






更多详情请点击查看原文:企研数据处理工作论文系列 |【专利库】与【工商库】匹配报告
写在前面:
在2022年暑假期间,我们在公众号上连续推送了一系列关于数据库匹配的报告,引发了众多读者的热烈反响与好评。两年后的现在,我们的运营部门回顾了公众号过去的数据,发现在推送这些文章期间,公众号的活跃度达到了空前的高峰,这充分证明了这些文章的参考价值。
而最近,我们推送的一篇关于全量工商企业注册数据库质量检测的文章又获得了不少读者的认可(传送门:质量检测 | 对一份中国工商企业注册数据库的质量考察),加上这一年来我们也吸引了许多新朋友,我们决定趁热将过往发布的系列匹配报告重新推送给大家,让更多人收益。
感兴趣的读者,可以在我们的网页上直接获取PDF版匹配报告。
特别提醒:各位使用我们匹配结果的朋友们,我们对系列报告进行了编辑和编号(详情见PDF版匹配报告),已经是工作论文系列,可以直接引用。
图源:企研·学习专区(xue.qiyandata.com)
前 言
企业数据库之间的横向匹配,贯穿了企研数据团队的整个创业历程。自2018年始,各个数据库之间的匹配报告几易其稿,2020年疫情爆发之初的那个半年陆续完成。但囿于我本人的堕怠和一些顾虑,一直都没有最后定稿推送,这次发狠心一定要一口气把积攒的这几篇报告推送完成。这就是近期推送企业数据库匹配系列的来由,希望社科大数据公众号读者们批评指正。
——杨奇明(企研数据CEO)
2022年8月16日于杭州·海聚中心
中国专利数据库与全量工商企业注册数据库匹配报告
摘要:本文通过将中国专利数据库(以下简称“专利数据”)与中国全量工商企业注册数据库(以下简称“工商数据”)进行横向匹配,构建完整的“中国全量企业专利数据库”。相较于其他学者通过专利数据与中国规模以上工业企业数据库(简称“工企数据”)匹配得到的“中国规上工业企业专利数据库”,本文所构建的“中国全量企业专利数据库”涵盖了中国不同所有制,所有规模企业的专利信息,能够更加全面地刻画中国企业的专利创新。
一、数据库简介
(一)中国专利数据库简介
本文所使用的中国专利数据库来源于中国国家知识产权局,数据更新至2020年6月底,不含未通过形式审查(未公开)的专利。在三类专利当中,对实用新型和外观设计这两类而言,因只需进行形式审查,故本文所用专利数据中,它们均为已授权专利;而发明专利在公开后需要进一步进行实质审查,故本文所用发明专利数据包含部分已公开(即已通过形式审查)但(最终)未授权的专利。
根据《中华人民共和国专利法(2008修正)》(以下简称《专利法》)第三十四条之规定,通过形式审查的专利自申请日起满18个月即行公开,也就是说,专利从申请到公开最长需要18个月。故截至2020年6月底,2018年12月31日前申请的专利,若符合要求,原则上应当已经公开,即包含在本文所使用的专利数据中。然而,2019年之后申请的专利,可能有部分因暂未公开而不包含在本文所使用的专利数据中。为保证统计结果的完整性和稳定性,本文进一步剔除了2019年和2020年申请的专利。
