







目录
Part 1 引言
在上一期文章Python 教学 | 数据处理必备工具之 Pandas(基础篇)中,我们向大家介绍了 Python 中第三方库 Pandas 的数据结构和字段类型,正如笔者在文章最后所说,实际中进行数据处理和分析大多是从数据读取开始的,由此看来,如何从不同格式的文件中读取数据是首要问题,而 Pandas 拥有强大的读取数据的功能,提供了多种函数和参数,可以从 Excel 表格、CSV 文件、数据库、网页等多渠道读取数据,并将其存储为 DataFrame 以进行数据处理和分析,最后再将处理后的数据导出为指定格式的文件,比如pandas.read_csv()函数可以将 CSV 格式的数据读到 DataFrame 的数据结构中,然后对这个 DataFrame 进行处理分析后,通过pandas.to_csv()函数导出数据。
本期文章我们将学习使用 Pandas 实现数据的读取和导出,并介绍几个 DataFrame 的常用属性来查看数据的基本信息。
本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 中编写。
Part 2 数据的读取与导出
Pandas 强大的数据读取功能体现在其支持目前绝大多数主流的数据存储形式,如常见的 Excel、CSV 及多种数据库。那么 Pandas 是如何实现数据读取的?Pandas 通过读取函数读取数据表,在读取过程中将原始数据中的表格转换为 DataFrame 类型,然后我们就可以对读取后的 DataFrame 进行处理分析,最后调用 Pandas 中的数据导出函数将数据写入指定类型的文件。Pandas 针对不同的文件格式提供了相应的读取函数以及导出函数,下表列出 Pandas 中一些常见文件格式的读取与导出函数。
| 文件格式 | Pandas 读取函数 | Pandas 输出函数 |
|---|---|---|
| Excel | read_excel | to_excel |
| CSV、TXT | read_csv | to_csv |
| SQL 查询数据库 | read_sql | to_sql |
| DTA | read_stata | to_stata |
| 本地剪贴板 | read_clipboard | to_clipboard |
Pandas 中还有一些不太常用的文件格式的读取与写入函数,这里不再列举,上表中的函数已经足够我们日常使用了,在日常的工作学习中,Excel 工作表、 CSV 文件和 Stata 文件是我们经常使用的表格文件类型,所以下文我们详细介绍 Pandas 中读取这三种文件的read_excel()、read_csv()和read_stata()函数。
Part 3 Pandas 读取文本文件
为什么先介绍 Pandas 读取文本文件呢?因为实际中我们最常用的文件格式之一就是文本文件,这种文件格式的跨平台兼容性较好,并且文本文件的可读性强,可以使用任何文本编辑器打开。常见的表格形式的文本文件主要是 CSV 文件和 TXT 文件,其中以字符分隔的 CSV 文件是最常用的文件格式,Pandas 为读取 CSV 文件提供了强大的功能,下面我们详细介绍。
CSV(Comma-Separated Values)是用特定字符(一般情况是半角逗号)分隔表中不同单元格数据值的数据形式,其文件的扩展名为.csv。CSV 文件是以行作为单位存储数据的,每行数据用逗号分隔,文本的一行表示数据表的一行。下面是一个 CSV 文件示例(使用文本编辑器打开)。
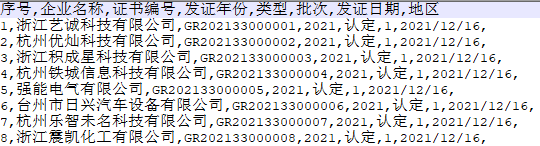
在这个示例中,第一行是标题行,表示数据表的字段名,下面的八行是数据行,每行都包含八个数据值(序号、企业名称...),一行中的不同值用逗号分隔。Pandas 中提供了read_csv()函数来读取 CSV 文件,该函数有四十多个参数,我们在这里仅介绍常用的参数,如下表所示。
| read_csv 函数的常用参数 | 用法 |
|---|---|
| filepath_or_buffer | 必需参数,CSV 文件所在的路径或返回文件对象的函数 |
| sep | 字符串,默认为逗号,用于字段之间的分隔符 |
| header | 整数,表示 CSV 文件中表头所在的行号,默认为0,即第一行为表头 |
| names | 用于将自定义的列名列表传递给 DataFrame 对象 |
| usecols | 用于筛选需要读取的列 |
| dtype | 字典,用于将指定的列的类型转换为指定的字段类型 |
| chunksize | 可以指定读取 CSV 文件的每个块中包含多少行记录 |
| encoding | 字符编码,默认为 None |
现在我们仅使用必需参数来读取上面示例中的 CSV 文件,代码如下。
data = pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv')
data # 查看结果

