







csdn总结服务容错的背景、解决方案、sentinel的基本使用
背景:服务雪崩
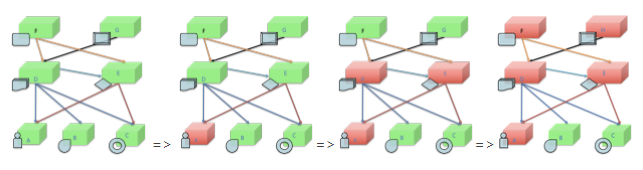
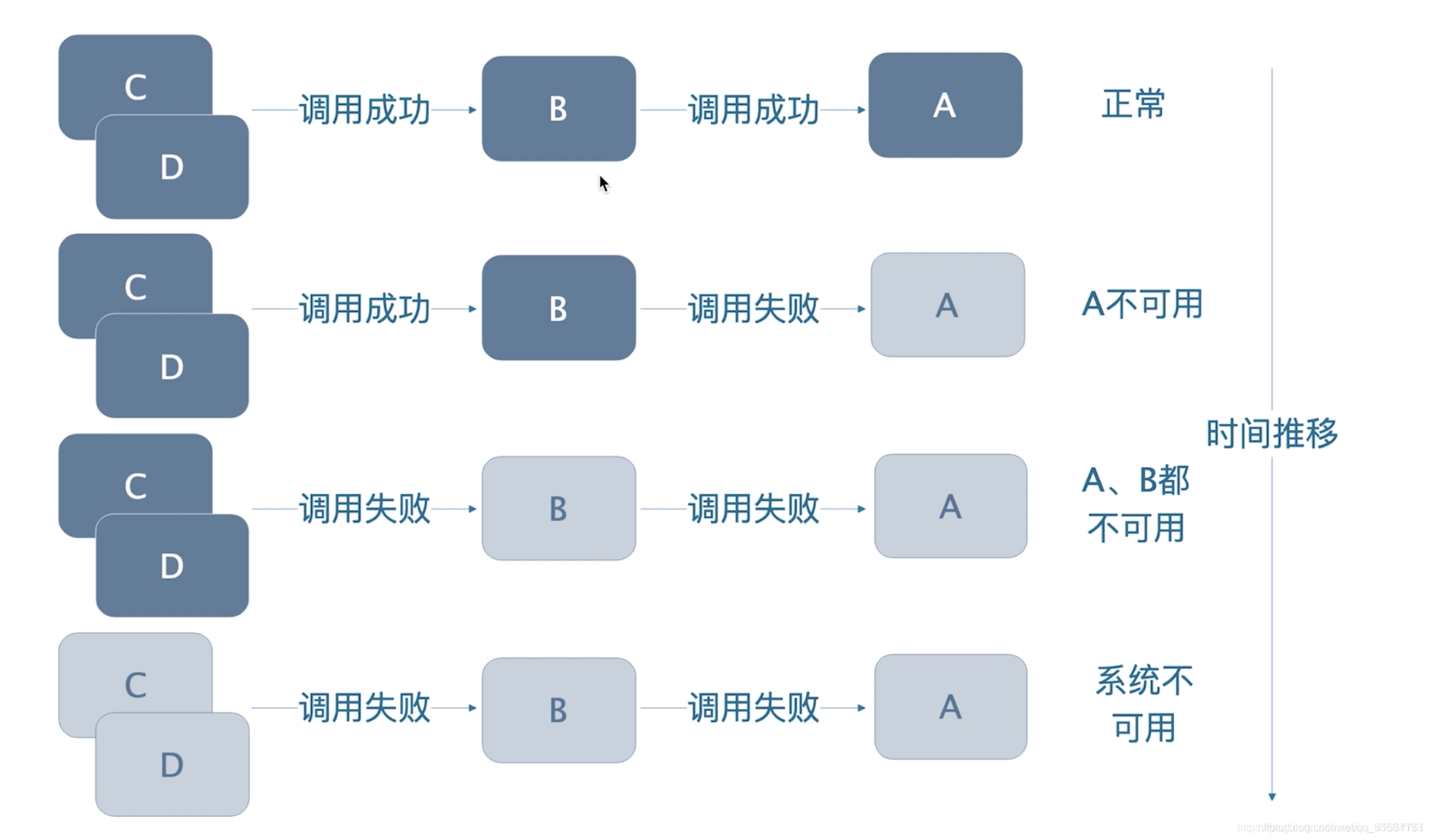
在高并发的应用中,b会持续向a服务发送请求,如果a服务死掉,b发往a的请求就会强制等待直到请求超时,在Java程序中,一次请求往往对应一个线程,如果请求被强制等待了,线程就会被强制阻塞,一直到请求超时的时候这个线程才会被释放,由于是一个高并发的应用,阻塞的线程就会越来越多,线程也对应着服务器的计算资源(内存、cpu),如果不做任何处理,终有一天b服务所在的服务器资源被完全占用,无法再创建新的线程发出请求,导致b也会死掉。以此类推,最终导致所有服务死掉。把基础服务故障导致上层服务故障并且不断放大的过程叫做雪崩效应。也被称为cascading failure,也叫级联失效或级联故障。
造成雪崩原因可以归结为以下三个:
1,服务提供者不可用(硬件故障,程序bug,缓存击穿,用户大量请求)
2,重试加大流量(用户重试,代码逻辑重试)
3,服务调用者不可用(同步等待造成的资源耗尽)
在复杂的分布式架构的应用程序有很多的依赖,都会不可避免地在某些时候失败。高并发的依赖失败时如果没有隔离措施,当前应用服务就有被拖垮的风险。
- 例如:一个依赖30个SOA服务的系统,每个服务99.99%可用。
- 99.99%的30次方 ≈ 99.7%
- 0.3% 意味着一亿次请求 会有 3,000,00次失败
- 换算成时间大约每月有2个小时服务不稳定.
- 随着服务依赖数量的变多,服务不稳定的概率会成指数性提高.
解决方案
超时(只要释放够快,就不那么容易导致服务死掉)
限流(控制访问流量,通过指定的策略消减流量)
仓壁模式(不要把鸡蛋放一个篮子里,每个接口对应自己的线程池)
断路器模式(监控+开关)

sentinel的基本使用
sentinel是什么?
轻量级的流量控制、熔断降级Java库。
整合sentinel
1.加依赖
<!--sentinel熔断-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2.yaml中配置
# 应用名称
spring:
application:
name: sentine
cloud:
nacos:
discovery:
server-addr: localhost:8848
server:
port: 8005
# actuator
management:
endpoints:
web:
exposure:
include: '*'
下载地址:https://github.com/alibaba/sentinel/releases

3.控制台是懒加载的,需要先发请求,再能看到配置
在应用中开发一个端点 /hello
发请求给hello
在控制台刷新,看到sentine项目的控制台界面
规则默认存放在项目的内存中,若是重启则消失















 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











