









论文学习 探索使用CNN实现对单图像实现过完备表示
前言
时隔3个月,沉迷于玩游戏以及和女朋友在一起的生活,每次想看些什么论文但是最终没有下笔,大学的考试还是太难了些,对于像我这样的菜鸡果然还是尽早找个电子厂上班吧,哈哈,好在下学期不需要再学习那些抽象的数学了,希望能够在计算机方面有一些自己的理解和贡献,最近在和导师交流的过程中,导师提到了这篇文章,于是还是趁着这股外力赶紧翻译出来吧,之后可能迫于学业压力或者社团活动啊学生会活动啊,可能又无法做到笔耕不辍了,但是也希望自己的翻译能够为之后想要搜这篇文章的人有一点帮助吧,也算是我没有白上这个大学,也算是对自己有一个交代了。
如有侵权,请联系,会退还所有可能利益,并删改。
论文
论文连接:Exploring Overcomplete Representations for Single Image Deraining Using CNNs
专有名词解释
总述
除去图像中的雨滴形噪点是一个及其具有挑战性的工作,因为这一类图像经常包含有尺寸、形状、方位、稠密度不同。近来大多数的方法都使用一个深度网络并跟随一个通用的“编码-解码”结构,这能捕捉图像中的底层特征通过最初的层,并通过更深的层捕捉其高级特征。对这一任务,如果需要去除的噪点相对较小,聚焦于全局特征并不是一个行之有效的方式,在本文中,我们尝试使用一个过完备的卷积神经网络结构,这让我们能够获得对于其局部结构的特别关注,通过抑制其感受野和过滤器。我们将这个东西与U-net组合在一起,由此它将不会损失掉全局特征的同时关注更多的局部特征。我们将我们的工作(这个网络结构)命名为over-and-under complete deraining network(OUCD),这包含两个分支,过完备(overcomplete)分支将被局限于小的感受野为了聚焦在局部结构,与此同时,欠完备分支具有更大的感受野来基本上聚焦于全局特征。
背景介绍(这里从简)
“编码器-解码器”卷积网络架构背后的主要思想是,在初始卷积层,滤波器的接收域大小很小,因此捕捉底层特征,如边缘。
噪音元素在不同的任务中可以有不同。
与欠完备的卷积网络不同,在这一类卷积网络中感受野会随着我们深入网络而扩大,而过完备的架构会限制更深层次感受野的扩大。这一特点会帮助我们强制将所有层的过滤器聚焦于底层特征。 此外,与最初的层相比,更深的层现在了解了更细的边缘和更小的物体,这有助于我们更好地检测和消除雨条纹。虽然我们认为低级特征对于脱轨任务更重要,但这并不意味着高级特征对于这个任务没有任何意义。高级特征也很重要,因为它们有助于正确地重建图像中的大型结构和物体。因此,我们提出了一种新的网络结构,它结合了过完全和欠完全的结构,以一种有效的方式对图像进行去噪。
相关工作(正文)
数学建模
对于一幅带有雨点的图片,我们将其定义为 y \mathcal{y} y,进一步我们可以将其看为在清晰图片 x \mathcal{x} x的基础上添加了雨点信息 r \mathcal{r} r: y = x + r (1) \mathcal{y = x +r}\tag{1} y=x+r(1)
基于视频的方法