综上所述,本文所使用的专利数据原则上涵盖1985-2018年在国家知识产权局申请并公开的所有专利。统计结果显示,三类专利共计24944220件,其中,发明专利10080621件(已授权发明专利3810776件),实用新型专利9580019件,外观设计专利5283580件。
《专利法》指出,专利申请权或者专利权可由两个及以上专利申请人共同拥有,即一件专利可由多个专利申请人共同申请,并共同享有其专利权。我们把这种有两个及以上专利申请人的专利简称为“共有专利”。经统计,1985-2018年的共有专利合计1444093件,约占专利总数的5.79%。可见,总的来说,共有专利的比例相对较小,并且从趋势上看这一比例自1996年以来相对较为稳定。
因后文匹配工作主要基于专利申请人的名称,故我们需要将共有专利的多个专利申请人进一步拆分成多条专利记录(这些专利记录除了专利申请人不同以外,其余专利信息均相同)。共有专利拆分以后,专利记录从原先的24944220条,增加到26812245条。
(二)中国工商企业数据库简介
本文所使用的工商数据来源于国家企业信用信息公示系统,由企研数据整理提供。截至2020年6月,该数据库包含了在各级市场监督管理部门登记的7055万家企业(含注吊销企业),图1显示了1978年以来中国企业每年新增、在营和退出数量的变化趋势。理论上,1985年以来申请专利的主体若是企业,均可以从该数据库中找到相应的登记注册信息。这保证了两大数据库横向匹配之后,理论上能够识别出1985年以来,中国企业的所有专利信息。
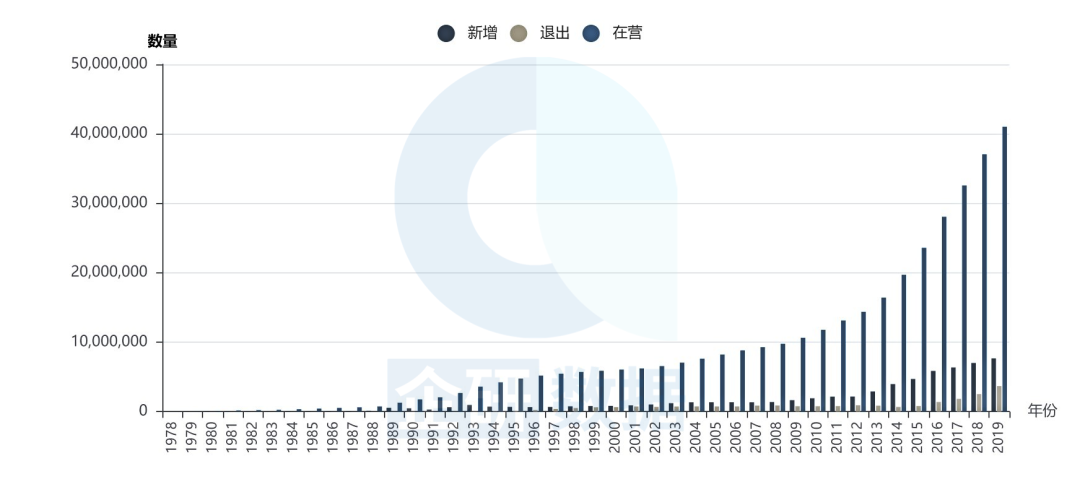
图1 1978-2019年中国每年新增、在营和退出企业数量的时间趋势
二、专利数据与工商数据匹配过程
(一)数据匹配流程
专利申请人名称是专利数据中可用于识别(企业)主体的唯一信息,也是专利数据与工商数据匹配的唯一桥梁。本文亦主要基于专利申请人名称和工商企业名称实现专利数据与工商数据的匹配,具体匹配流程如图2所示。
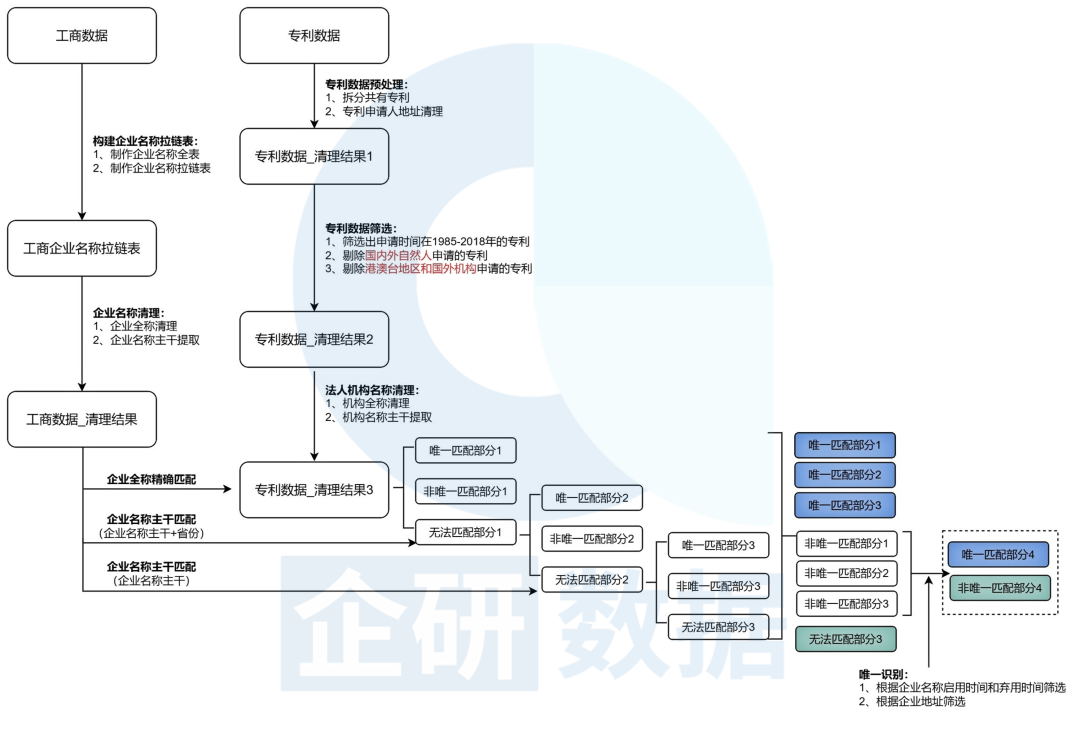
图2 专利数据与工商数据的匹配流程
(二)数据预处理
1. 专利数据筛选
本文所使用的专利数据,涵盖了1985-2018年各类专利申请主体在中国国家知识产权局申请并公开的所有专利。专利申请人包括国内外自然人、港澳台地区和国外的机构、国内(这里是指中国大陆地区的)机构。其中,国内机构(不含港澳台地区)又可进一步细分为企业、高校机构、科研院所、事业单位、社会团体等。本次数据匹配的目标主要是将由企业主体申请的专利识别出来,从而得到中国全量的企业专利数据库。为提高匹配的效率,在正式匹配数据之前,我们需要对专利数据中的样本做进一步筛选,具体步骤如下:
(1)剔除国内外自然人申请的专利
