






更多详情请点击查看原文:企研数据处理工作论文系列 |【专利库】与【工企库】匹配报告
写在前面:
在2022年暑假期间,我们在公众号上连续推送了一系列关于数据库匹配的报告,引发了众多读者的热烈反响与好评。两年后的现在,我们的运营部门回顾了公众号过去的数据,发现在推送这些文章期间,公众号的活跃度达到了空前的高峰,这充分证明了这些文章的参考价值。
而最近,我们推送的一篇关于全量工商企业注册数据库质量检测的文章又获得了不少读者的认可(传送门:质量检测 | 对一份中国工商企业注册数据库的质量考察),加上这一年来我们也吸引了许多新朋友,我们决定趁热将过往发布的系列匹配报告重新推送给大家,让更多人收益。
感兴趣的读者,可以在我们的网页上直接获取PDF版匹配报告。
特别提醒:各位使用我们匹配结果的朋友们,我们对系列报告进行了编辑和编号(详情见PDF版匹配报告),已经是工作论文系列,可以直接引用。
图源:企研·学习专区(xue.qiyandata.com)
前 言
企业数据库之间的横向匹配,贯穿了企研数据团队的整个创业历程。自2018年始,各个数据库之间的匹配报告几易其稿,2020年疫情爆发之初的那个半年陆续完成。但囿于我本人的堕怠和一些顾虑,一直都没有最后定稿推送,这次发狠心一定要一口气把积攒的这几篇报告推送完成。这就是近期推送企业数据库匹配系列的来由,希望社科大数据公众号读者们批评指正。
——杨奇明(企研数据CEO)
2022年8月16日于杭州·海聚中心
中国专利数据库与中国工业企业数据库匹配报告
Part1 引言
创新是现代经济保持长期增长的根本动力,企业是现代社会创新的主体,是微观领域创新研究的主要分析对象。早期人们以研发投入(R&D)作为企业创新的衡量指标,但R&D指标在内涵、数据的可得性和准确性方面都存在局限性,具体来说:首先,企业创新不仅受研发资金投入的影响,还受到研发组织能力、研发人才整合效率和研发思路等非经济因素的影响。因此,R&D作为创新资金投入,无法准确衡量企业的实际创新产出(周煊等,2012);其次,R&D这一指标的可得性较差,实证研究只能限定在上市公司这类有限的企业样本上。近年来研究中国企业创新等微观行为的常用数据库——中国工业企业数据库,也只有少数年份收集了R&D这一指标。最后,也有部分学者对R&D本身的准确性提出质疑(周煊等,2012;Griliches,1990)。
为弥补R&D这一指标的不足,随着数据可得性的增加,许多学者开始使用专利数据这一创新产出指标来衡量企业的创新水平。相较于R&D,专利数据至少存在如下三点优势:① 专利是企业的创新产出,而非创新投入,是衡量企业技术创新的有效指标;② 专利数据具有可得性、权威性和及时性的优势。在中国,由国家知识产权局统一负责境内个人和机构的专利申请和审核事宜,相关信息及时公开,所形成的覆盖所有境内企业的专利库,来源权威可靠且方便更新;③ 专利数据包含专利分类号、法律状态等多维度信息,可用于深入研究企业创新行为。
当然,全面研究企业的创新行为、创新效率等问题,作为创新产出的专利数据只是其中一个维度,我们需要匹配企业特征、经营状况等信息方能开展深入研究。因此,近年来不少学者试图将企业专利数据与其他企业微观数据进行匹配,构建更加完整的企业创新微观数据库。
本文讨论的主题是如何将中国专利数据库(以下简称“专利库”)和近年来被广泛使用的规模以上工业企业数据库(以下简称“工企库”)进行匹配的问题,总结已有专利库和工企库匹配方案的优劣势,在此基础上,提供一套进一步改进的匹配方法,获得一套匹配更为精准的数据。