基于视频的修复方法具有丰富的时间信息,可以利用时间一致性来解决解调问题。以不同的方式利用时间信息,利用时间信息去除视频中的雨信息。提出了一种基于多尺度卷积稀疏编码模型的视频雨条纹去除方法,该方法同时考虑了雨条纹服从多尺度配置且模式稀疏分散的特征。提出了一种两步架构,他们从最初估计的脱轨图像中提取可靠的运动信息来对齐帧,然后在第二阶段建模运动。
基于单张图片的方法
文献中的早期方法,如用于除雨任务的[25]-[28],使用传统的图像处理技术。它们包括使用低-高频图像分解[25]、基于低级别(rank)表示的[45]、基于字典学习的[46]和基于高斯混合模型的方法[28]来解决降雨去除问题的技术。Fu等人[18]、[47]以端到端深度学习的方式引入了基于CNN的方法来解决降雨去除问题。Zhang等人[21]提出了密度感知多流的CNN模型,
在该模型中,他们首先估计了雨图像的密度,并用它来融合来自不同流的特征,以获取去除雨滴的图像。Qian等人提出了一种基于聚焦(attention)的雨滴去除网络,他们使用基于循环网络的架构来获得注意地图。Li等人[19]利用循环神经网络的好处来保存早期层的有用上下文信息。Ren等人[37]提出了一种更简单的基于ResNet的基线网络,以渐进的方式进行去滤波,以获得最终的去滤波图像。[48],[49]提出的雨天数据集考虑了雨天图像的物理公式。Wang等人[20]提出了一个局部到全局的过程,使用空间注意块来去除图像。Yasarla等人[22]提出了一种多尺度脱除方法,通过建模估计低尺度残差的不确定性,并将其用于计算最终脱除的图像。Wei等人[50]提出了一种使用高斯混合模型的半监督脱轨方法。Wang等人[38]提出了一种网络,通过构造残差学习分支来学习从低质量嵌入到潜在最优向量的映射,该分支能够以纠缠表示的方式自适应地将原始低质量嵌入之间的残差添加到潜在向量。Yasarla等人[51]提出了一种半监督方法,利用来自真实降雨图像的降雨信息,使用高斯过程训练网络。最近的研究建议使用金字塔网络、上下文深度网络等技术来去除图像,可以在[52]-[54]中找到。
提出的方法
如前所述,大多数图像去处理方法都是基于“编码器-解码器”体系结构(基于U-Net)或残差体系结构。这些体系结构不太关注局部特征,因为这些网络的更深层次有很大的接受域,因此提取高级特征。
虽然学习全局特征是“encoder-decoder”设计的初衷,它也确实在诸如目标检测、图像分割、目标分类任务中十分有效,这是由于这些需要检测的物体在整张图片中相对较大。但是在去除雨滴的任务重,这显然不适用,这是由于雨滴很微小,这使得我们在使用小的感受野的过滤器会产生比较好的效果。
收到启发,我们强行限制感受野的尺寸,使得我们的神经网络能够捕获低级特征,而实现这一目的的方法便是使我们越深的层其尺寸越大,这也就是我们所说的过完备卷积结构。