专利数据中的“申请人类型”指标,将专利申请人划分为“自然人”和“机构”两种类型。根据这一指标,可直接剔除由国内外自然人申请的专利。
(2)剔除港澳台地区和国外机构申请的专利
根据专利数据中的申请人地址信息(包括国别、省份、详细地址),可进一步识别并剔除港澳台地区和国外机构申请的专利。然而,由于专利数据中的申请人地址信息一般是根据主专利申请人的地址填报的。换句话说,共有专利的非主专利申请人的地址信息理论上是无法从该条专利中获取的。而前文在处理共有专利的时候,我们将多个专利申请人申请的专利,拆分成了除专利申请人不同以外,其余专利信息均相同的多条专利记录,即共有专利的非主专利申请人的地址信息按照主专利申请人地址信息进行填充。这种做法不仅会影响前期的数据筛选,导致部分专利申请人被误认为港澳台地区和国外机构,进而被误删,也会影响后续数据匹配的准确性。因此,我们需要对专利申请人地址做进一步调整。具体做法如下:
首先,我们将非主专利申请人的地址信息统一替换为空值。然后,根据已有的专利信息对部分非主专利申请人的地址信息进行补充(非主专利申请人在申请其他专利时,可能是主专利申请人)。这种情况下,当专利申请人名称一致时,我们可以用其他专利的主专利申请人的地址信息对该条专利的非主专利申请人地址信息进行补充。最后,再根据调整后的专利申请人地址,剔除港澳台地区和国外机构申请的专利。值得注意的是,部分非主专利申请人的地址信息无法通过前文的方式进行补充,为防止数据遗漏,这部分记录我们选择保留下来,进入后续匹配流程。
需要说明的是,因目前暂无有效方法可直接剔除非企业主体(如高校机构、科研院所、事业单位、社会团队等)申请的专利,故这部分信息暂不处理。根据申请人类型,筛选得到20000100条国内外机构申请的专利,其中主专利申请人申请的专利共计18716058条,非主专利申请人申请的专利共计1284042条。通过调整申请地址,最终仅剩150836条专利的地址仍然缺失。剔除明确为港澳台地区和国外机构申请的专利,剩余17256109条国内机构申请的专利。
2. 构建企业名称拉链表
专利数据与工商数据匹配的关键在于完整可靠的企业名称[1]。然而,企业在经营发展过程中,可能会发生企业名称的变更,这给我们的匹配工作带来了巨大的挑战。值得庆幸的是,按照相关的规定,市场监管部门应对所有工商企业的变更信息进行登记,包括企业名称、注册地址、法人名称等的变更信息。因此,理论上,我们可以通过工商数据中的企业名称变更信息,追溯每一家企业在其存活期间所使用的所有企业名称,构建所谓的企业名称拉链表。我们在接下来的匹配中,将会使用企研数据提供的中国全量工商企业名称拉链表。
[1] 为方便后文表述,我们将专利数据中的机构专利申请人名称和工商数据中的工商企业名称,统称为“企业名称”。
企业名称拉链表的具体制作过程如下:
(1)在企业唯一识别的基础上,制作企业名称全表。