虽然上面代码中的pd.read_csv()函数只有一个文件的相对路径作为必需参数(关于相对路径与绝对路径的内容,可以参考这期文章Python教学 | 最常用的标准库之一 —— os),事实上其他参数使用了默认值,比如pd.read_csv()函数的参数header默认将 CSV 文件的第一行作为表头(也称“字段名”或“列名”),参数 sep 默认以逗号作为文件的分隔符。如果 CSV 文件是以分号;作为分隔符的,那么在读取该文件时就需要指定参数sep=';',其他情况也类似。
当我们想自定义 DataFrame 的表头时,代码如下:
data = pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv', header=0, names=['企业现名', '发证编号','发证年份','认定类型', '批次', '发证日期', '地区'])
data

上面的代码中我们使用参数header指定第一行为表头,并且将列名列表传给参数names,这样就能够用自定义表头覆盖原文件表头。这里需要注意一点,如果原 CSV 文件有表头,那么在使用参数names自定义表头时,需要指定参数 header=0,否则原表头会作为 DataFrame 的第一行数据,如下所示:

另外,我们在实际的数据处理中可能只需要一个文件中部分字段的内容,如果我们只想读取 CSV 文件的部分列要如何实现呢?代码如下:
data = pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv', usecols=['企业名称', '证书编号','发证年份', '发证日期'])
data # 查看结果

在上面的代码中我们通过参数usecols筛选需要的列,这样可以避免读取不必要的数据,从而优化读取文件的速度并且减少内存的占用。除了将需要筛选的列名的列表传入参数usecols中,还可以传入列序号(从 0 计数)的列表,但是笔者认为传入列名的列表更实用,这样不需要记忆列的顺序。
现在我们来看上面得到的data的字段类型,使用代码data.dtypes得到结果如下:

我们在上一期文章中提到 Pandas 字段类型有助于我们检查数据的异常情况,从上图结果可以看到字段“发证年份”的类型为int64,而实际该列的数据类型更适合为字符型,而不是整型,并且从“发证日期”列的字段类型应该为日期,而上图结果中该列的字段类型为 object,这是有问题的。通常在确保数据本身没有错误的情况下,这种问题往往是由于 Pandas 在读取文件时会自动对列的类型进行推断而导致的。那么如何使得字段类型正确呢?除了通过 Pandas 提供的类型转换方法来转换 DataFrame 的字段类型(后面介绍),我们在读取 CSV 文件时也可以指定字段类型,代码如下:
data = pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv',
usecols=['企业名称', '证书编号', '发证年份', '发证日期'],
dtype={'发证年份':str, '发证日期':str}) # 设置 dtype=str 表示所有列均为字符型
data # 查看结果
在上面的代码中我们通过参数dtype指定各列的数据类型,传入该参数的是一个键为列名、值为数据类型的字典,我们将'发证年份'列的数据类型指定为字符型,现在再来看一下 DataFrame 的字段类型,结果如下:

可以看到'发证年份'列的字段类型已经转换为object,但是你应该注意到在参数dtype中我们并没有指定'发证日期'列的类型为日期,这是因为read_csv()函数中不支持直接指定日期数据类型,我们可以使用 pandas 中的to_datetime()函数将日期列转换为日期类型,代码如下:
data['发证日期'] = pd.to_datetime(data['发证日期'], format='%Y-%m-%d')
data.dtypes # 查看各列字段类型