在过完备神经网络中,输入图片将会被转换入一个更高维的空间。当我们将欠完备结构中的最大池化层替换为上采样层,便会产生这种效果。在传统的欠完备架构中,感受野的扩大是由于其中的最大池化层。在该结构前传的过程中,一个尺寸为 k × k k \times k k×k的特征图在通过一个参数为 n n n的池化层后,其尺寸会变为 k / n × k / n k/n \times k/n k/n×k/n,这一状况在反向传播的时候,梯度的流向从 k × k k \times k k×k向 n k × n k nk \times nk nk×nk,这增大了感受野,这在深层网络中产生的效应便是使其学习到了全局特征。然而如果我们将最大池化层转变为上采样层,这便会产生一种相反的效果。在前传过程中,特征图的尺寸从 k × k k \times k k×k变为 n k × n k nk \times nk nk×nk,由此在反向传播的过程中,其梯度流向便会是 k × k k \times k k×k向 k / n × k / n k/n \times k/n k/n×k/n。虽然在每一个卷积层都会导致感受野的增大(这是由于卷积核的尺寸导致的),但是上采样层能够在一定程度上抑制这种情况。
总的来说,就是以上的变换使得我们的结构能够学习细节特征。
其实从论文中的figure能看出,使用过完备(Fig2)结构中间层产生的特征图大量捕捉了雨点的信息,而与之对比的欠完备(Fig3)结构,则更多捕捉了图片中主体和背景的信息。

A.OUCD架构
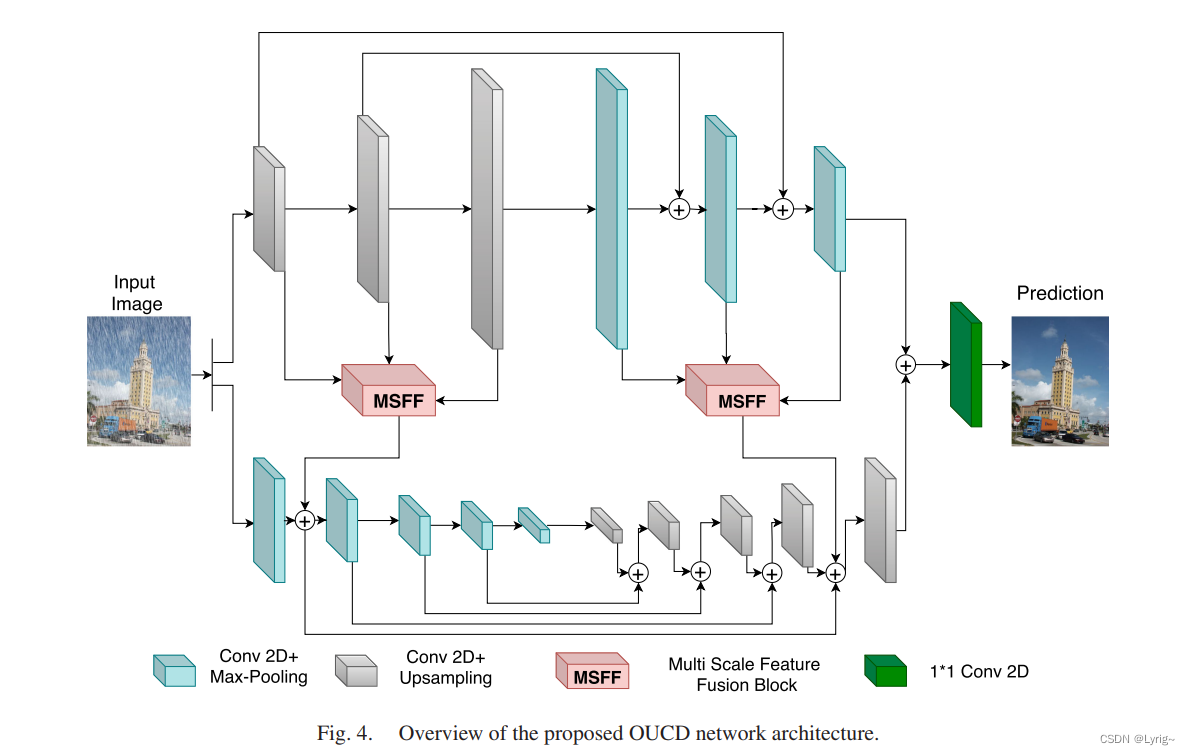
在过完全分支中,我们在编码器和解码器中都有3个卷积块。编码器中的每个卷积块都有一个二维卷积层,后面跟着一个上采样层和ReLU激活。我们的体系结构中的所有卷积层的内核大小都是3 × 3,步长为1,填充为1,除非另有说明。对于上采样,我们执行比例因子为2的双线性上采样。在解码器中,每个卷积块都有一个二维卷积层,然后是最大池化层和ReLU激活[55]。最大池化层的池化系数为2。我们也有类似于U-Net[7]从编码器层到解码器层的跳过连接,以便更好地定位。
未完成的分支类似于标准的U-Net架构。它在编码器和解码器中都有5个卷积块。编码器中的每个卷积块由一个二维卷积层(Conv2d),然后是最大池化层(MaxPooling)和ReLU激活。解码器中的每个卷积块由一个二维卷积层、一个上采样层和ReLU激活组成。池化层和上采样层的系数都为2。我们也有从编码器的每个块到解码器中相应块的跳跃式连接,类似于U-Net架构。附录中提供了与过完整和不完整分支相对应的网络体系结构的更多细节。
由于我们已经建立了过完整分支在其所有层中提取有用的低层特征,我们建议使用所有这些特征图来更好地预测除去雨滴的任务,因为大多数雨纹都是低层特征。这些特征映射比不完全分支(U-Net)的初始层捕捉到非常精细的细节,因为与U-Net的初始层相比,过完全网络作用的图像的分辨率非常高。因此,我们利用所有这些来自过完全分支编码器的特征映射,将它们添加到欠完全分支第一层的输出中。这有助于在未完成分支的后几层学习更好的全局特性。同样,过完全分支的解码器中的所有特征映射都被添加到欠完全分支的解码器的特征映射中,正好在最后一个块之前。这也有助于在解码器部分更好地恢复。在从过完整的分支中添加特征映射之前,我们将其通过多尺度特征融合(MSFF)块。
MSFF块的细节将在下一小节给出。
此外,我们将超完全分支的最后一组特征映射添加到欠完全分支,然后将其传递到最后一个卷积层。最后一个卷积层1 × 1核,将特征映射转换为3通道RGB图像。然后,使用损失函数计算反向传播的梯度,将该预测与地面实况进行比较。