Part2 已有方法梳理与本文思路
1、已有方法梳理
因数据的限制,早期中国专利相关的实证研究主要基于省级或行业层面的专利汇总数据,以及部分地区或者特定研究主体(包括上市公司、外商投资企业等)的专利微观数据,近年来才开始出现全国层面的微观专利数据和工企数据的匹配和应用。本节先对当前已有的几个代表性匹配思路进行梳理总结,探讨其优劣势,并在此基础上尝试做进一步的改进。
文献的梳理发现,在专利库与工企库匹配方面,目前Xie&Zhang(2015)、He et al.(2018)[1],以及寇宗来和刘学悦(2020)[2]的匹配方法最具代表性。表1概述了上述三篇文献各自的匹配思路和处理过程(包括匹配流程的设计和匹配算法的选择)。
表1 部分代表性研究匹配思路概述
| 作者 | 匹配思路 | 处理过程 |
|---|---|---|
| Xie&Zhang(2015) | 以企业名称为桥梁,逐年匹配 | 1、对企业名称进行数据清洗,得到“企业简称”; 2、基于“企业简称”,逐年进行精确匹配。 |
| He et al.(2018) | 以企业名称为桥梁,多年合并匹配(ever-match) | 1、利用其他资料,对工企库中缺失的企业名称进行补充; 2、筛选专利样本,以提高匹配效率; 3、对企业名称进行预处理,得到“企业简称”; 4、基于“企业简称”,利用左对齐严格子字符串匹配算法,多年合并精确匹配; 5、人工校验。 |
| 寇宗来和刘学悦(2020) | 以企业名称为桥梁,逐年匹配(contemporaneous match) | 1、利用其他资料,对工企数据中缺失的企业名称进行补充; 2、剔除自然人申请的专利; 3、对企业名称进行数据清洗,并依次得到“企业全称”、“企业简称”与“企业关键词”; 4、精确匹配,包括“企业全称”精确匹配和“企业简称”精确匹配; 5、模糊匹配,基于编辑距离算法(Levenshtein Distance),根据“企业关键词”进行模糊匹配; 6、人工检查。 |
接下来,我们从企业识别核心变量(主要是企业名称)处理、匹配思路、匹配流程设计和匹配算法四个方面对这几篇典型文献处理方法和思路优劣势进行比较说明:
(1)企业识别核心变量——专利申请人名称(企业名称)——的处理。专利申请人名称是专利数据中可用于企业识别的唯一信息,亦即专利库与工企库匹配的唯一桥梁。因此,专利申请人名称和工业企业名称的准确规范将直接影响最终的匹配结果。上述三篇文献在实际匹配之前,都对企业名称做了不同程度和不同方式的预处理,包括剔除标点符号、“有限责任公司”、“有限公司”等非企业识别的关键性元素。相较而言,在具体处理细节上,寇宗来和刘学悦(2020)考虑得更加全面,不仅排除了符号、字母、数字(阿拉伯与汉语)在编码和表现形式上的干扰,更对非企业识别的中文字符串进行了扩充。[3]
(2)在匹配思路上,He et al.(2018)采用多年合并匹配的方法,而Xie&Zhang(2015)、寇宗来和刘学悦(2020)则选择逐年匹配的方法。本文认为,这两种方法各有优劣。
