







yolov7源码下载
YOLOv7是一种目标检测算法,是YOLO系列的最新版本。YOLOv7基于YOLOv5算法,使用了一些新技术和优化,进一步提高了检测性能和速度。与以往版本相比,YOLOv7具有更好的精度和更快的推理速度,同时还支持更多的应用场景。
通过git拉取到自己本地目录
yolov7模型下载
在源码下载下面有个如下界面:
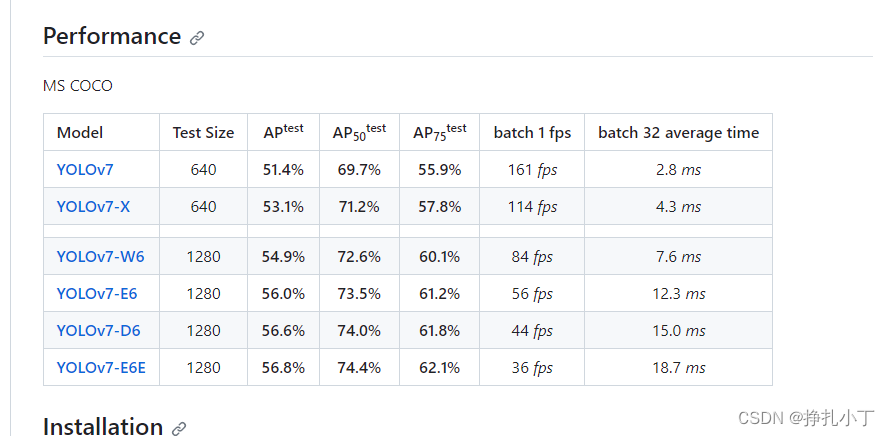
这里我使用的是YOLOV7-D6,如图batch 32 average time来看的话就是就是每个版本批量大小为32训练的平均时间。你们可以根据训练的数据类型来选择
通过pycharm打开克隆下来的yolov7源码
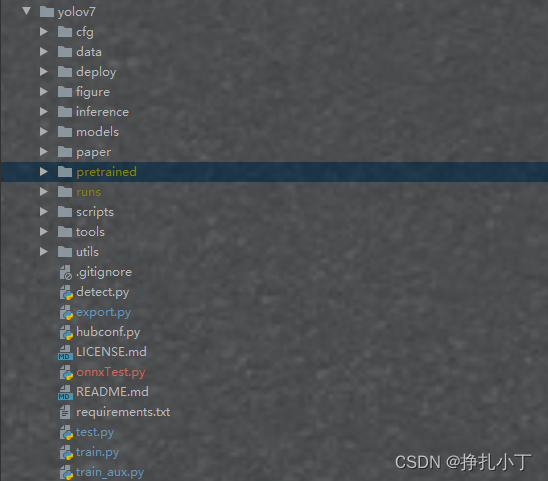
并新建pretrained文件夹,把下载下来的pt模型文件放到此文件下
文件解析
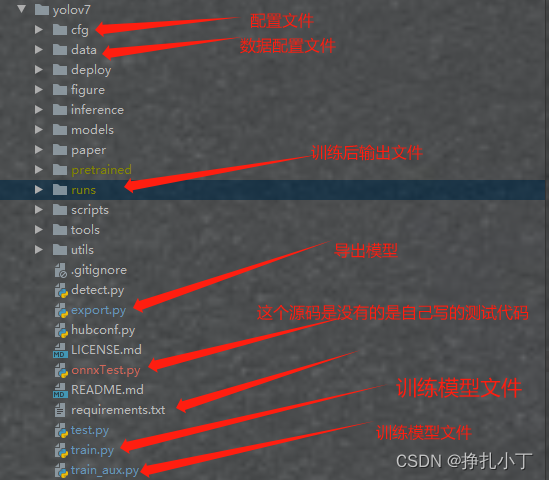
这里是我个人理解标注,有什么不对的见谅。
依赖下载
进入这个文件夹执行:
# 这里表示下载所需要的依赖,并指定下载源为阿里云,速度更快
pip install -r requirements.txt --default-timeout=1000 -i https://mirrors.aliyun.com/pypi/simple/
如出现问题,百度自行解决哟,都是下载问题之类的
训练素材准备
这里的素材准备根据你想要去识别什么来准备,我这里就不提供素材数据源了,直接提供怎么去处理数据源等等
- 准备自己的图片
- 创建一个如下层级的文件夹:
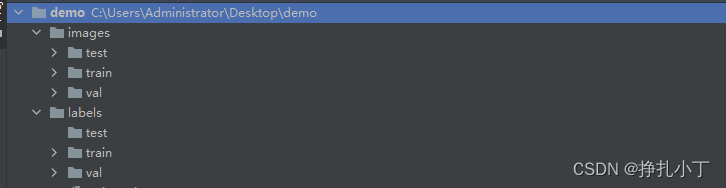
** 这里三个目录对应的是测试集数据,训练集数据,验证集数据** - 下载工具labelimg,如果下载慢也可以添加指定下载源、如下:
pip install labelimg
- 启动labelimg、在命令行输入的命令如下:
labelimg
启动成功能看到一个界面出现
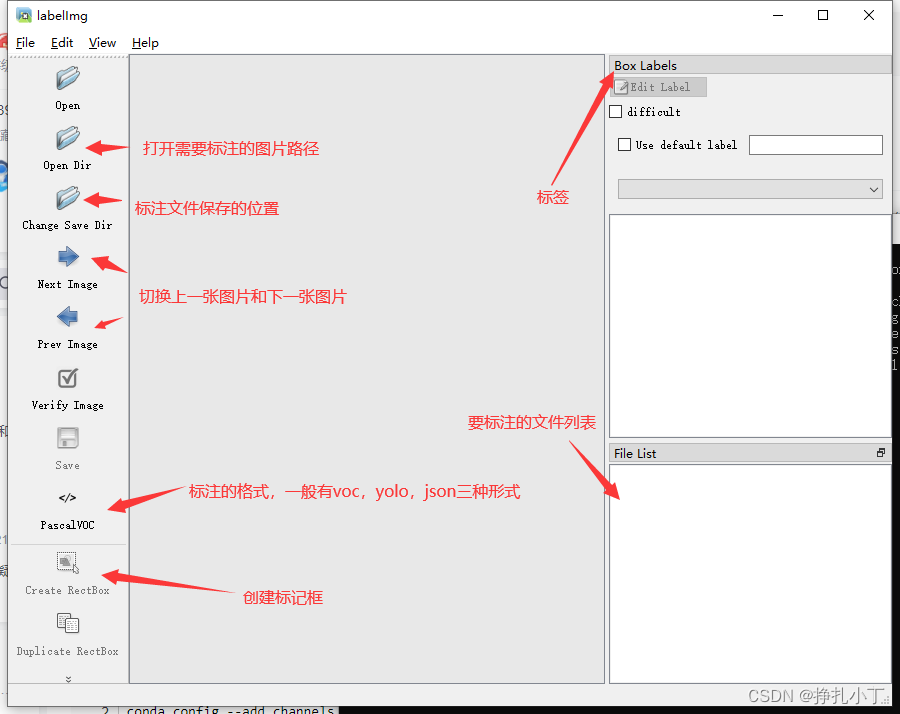
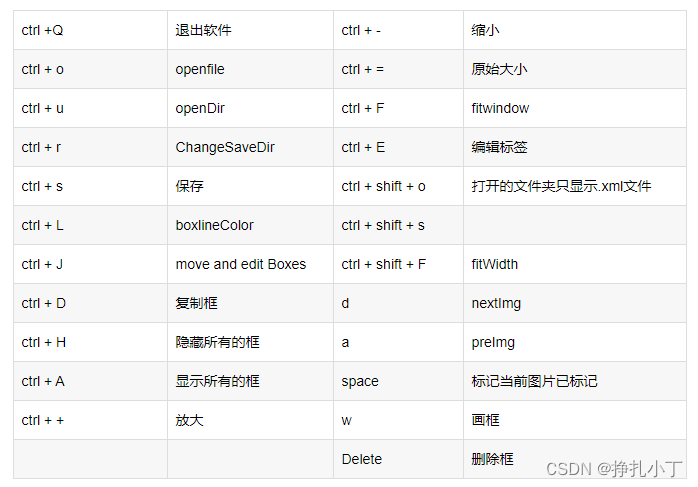
labelimg的快捷键如下,学会快捷键可以帮助你提高数据标注的效率。
5. 选择好图片路径和标注文件保存位置后,标注格式选择yolo、进行标注。
6. 点击Create RectBox标记出来你要识别的物体,然后输入一个自定义的标签名称、一张图片可以同时标记多处。
7. 保存后会在你指定的文件夹下面生成前缀为你图片名、后缀为txt文件。
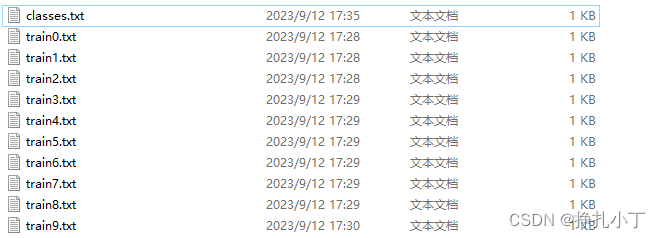
第一个classes文件是保存的你自定义的标签名称、后面文件保存的每张图片的对应classes文件中的第几个标签位置和图片标记框的定位点
修改源码中配置文件内容
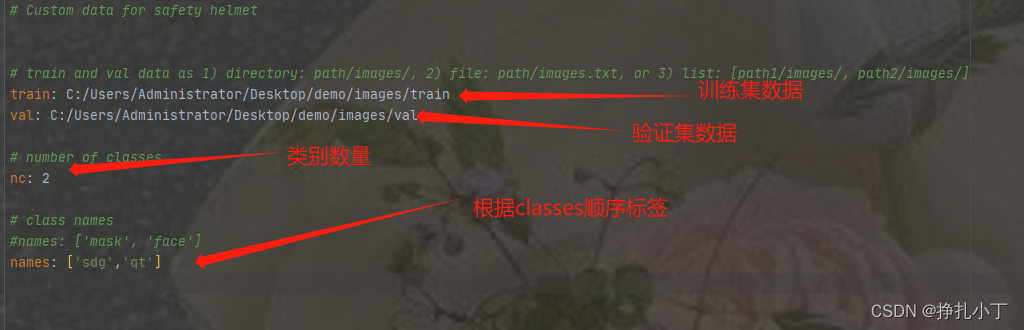
在data目录下新建一个自定义的yaml后缀的配置文件,如下图:
训练数据开始
- 找到train.py文件
这里的参数可以写死在里面也可以通过命令去指定 - 打开控制台,输入以下命令:
python train.py --data mask_data.yaml --weights pretrained/yolov7-d6.pt --epoch 200 --batch-size 8 --device cpu --workers 4
**这里的命令参数我讲几个常用的 --data 是指定你自己定义的数据配置文件位置 --weights是你下载的模型 --epoch是训练次数 —batch-size批处理长度 --device 指定是CPU 还是GPU (这里我是没有GPU所以只能CPU) --workers 是工作数量(如果电脑配置不行的话,就改小),具体内容根据你自定义的去改 **
- 等待运行,就会自动生成runs/train/exp/文件夹,完成时间可能比较漫长,weights下面是各种训练出来的模型。

模型评估
一些学术上的评价指标用来表示我们模型的性能,其中目标检测最常用的评价指标是mAP,mAP是介于0到1之间的一个数字,这个数字越接近于1,就表示你的模型的性能更好。
一般我们会接触到两个指标,分别是召回率recall和精度precision,两个指标p和r都是简单地从一个角度来判断模型的好坏,均是介于0到1之间的数值,其中接近于1表示模型的性能越好,接近于0表示模型的性能越差,为了综合评价目标检测的性能,一般采用均值平均密度map来进一步评估模型的好坏。我们通过设定不同的置信度的阈值,可以得到在模型在不同的阈值下所计算出的p值和r值,一般情况下,p值和r值是负相关的,绘制出来可以得到如下图所示的曲线,其中曲线的面积我们称AP,目标检测模型中每种目标可计算出一个AP值,对所有的AP值求平均则可以得到模型的mAP值,以本文为例,我们可以计算佩戴安全帽和未佩戴安全帽的两个目标的AP值,我们对两组AP值求平均,可以得到整个模型的mAP值,该值越接近1表示模型的性能越好。