此时'发证日期'列的字段类型已经转换为日期,to_datetime()函数的参数format用来指定日期格式,需要注意的是,在使用该函数时要保证数据中的日期格式与format指定的格式一致,否则转换不成功。
下面我们来看一下read_csv()函数的参数encoding,该参数用来指定读取 CSV 文件时所使用的字符编码格式。我们在读取示例 CSV 文件时并未指定参数encoding,这是因为read_csv()函数通常会使用'utf-8'编码格式读取 CSV 文件,如果文件采用了其他的编码格式,才需要通过参数encoding来指定。read_csv()函数支持的字符编码较多,常见的如下表所示。
| 编码格式 | 说明 |
|---|---|
| utf-8 | 一种 Unicode 编码格式(自行了解),支持所有语言,是目前最常用的编码格式 |
| utf-16 | 一种 Unicode 编码格式,支持所有语言,采用 16 位编码 |
| gbk | 一种中文字符集,又称“国标码”,支持简体中文和繁体中文 |
| gb2312 | 一种中文字符集,是 GBK 字符集的前身,支持简体中文 |
| iso-8859-1 | 又称“Latin-1”编码,支持欧洲语言中的大多数字符 |
比如我们现在想要读取一个使用'gbk'编码的 CSV 文件,就可以通过指定参数encoding来实现,代码如下:
pd.read_csv('./浙江省2021年第一批高新技术企业名单.csv', encoding='gbk')
在read_csv()函数中还有一个参数chunksize,这个参数的作用是在读取较大的 CSV 文件时允许数据分块读入。chunksize参数会读入指定块的数据并返回一个可迭代的对象,其中每次迭代返回指定大小的数据集,该数据集是一个 DataFrame 类型的对象,然后我们就可以对这个 DataFrame 进行处理分析,不需要将整个数据集一次读入内存,可以节省内存空间并且提高代码运行效率。如对这个参数感兴趣的可以自行了解,我们在这里就不多说了。
除了上面介绍的 CSV 文件,我们有时还会使用 TXT 这种文本文件来存储表格,与 CSV 文件不同的是 TXT 文件不能用 Microsoft Excel 打开,在常用的 Windows 操作系统中可以使用记事本打开,并且 TXT 文件扩展名为.txt。与 CSV 文件相同的是 TXT 文件也可以使用read_csv()函数来读取,现在我们有一个 TXT 文件(示例)如下:

TXT 文件通常没有表头,且这个 TXT 文件的两列之间以' - '作为分隔符,我们现在使用read_csv()函数读取这个文件,代码如下:
Data = pd.read_csv('./ENV_PerfGovernDisclose[DES][xlsx].txt', sep=' - ', header=None)
Data # 查看结果
结果如下:
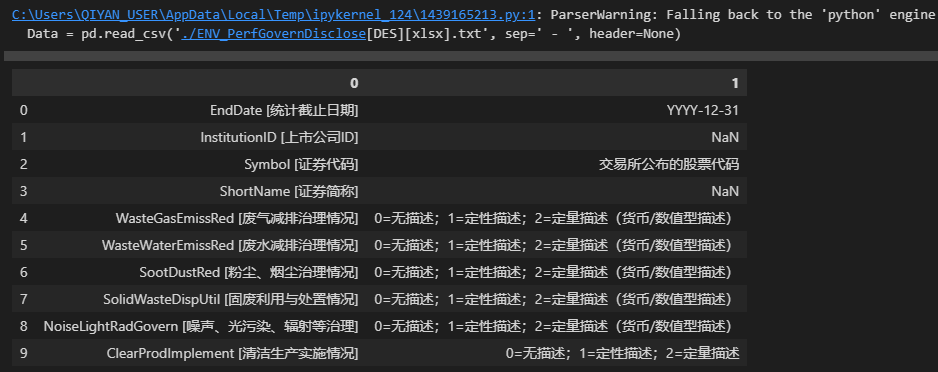
可以看到在上面代码中我们指定参数sep=' - ',-的左右两边各有一个空格,参数header=None是由于该 TXT 文件没有表头,如果不这样设置会默认将第一行数据作为表头。从上图可以看到 Python 解释器提示了警告信息:
ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
这个信息告诉我们,在使用read_csv()函数读取文件时指定了一个多字符的分隔符,并且这个分隔符不是标准的空格符\s,这种情况下 Pandas 默认的 c 引擎无法处理这个字符,会转而使用 python 引擎来解析,所以出现了警告信息。想要避免这个情况,只需要明确地告诉 Pandas 你要使用的是 Python 引擎,也就是指定read_csv()函数的参数engine='python'。
Part 4 Pandas 读取 Excel 表格
Excel 是一种常见的电子表格文件,与文本文件不同的是 Excel 表格可以设置数据类型(数值、文本、日期等)、公式和二进制形式存储的数据等,其由 Microsoft Excel 或其他兼容的电子表格软件创建,通常以.xlsx或.xls为扩展名。Pandas 中提供了read_excel()函数读取 Excel 文件,常见的参数如下表。
| read_excel 函数的常用参数 | 用法 |
|---|---|
| io | 必须参数,待读取的 Excel 文件路径 |
| sheet_name | 指定需要读取的工作表名或工作表序号,默认为第一个工作表 |
| header | 整数,指定作为表头的行,默认为0,即第一行为表头 |
| names | 用于将自定义的列名列表传递给 DataFrame 对象 |
| usecols | 用于筛选需要读取的列 |
| dtype | 字典,用于将指定的列的类型转换为指定的字段类型 |
可以注意到read_excel()函数的常用参数与read_csv()函数的常用参数相似,第一个参数io指定需要读取的文件路径,其他相同的参数这里就不多介绍了。不同的是读取 CSV 文件通常需要指定分隔符(默认为逗号,),而读取 Excel 文件通常需要指定读取的 sheet 表名或表序号(默认为第一个工作表)。
我们现在有一个 Excel 文件中有两个 sheet 表,Sheet1 为浙江省 2021 年的国家高新技术企业名单,Sheet2 为宁波市 2021 年的国家高新技术企业名单,现在我们使用read_excel()函数读取 Sheet2 中的内容,代码如下:
Data = pd.read_excel('./浙江省2021年第一批高新技术企业名单.xlsx', sheet_name=1, usecols=['企业名称', '证书编号','发证年份', '发证日期'])
Data # 查看结果