工商数据涵盖了在中国大陆地区各级市场监管部门登记的所有工商注册企业,包括当前存活的企业以及已退出(注吊销)的企业。然而,在这套来源于行政记录的数据中,并不存在一个变量可以唯一识别一家企业[2]。因此,我们首先要为每一家工商企业赋予一个唯一识别的企业ID,并制作企业名称全表。企业名称全表涵盖了所有工商企业的所有名称信息,包括企业的现用名和历史曾用名,以及每个名称所对应的企业ID。该表中的企业名称和企业ID是多对多的关系。原因在于,企业在经营发展过程中,可能会发生企业名称的变更,而企业ID是企业的唯一身份识别编码。因此,同一个企业ID会对应多个企业名称。另一方面,同一个企业名称也可能在不同历史时期被不同企业所使用,因而也会出现一个企业名称对应多个企业ID的情况(企业名称无法唯一识别一家企业)。
[2] 这里为什么不使用统一社会信用代码作为企业的唯一识别ID呢?2015年10月1日,营业执照、组织机构代码证和税务登记证“三证合一”,随后以统一社会信用代码作为机关、团体和企事业单位的唯一标识。成立时间在“三证合一”之前,且死亡时间在“三证合一”之后(或持续存活)的企业,可通过换证的形式获取统一社会信用代码。而那些成立和死亡时间都在“三证合一”之前的企业,则没有统一社会信用代码。我们的匹配任务显然需要追溯到“三证合一”之前就已经退出的企业,因此统一社会信用代码不宜作为企业的唯一识别ID。为此我们重新编制了一套企业唯一识别ID编码,编制过程较为复杂,在此不作赘述。
(2)根据工商企业名称变更信息,制作企业名称拉链表。
如前文所述,同一个企业ID在不同时期可能对应多个企业名称,同一个企业名称也可能在不同时期归属不同企业从而对应多个企业ID。那么该如何确定某一企业ID所对应的企业名称在哪个时间段内是有效的呢?为解决这一难题,我们根据工商企业的名称变更信息(企业名称发生变更是企业信息变更中的一种情况,包含了变更的时间),制作了企业名称拉链表,表格包含了任一企业ID所对应的任一企业名称的启用时间和失效时间。
3. 企业名称清洗
在专利数据与工商数据的匹配过程中,不仅需要应对企业名称变更的情形,还需要考虑企业名称登记不规范的情况。企业名称登记不规范,使得同一家企业在不同数据库中的登记名称不完全相同,从而无法匹配。因此,在正式匹配之前,需要对两个数据库中的企业名称(对专利数据而言是申请主体的名称)做相同规则和步骤的数据清理,清理后企业全称和企业名称主干[3]方可先后用于横向匹配。
通过上述清理步骤,1985-2018年17256109条国内机构申请的专利,所涉及的专利申请主体(企业全称)由原来的980895个(企业全称清理前)调整为969440个(企业全称清理后),并从中提取出921097个企业名称主干。
[3] 详情可参见施丹燕, 杨奇明. 中国专利数据库与中国工业企业数据库匹配报告. 企研数据处理工作论文系列, 2022, No.WP0002. http://paper.qiyandata.com/WP0002.pdf.
