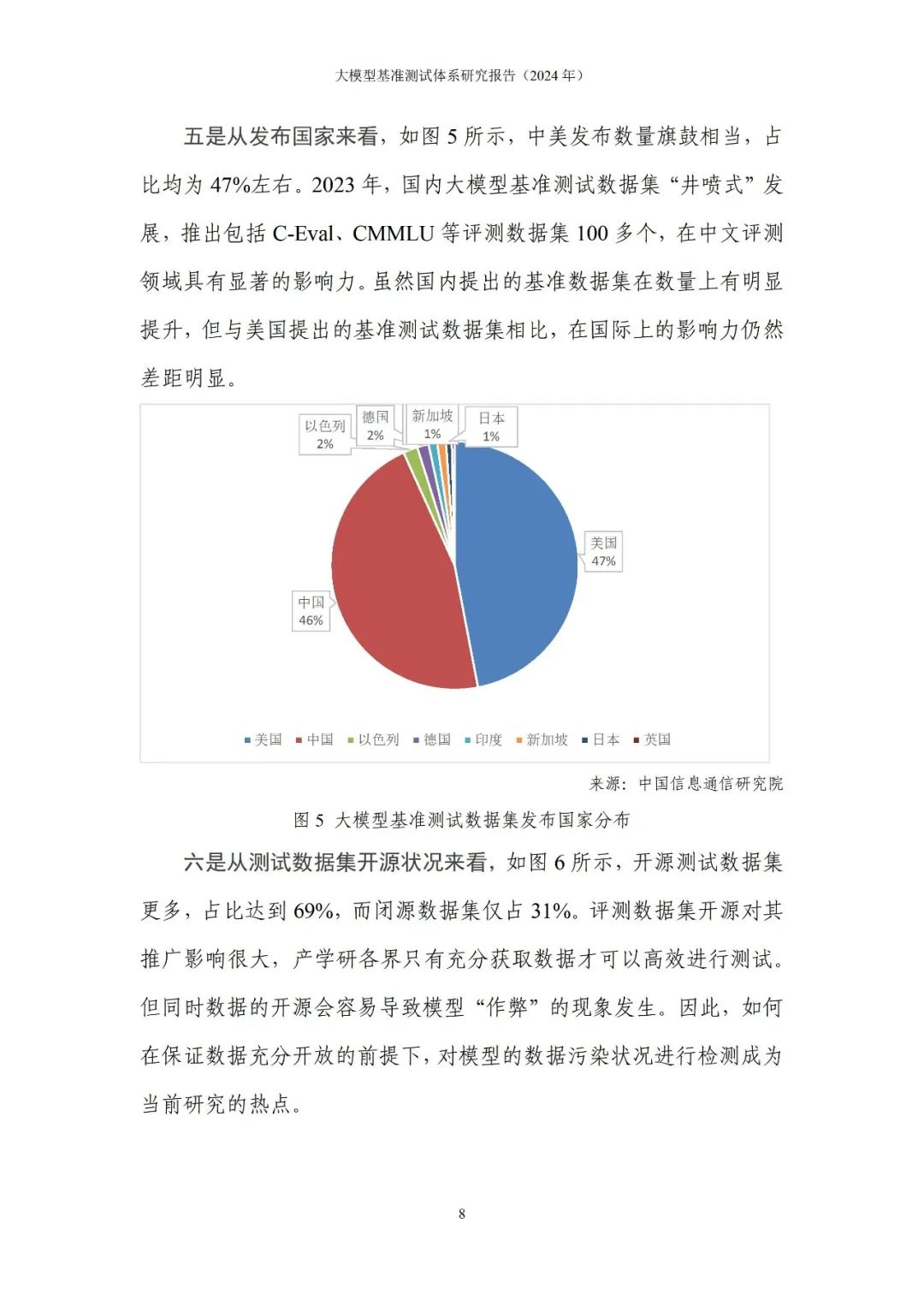









































 696
696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