首先,多年合并匹配(ever-match)的关键优势在于,工企库中只要有一年正确记录了企业名称,那么所有相关专利都将被找到并匹配,这可以在一定程度上解决企业名称书写错误和名称变更导致无法匹配的问题。换句话说,ever-match基于工企库中的组织机构代码,简单地构建了一张1998-2013年的规上工业企业历史名称清单。此外,ever-match匹配方法允许研究人员随时间的推移跟踪一家企业的专利组合,即使该企业在这期间因未满足“规模以上”的阈值要求[4],曾退出工业企业数据库。在附录中,我们以“四川康达建材工业(集团)公司”为例,对这种方法做简单的介绍。ever-match匹配方法也有其局限性,主要体现在以下几个方面:① 基于工企库构建的规上工业企业历史名称清单可能并不完整。若想通过ever-match来解决企业名称书写错误和名称变更的问题,这就要求在1998-2013年期间,某一年名称书写有误的规上工业企业,在其他年份书写正确。同时要求1998-2013年的工企库涵盖了这期间规上工业企业的所有历史名称。事实上,因为只有当企业的主营业务收入达到“规模以上”阈值时,才能被纳入规上工业企业数据库,故很难保证数据库中的所有工业企业均满足上述要求。② 基于工企库所构建的工业企业历史名称清单,其准确性主要依赖于其组织机构代码识别的准确性。换句话说,对工企库的纵向识别是构建工业企业历史名称清单的基础。纵向识别的偏误,将直接影响专利库与工企库的匹配结果;③ ever-match采用多对多的匹配方式,不仅直接增加了计算机的运算压力,而且容易造成过度匹配。这里的过度匹配是指,由于存在企业名称变更的情况,故同一个企业名称,在不同年份可能属于不同企业主体,ever-match匹配方法将多年数据合并匹配,可能导致那些在不同时间使用同一企业名称的不同企业主体被错误地匹配到一起。该方法提高匹配率的同时,增加了错误匹配的概率。
其次,逐年匹配(contemporaneous match)的方法也有其合理性。相较于ever-match,它不依赖于工企库的纵向识别,这消除了不同年份间数据错误匹配的可能性。但直接分年匹配需要一个前提,即给定年份,因名称变更而导致无法匹配的概率不高。但事实上,因名称变更而导致无法匹配的的情况并不罕见(详细案例将在后文展开介绍)。并且,逐年匹配未充分利用工企库中历年的企业名称信息,无法解决企业名称变更和书写错误这两种情况所引起的漏匹。总之,逐年匹配虽然增加了数据匹配的精度,但也因此降低了匹配率。
(3)在匹配流程设计上,Xie&Zhang(2015)和He et al.(2018)采用了基于“企业简称”的精确匹配,而寇宗来和刘学悦(2020)则在此基础上,设计了更加复杂精细的匹配流程,在“企业简称”精确匹配前,增加了“企业全称”精确匹配,用于提高匹配精度。
值得指出的是,寇宗来和刘学悦(2020)还在“企业简称”精确匹配后,增加“企业关键词”的模糊匹配,从而进一步提高匹配率。但也正是这个模糊匹配带来了相应的问题。模糊匹配提高了匹配率,但同时也增加了错误匹配的概率。而这种错误匹配需要通过投入大量的时间和人力来进行手工检查消除。而且以往的经验证据也表明,模糊匹配所带来的匹配度的提高其实是非常有限的。此外,百万级别的数据量进行模糊匹配,也会给计算机的运算能力带来极大挑战(He et al.,2018)。
(4)在匹配算法上,He et al.(2018)采用了左对齐严格子字符串匹配算法(left-aligned strict substring matching)(以下简称“左对齐”),即当工业企业名称是专利申请机构名称的左对齐严格子字符串,则匹配成功。寇宗来和刘学悦(2020)则创造性地将编辑距离算法(Levenshtein Distance)应用于专利库与工企库的匹配过程中。编辑距离是指一个字符转换成另一个字符所需要的最少的编辑操作次数。编辑距离算法认为,字符的编辑距离越短,它们的相似度越高(关于相似度的更多算法参见推文《用文本相似度算法为中国工业企业数据库筛选重复样本》)。寇宗来和刘学悦(2020)将高相似度的企业名称匹配到一起。上文提到,这种两种匹配算法在提高匹配率的同时,均以牺牲匹配精度为代价,后续都需要投入大量人力进行校验。