(三)数据匹配过程
1. 企业全称精确匹配
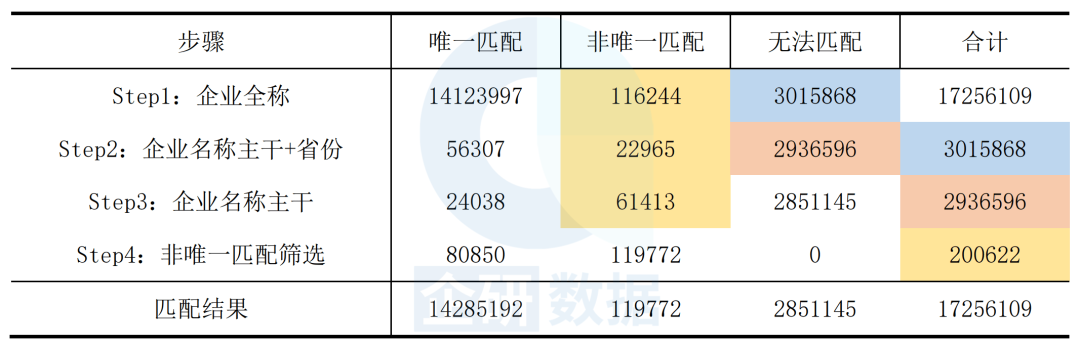
基于清洗后的企业全称,将专利申请人名称与(企业名称被以同样规则清洗之后的)企业名称拉链表进行匹配。其中,能够与拉链表企业全称实现唯一匹配[4]的专利申请人名称共计865472个,涉及专利14123997条;非唯一匹配的专利申请人名称共计5345个,涉及专利116244条;无法匹配的专利申请人名称共计98623个,涉及专利3015868条。
[4] 唯一匹配是指同一个专利申请人名称在企业名称拉链表中仅匹配到一个企业ID。非唯一匹配则是指同一个专利申请人名称在企业名称拉链表中匹配到两个及以上的企业ID。而无法匹配是指专利申请人名称不存在于企业名称拉链表之中。
2. 企业名称主干精确匹配
(1)企业名称主干+省份
根据清理得到的企业名称主干,我们将无法通过企业全称精确匹配的那3015868条专利数据,再次与企业名称拉链表进行匹配。因前文提取企业名称主干时,不仅剔除了地址信息,还剔除了“总公司,分公司,总院,分院,总部,分部,总厂”等总(分)机构标识的词汇。为了解决总分机构专利的错匹问题,本文在企业名称主干匹配的过程中,同时限定地区,即要求专利的申请地址与企业注册地在同一省份。基于“企业名称主干+省份”精确匹配,进一步实现56307条专利的唯一匹配,22965条专利的非唯一匹配,剩下2936596条无法匹配的专利,进入下一个匹配环节。