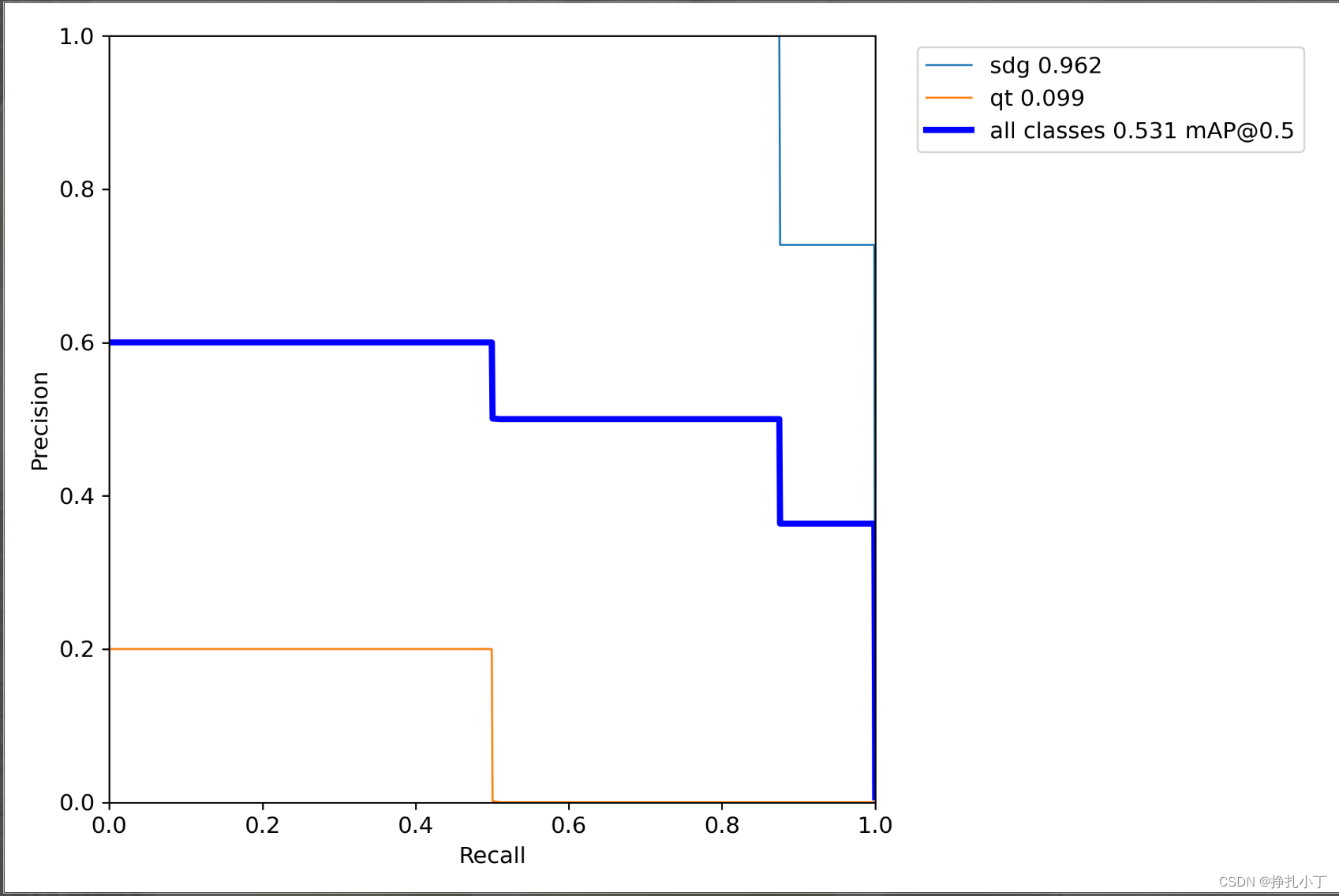
关于更加学术的定义大家可以在知乎或者csdn上自行查阅,以我们本次训练的模型为例,在模型结束之后你会找到三张图像,分别表示我们模型在验证集上的召回率、准确率和均值平均密度。
以PR-curve为例,你可以看到我们的模型在验证集上的均值平均密度为0.531(这里根据你训练素材和训练次数有很大关系)
模型导出为onnx后缀模型
-
找到export.py文件

这里的参数也差不多,最主要的还是–weights指定你训练出来的模型路径 -
控制台输入以下命令:
python export.py --grid --end2end --simplify --topk-all 100 --img-size 640 640 --max-wh 640 --weights runs/train/exp/weights/best.pt
- 运行完成后在runs/train/exp/weights/目录下会有一个best.onnx文件
- 到这里基本就完成了。
总结
这里已经完成基本的训练模型训练和转换模型,主要的内容还是准备数据源、标记数据格式和修改一下配置文件。中途可能有出现很多问题,之所以我没有把问题整理出来是因为问题确实会出现很多种有很多不确定因素。有问题可以查阅一下资料或者评论我不说百分百能给你解决,能解决的肯定会给你讲解,下一期就实现通过java去调用onnx模型返回数据并显示出来














 934
934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