2、本文匹配思路
文献回顾表明,在核心识别变量处理、匹配思路、流程设计和算法选择上,已有研究所采用方法各有优劣。通过利弊权衡,本文最终选择的匹配思路和流程方案如下:(1)匹配思路上采取逐年匹配的方法,以避免不同年份之间数据错匹的问题;(2)在匹配流程上,主要参考寇宗来和刘学悦(2020)的设计方案,采用先“企业全称”精确匹配、后“企业简称”(考虑到技术细节不同,我们称之为“企业名称主干”)精确匹配两个环节,但是摒弃了基于“企业关键词”和编辑距离算法的模糊匹配,以确保匹配结果的准确可靠。
特别要强调的是,与已有文献最大的区别是,为解决企业名称书写错误和名称变更导致漏匹的情况,提高匹配率,本文首次增加了中国工商企业数据库(以下简称“工商库”)补充匹配这一环节,可以取得比多年合并匹配(ever-match)更好的效果,同时又避免了其所带来的问题。总体思路是,先以企业名称(主干)为桥梁,逐年匹配了1998-2013年的专利库和工企库,然后通过工商库对企业名称书写错误和名称变更这两种情况所引起的漏匹做进一步补充。具体匹配流程如下:
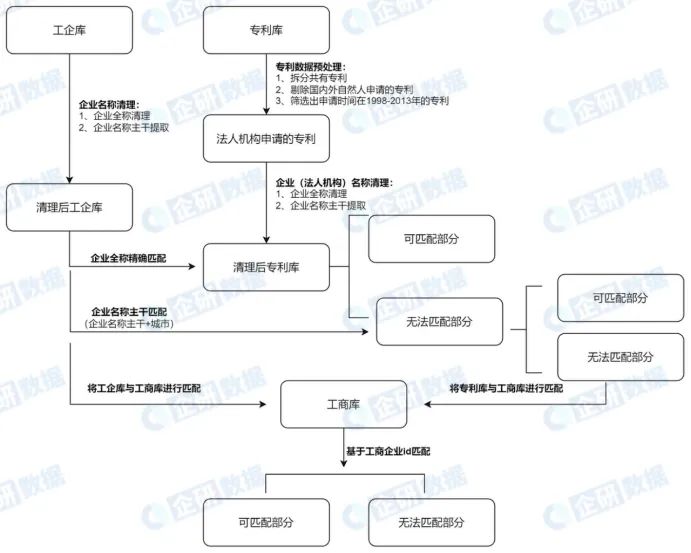
图1 专利库与工企库的匹配流程
Part3 具体处理过程
1、数据预处理
专利数据预处理
本文所使用的专利库来源于中国国家知识产权局,不含未通过形式审查(未公开)的专利。在三类专利当中,对实用新型和外观设计这两类而言,因只需进行形式审查,故本文所用专利数据中,它们均为已授权专利;而发明专利在公开后需要进一步进行实质审查,故本文所用发明专利数据包含部分已公开(即已通过形式审查)但未授权的专利。
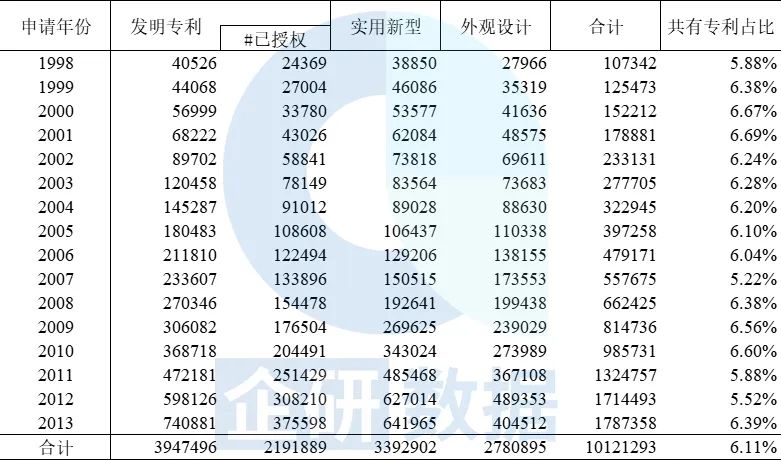
根据专利的申请日期,我们对这三类专利的申请和授权情况进行分年统计,具体结果如表2所示。其中,最后一列为每年的专利申请中共有专利占比的情况。《专利法》指出,专利申请权或者专利权可由两个及以上专利申请人共同拥有,即一件专利可由多个专利申请人共同申请,并共同享有其专利权。我们把这种有两个及以上专利申请人的专利简称为共有专利。因后文匹配工作主要基于专利申请人的名称,故我们需要将共有专利的多个专利申请人[5]进一步拆分成多条专利记录,这些专利记录除专利申请人不同外,其余专利信息均相同。
表2 1998-2013年国内外三类专利的申请和授权情况
在对专利库与工企库进行匹配之前,我们可以对专利库中的如下样本进行剔除:(1)国内外自然人申请的专利。根据“专利申请人类型”[6]指标,可直接剔除国内外自然人申请的专利;(2)港澳台地区和国外机构申请的专利。寇宗来,刘学悦(2020)根据“专利申请人地址”指标,剔除了申请地址为国外或港澳台地区的专利记录。但由于专利库中的专利申请地址一般是根据主专利申请人的地址填报的。故寇宗来,刘学悦(2020)的操作方法将导致主专利申请人地址是国外或者港澳台地区,但其他专利申请人为国内机构的专利信息也一并被删除了,从而导致数据缺失。故本文在匹配之前,对这部分数据暂不处理;(3)其他非规模以上工业企业申请的专利,具体包括:① 国内事业单位、行政机关等非企业机构;② 非工业企业;③ 规模以下工业企业这四类主体申请的专利。因目前暂无有效识别这三类主体的现成的指标[7],故本文在匹配之前,暂不做相应处理。通过以上步骤,最终筛选得到7400256条申请时间在1998-2013年期间的专利记录。其中发明专利共计3641041条(已授权发明专利2192015条),实用新型专利2274166条,外观设计专利1485049条。