可以看到上面的代码中我们指定参数sheet_name=1时读取的是第二个 sheet 表,这是因为如果指定参数sheet_name时传入的是表的顺序,这时表的顺序从 0 开始计数,或者也可以直接指定表名来实现,本节示例中的 Excel 文件的表名为默认表名Sheet1和Sheet2,实现代码如下:
Data = pd.read_excel('./浙江省2021年第一批高新技术企业名单.xlsx', sheet_name='Sheet2', usecols=['企业名称', '证书编号','发证年份', '发证日期'])
需要注意一点,read_excel()函数不仅可以读取单个 sheet 表,也可以读取 Excel 文件中多个或全部 sheet 表,此时可以将需要读取的表名组成的列表传给参数sheet_name,这种情况下返回的结果是一个字典,字典的键为表名,字典的值为该表对应的 DataFrame,我们在这不过多介绍了。
Part 5 Pandas 读取 Stata 文件
Stata 文件是一种二进制文件格式,它是 Stata 软件的专属数据文件格式,以.dta为扩展名。与 CSV 文件和 Excel 表格不同的是 Stata 文件中包含了大量元数据(通俗来说,元数据就是用来描述数据的数据,也称为“中介数据”)信息,比如变量标签、值标签等等。Pandas 提供了用于读取 Stata 文件的read_stata()函数,下表为该函数中常用的参数。
| read_stata 函数的常用参数 | 用法 |
|---|---|
| filepath_or_buffer | 必需参数,待读取的 Stata 文件路径 |
| convert_categoricals | 读取数据值标签,默认为 True 表示将 Stata 文件中的类别变量转换为 Pandas 中的类别变量 |
| convert_missing | 是否将缺失值转换为 Stata 中的表示,默认为 False |
| preserve_dtypes | 是否保留 Stata 数据类型,为 False 时数值型数据会转换为 float64 或 int64 |
| columns | 选择需要读取的列 |
我们使用中国学术调查数据资料库CNSDA[1]提供的中国综合社会调查(2021)项目的原始数据(Stata 文件),来看一下用 Pandas 如何读取这个 Stata 文件(该数据可自行在网站下载)。
代码如下:
data = pd.read_stata('./656354229362/CGSS2021.dta', columns=['id','provinces','community_i','type','A00','A1','A011601'], preserve_dtypes=False, convert_missing=False)
data.head(8) # 查看结果,DataFrame的head属性在第六章介绍