B.MSFF块

这里我个人认为,无需说的多么高端,该MSFF块仅作为一种加和而已,其本质是将不同尺寸的特征图像通过卷积和MaxPooling层,使得其尺寸一致,从而可以用于加和。个人感觉有点类似于ResNet中残差块的效果,但是应该是plus版,因为可以通过自己设置卷积层的参数和MaxPooling的参数,使得对任何尺寸的输入特征图像都能达到统一尺寸,感觉或许能够综合更多的细节特征??不理解。
我们提出了一个MSFF块,将过完全分支的不同尺度的特征映射转移到不完全分支,并将它们转换成相似的尺度,同时保持相同数量的特征映射,使它们在添加时具有相同的权重。MSFF块的网络结构如图5所示。
我们用卷积层图5所示。多尺度特征融合(MSFF)块体系结构块,该块由下采样层和跨每个刻度的1 × 1卷积层组成。下采样层(代码中使用的是max_pool2d来实现下采样)用于对特征映射进行下采样,使其与将要加入的欠完整分支中的特征映射的比例相同。我们使用双线性插值(bilinear)进行下采样操作。每个比例尺的比例因子等于欠完整分支中的特征图大小与该特定比例尺上的特征图大小之比。使用1 × 1卷积层,使在过完全网络的不同尺度上获取的特征映射数量一致,使所有的特征映射在添加到欠完全分支时具有相等的权重。然后添加特征映射,并将其传递给未完成的分支。
损失函数
我们使用标准的 l 2 l_{2} l2范数损失函数, L m s e = ∥ x ^ − x ∥ 2 2 (1) \mathcal{L}_{mse} = \|\hat{x} - x\|^2_2\tag{1} Lmse=∥x^−x∥22(1)与此同时,我们也使用了计算感知损失,这一功能我们通过预训练的VGG-16神经网络实现: L p = 1 N H W ∑ i ∑ j ∑ k ∥ F ( x ^ ) i , j , k − F ( x ) i , j , k ∥ 2 2 (2) \mathcal{L}_p = \frac{1}{NHW}\sum_{i}\sum_j\sum_k\|F(\hat{x})^{i, j, k}-F(x)^{i, j, k}\|_2^2\tag{2} Lp=NHW1i∑j∑k∑∥F(x^)i,j,k−F(x)i,j,k∥22(2)其中 N N N是函数 F ( . ) F(.) F(.)的通道数(维数),而 H 和 W H和W H和W代表了特征图的高和宽。式子中的 x x x表示真实状况, x ^ \hat{x} x^表示预测状况,我们利用VGG-16的relu1_2、relu2_2和relu3_2的特征来计算感知损失。用于训练OUCD网络的总损耗为: L = L m s e + λ L p (3) \mathcal{L} = \mathcal{L}_{mse} + \lambda\mathcal{L}_p\tag{3} L=Lmse+λLp(3),这里的 λ \lambda λ在我们的实验中设置为0.04。
具体实验细节
这里我不复述原文了,写成我自己的复刻细节吧。。。。(未完待续)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