(2)企业名称主干
我们进一步放松匹配的约束条件,仅基于清理后的企业名称主干进行匹配,不再限定省份(事实上,如前文所述,本文所使用的专利数据有部分专利的申请地址是缺失的,限定省份将导致这部分专利无法通过“企业名称主干+省份”与工商库实现匹配)。基于“企业名称主干”精确匹配,进一步实现24038条专利的唯一匹配,61413条专利的非唯一匹配,剩下2851145条无法匹配的专利。
3. 非唯一匹配结果筛选
同一个企业名称可能在不同时期被不同企业所使用,因而会出现一个企业名称对应多个企业ID的情况,也就是所谓的“非唯一匹配”。那么该如何确定某一企业ID所对应的企业名称在哪个时间段内是有效的呢?企业名称拉链表不仅包括了每个企业ID所对应的所有企业名称(含现用名和历史曾用名),还包括了每个企业ID所对应的任一企业名称的启用时间和失效时间,可用于辅助识别非唯一匹配结果。根据“启用时间<=申请时间<授权时间(若有)<=失效时间(若有)”这一逻辑,我们进一步识别出80850条专利。
三、匹配结果及进一步考察
1985-2018年国内机构申请的专利共计17256109条,其中能够与工商数据实现唯一匹配的共计14285192条,占比82.78%。各步骤匹配结果如表1所示。
表1 专利数据和工商数据匹配结果
根据专利申请人名称,可将机构专利申请人大致划分为教育机构、医疗机构、科研机构、行政机关、社会团体等非企业主体和企业主体,如表2所示。无法匹配的2851145条专利中,有2582971条是由国内非企业主体申请的。剔除这部分专利后,1985-2018年专利申请总量调整为14673138条,与工商库的匹配率达到97.36%。从趋势上看,匹配率逐年上升,自2002年起,每年的匹配率都超过了90%。
表2专利数据中无法与工商库匹配的专利情况分析

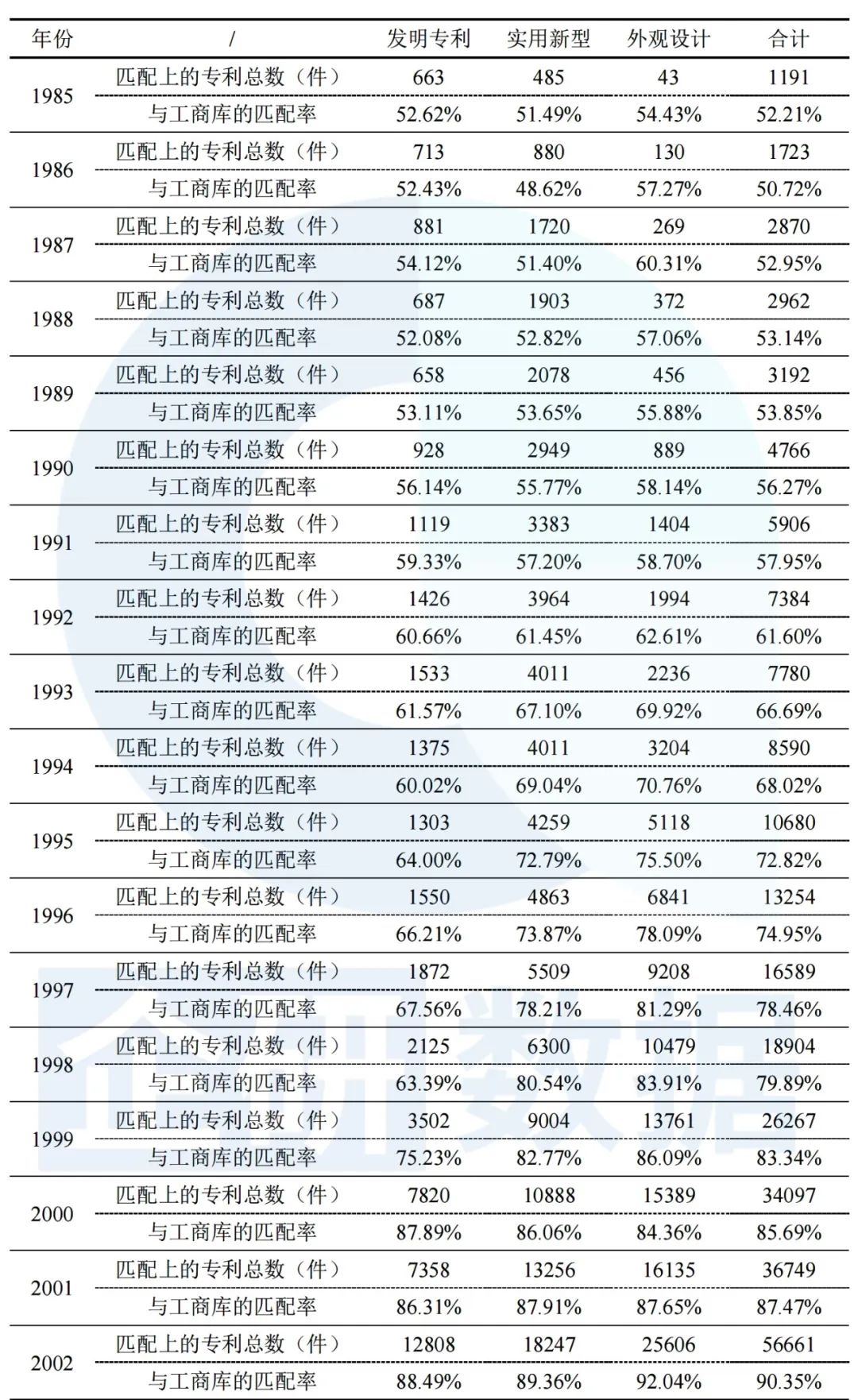
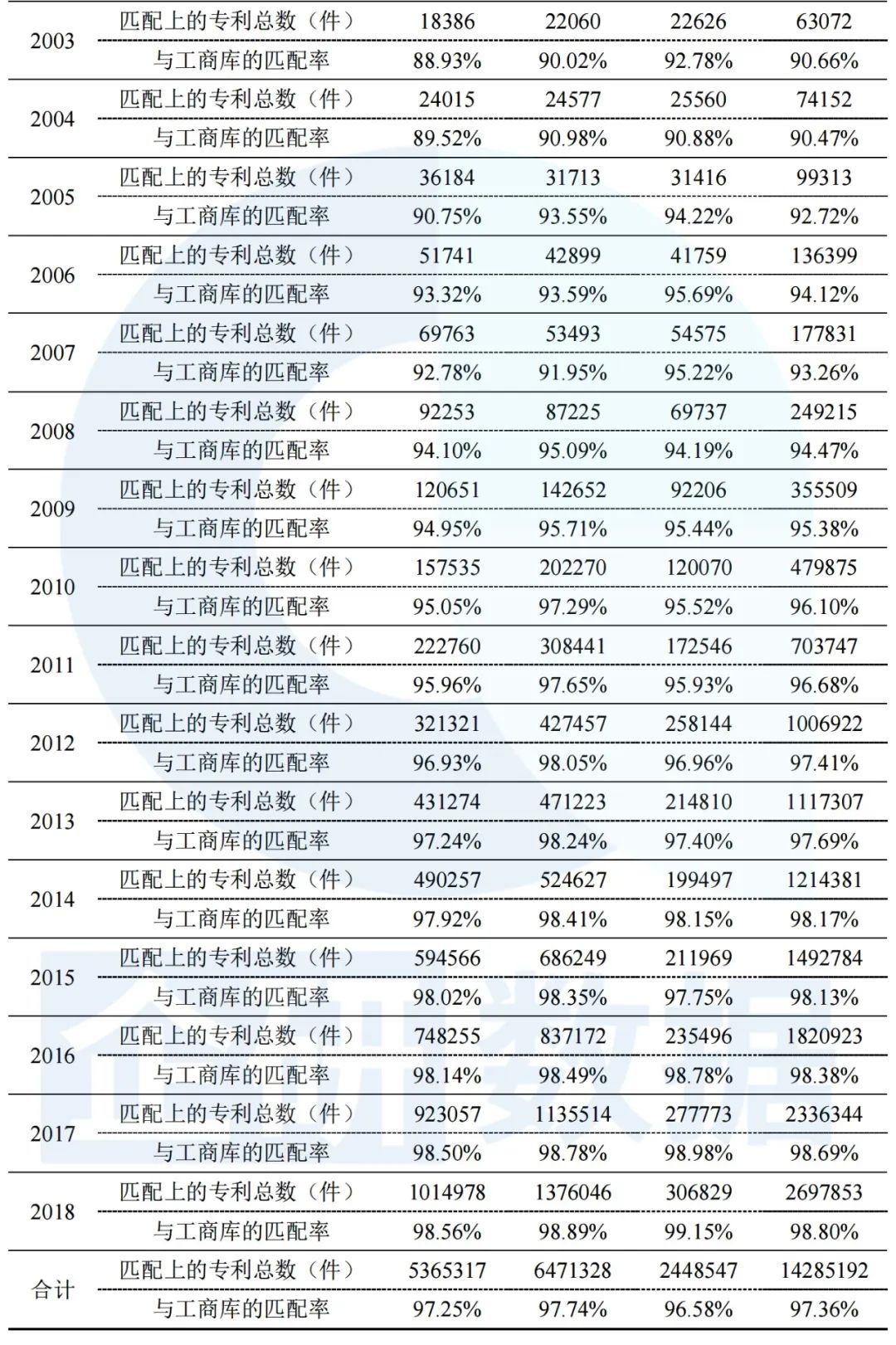
根据专利的申请日期,我们对发明专利、实用新型和外观设计三类专利的匹配结果进行分年统计(结果如表3所示)。总的来看,三类专利匹配率均大幅度上升,平均匹配率差异较小。
表3 1985-2018年三类专利的匹配结果

















 2443
2443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