在上面的代码中我们设置参数columns选择需要读取七列数据,设置参数preserve_dtypes=False表示不保留 Stata 的数据类型,原始数据的数值类型会向上转换为 Pandas 中的float64或int64类型,设置参数convert_missing=False表示原数据的缺失值使用 Pandas 中的 NaN 表示。我们可以使用代码data.dtypes看一下data的字段类型,结果如下:

可以看到'type'和'A011601'列的字段类型为category,这是因为参数convert_categoricals默认将 Stata 中的分类变量转换为 Pandas 中的类型变量。这个示例中的参数是 Pandas 读取 Stata 文件时常用的参数,此外也有别的参数可以使用,比如想要在 Pandas 中查看原始数据的变量标签时可以使用参数iterator来实现,我们在这里不多介绍了。
Part 6 DataFrame 的常用属性
在我们使用 Pandas 将数据读取为 DataFrame 后,通常需要对这个 DataFrame 做一些初步的验证,比如列名是否一致,数据量是否存在缺失等等,下面我们介绍几个 Pandas 提供的查看 DataFrame 基本信息的属性和方法,使用的数据集为上一节通过read_excel()函数读取的Data。
1、查看样本
当我们读取得到的 DataFrame 样本量较大时通常需要先查看部分样本,Pandas 提供了三个常用的属性来查看 DataFrame 的样本。
DataFrame.head(n)表示查看一个 DataFrame 的前 n 行,默认参数值为 5。现在我想要查看Data的前三行数据,代码如下:
Data.head(3)

DataFrame.tail(n)表示查看一个 DataFrame 的末尾 n 行,默认参数值为 5。现在我想要查看Data的末尾五行数据,代码如下:
Data.tail()

DataFrame.sample(n)表示随机抽取一个 DataFrame 的 n 行,默认参数值为 1。现在我们想要随机抽取Data的两行数据,代码如下:
Data.sample(2)

2、数据大小
如果我们想要了解读取数据集的行数和列数呢?Pandas 中使用DataFrame.shape查看数据的行、列数,执行该语句会返回一个元组,该元组的第一个元素为行数,第二个元素为列数,代码如下:
Data.shape
# 输出:(1393, 4),即该数据集共1393行4列3、数据基本信息
Pandas 中使用DataFrame.info()查看 DataFrame 各列的基本信息以及所占内存的大小等。现在我们想要查看Data的基本信息,代码如下:
Data.info()

观察上图,
-
第一行表示该数据是一个 DataFrame;
-
第二行中的 RangeIndex 表示该数据的行索引信息,从 0 到 1392;
-
第三行往下是该数据所有列的信息,Column 表示列名,Non-Null Count 表示该列中非空值的个数,Dtype 表示该列的字段类型;例如 Non-Null Count 下面的
1393 non-null表示这一字段共有 1393 个非缺失值,我们可以通过这个信息初步查看数据中各个字段的缺失情况。 -
最后一行的 momory usege 表示该数据在内存中所占用的空间大小。
除了上面三种信息,Pandas 中还有一个常用的函数DataFrame.describe(),其用于快速查看数值数据统计信息,函数返回的是数据各个数值列的数据分布和统计指标(最大值、最小值、中位数等等),这里我们不多介绍了。
Part 7 数据导出
当我们对读入的 DataFrame 进行处理分析后,就可以通过 Pandas 中的数据导出函数将数据写入文件,为了便于展示,此处所使用的数据为本文第四章中通过read_excel()函数读取的数据 Data,下面我们介绍 Pandas 中最常用的to_csv()和to_excel()这两个数据导出函数。
1、导出为CSV文件
下表列出了to_csv()函数的常用参数:
| to_csv 函数的常用参数 | 用法 |
|---|---|
| filepath_or_buffer | 保存 CSV 文件的路径 |
| sep | 指定列之间的分隔符,默认为 , |
| header | 指定是否将 DataFrame 的表头输出为文件的第一行,默认为 True |
| index | 指定是否将行索引输出到文件,默认为 True |
| columns | 指定要输出的列 |
| encoding | 指定文件编码 |
| mode | 指定文件写入模式,默认为 'w' 表示覆盖现有文件 |
上表列出的常用参数中大多数在介绍read_csv()函数时已经了解过了,这里就只说一下to_csv()函数的mode参数,该参数的常用取值是'w'和'a',当我们使用'w'模式写入时会覆盖现有文件,如果文件不存在就创建这个文件,使用'a'模式写入时会将数据追加到已存在的文件末尾,如果文件不存在就创建一个新文件。现在我们将数据Data输出为一个 CSV 文件,代码如下:
Data.to_csv('./output/NingBo_Province.csv', index=False, columns=['企业名称', '证书编号', '发证日期'])
输出得到的文件如下:

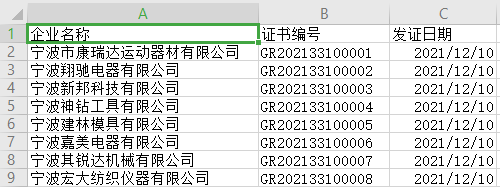
在上面代码中我们指定参数index=False来去掉索引,并且使用columns参数输出了数据Data的三列内容,其他参数使用默认值。除此以外,你也可以使用指定分隔符的参数sep等等。
2、导出为EXCEL文件
与写入 CSV 文件不同的是,使用to_excel()函数可能需要依赖第三方库 openpyxl,所以在使用该函数之前需要先安装依赖的库。下表列出了to_excel()函数的常用参数:
| to_excel 函数的常用参数 | 用法 |
|---|---|
| excel_writer | 要写入数据的 Excel 文件的路径 |
| sheet_name | 要写入数据的 Excel 工作表的名称,默认为 'Sheet1' |
| header | 指定是否将 DataFrame 的表头输出为文件的第一行,默认为 True |
| index | 指定是否将行索引输出到文件,默认为 True |
| engine | 可选参数,指定写入 Excel 时使用的引擎 |
上表中的excel_writer指定了需要写入的 Excel 的文件路径或文件对象,其中的文件名必须以.xlsx或.xls为扩展名,如果参数excel_writer所指向的文件已经存在,Pandas 会删除原文件并创建新的文件。参数engine用来指定写入 Excel 文件时使用的引擎,该参数的可选值为'openpyxl'或'xlsxwriter',具体如下。
-
engine='openpyxl':使用 openpyxl 作为写入引擎,可以处理 Excel2007 或更高版本的 .xlsx 格式文件,openpyxl 库有较好的兼容性,能支持较多的 Excel 文件格式 -
engine='xlsxwrite':使用 xlsxwrite 作为写入引擎,可以处理上一条提到的 .xlsx 文件,但是不支持 .xls 格式的文件,相较于 openpyxl 有更少的依赖关系,写入的速度更快
现在我们将数据Data输出为.xlsx为扩展名的 Excel 文件,代码如下:
# 输出扩展名为 .xlsx 的 Excel 文件
Data.to_excel('./output/Ningbo_Province.xlsx', index=False)
输出得到的文件如下:

上面代码中我们指定参数index=False来去掉索引,其他参数使用默认值。
如果我们想要将Data输出为.xls为扩展名的 Excel 文件呢?代码如下:
Data.to_excel('./output/Ningbo_Province.xls', index=False)

运行上面这个代码时提示了一条警告信息,这条信息建议我们使用 openpyxl 作为写入 Excel 文件的引擎,当前正在使用的 xlwt 引擎将在未来版本移除,也就是我们需要在使用to_excel()函数时设置参数engine='openpyxl'。
当我们想要将数据导出为 Excel 文件时,笔者建议导出为.xlsx文件,这种文件格式的兼容性更强,此时不需要设置参数engine。
Part 8 结束语
本期文章以读取文本文件、Excel 表格和 Stata 文件为例,详细为大家介绍了 Pandas 中的read_csv()、read_excel()和read_stata()函数,同时也介绍了几个 DataFrame 的常用属性,这可以让我们对数据情况有一个大致的了解,最后我们介绍了to_csv()和to_excel()这两个用于导出数据的函数,希望大家可以试一试用这些函数读取自己的文件,这样可以加深对函数参数的理解。下期再见。
Part 9 Python教程
-
本期内容
-
持续更新中...
参考资料
[1]中国学术调查数据资料库CNSDA: http://www.cnsda.org/index.php?r=projects/view&id=65635422














 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