企业名称的清理
尽管工企库中的组织机构代码和企业名称都可用于企业识别,但专利库中可用于企业识别的信息只有专利申请人名称。因此,企业名称是专利库和工企库匹配的唯一桥梁。然而,企业名称登记不规范,使得同一家企业在两个数据库中的登记名称不完全相同,从而给我们的匹配工作带来挑战。与Xie&Zhang(2015)、He et al.(2018),以及寇宗来和刘学悦(2020)的处理方式一致,在正式匹配之前,先对两个数据库中的企业名称做相同的数据清理,得到清理后的企业全称和企业名称主干(上文已经提及,本文清理细节有别于上述文献,因此不称其为企业简称,以示区别)。
(1)企业全称清理
通过对Xie&Zhang(2015)、He et al.(2018),以及寇宗来和刘学悦(2020)做法的总结与整合,得到以下清理步骤:
① 全半角的转换
a. 全角状态下的字母统一转换成半角状态,即将“ABC…Z”依次替换为“ABC…Z”,将“abc…z”依次替换为“abc…z”;
b. 全角状态下的阿拉伯数字统一转换成半角状态,即将“0123…9”依次替换为“0123…9”;
c. 全角状态下的符号统一转换成半角状态,即将“!”#$%&’*+-,./<>=?@{}|~”依次替换为“!”#$%&’*+-,./<>=?@{}|~”;
d. 全角状态下的空格符统一转换成半角状态,即将“ ”替换为“ ”。
② 汉语数字统一转换成阿拉伯数字
即将汉语数字“〇零一二…九”依次替换为“0012…9”。
③ 括号格式的统一
即将“(){}[]【】〔〕<>《》”统一替换为“()”。
④ 符号和空格符的剔除
即将“!”#$%&’*+-,./<>=?@{}|~()”和“ ”剔除。
(2)企业名称主干提取
一般而言,企业全称主要由4个部分组成,其命名规则大致为:【地区冠名】+【企业取名】+【行业属性】+【企业类型】。其中,【企业取名】+【行业属性】 是企业名称的主干部分(为了区分已有的称呼,我们称之为“企业名称主干”),是企业身份识别的关键性元素,一般而言登记时误填的可能性不高。而【地区冠名】 和【企业类型】 这两个部分因非企业识别的关键性元素而常被误填或漏填,进而影响企业名称匹配的效果。因此,我们进一步在清理后的企业全称的基础上,剔除容易出错的干扰因素,进而提取出企业名称主干,具体步骤如下:
a. 剔除【地区冠名】
寇宗来和刘学悦(2020)在提取企业名称关键词的时候,使用2013年版的中国区县以上行政区划代码(GB T2260-2013),按顺序依次删除名称中的省、市、区县地址的简称。考虑到1998-2013年期间存在行政区划的变更,本文使用中华人民共和国民政部公示的1980-2013年的中国区县以上行政区划,将企业全称中省份和城市相关的地址信息剔除[8];
b. 剔除【企业类型】
依次剔除“有限,责任,股份,集团,总公司,分公司,公司,总院,分院,总部,分部,总厂,厂”等企业类型相关字样。
以“企研数据科技(杭州)有限公司”为例,依次剔除【地区冠名】“杭州”和【企业类型】“有限公司”,得到企业名称主干“企研数据科技”,其中“企研数据”是【企业取名】,“科技”则反映了【行业属性】。
通过上述清理步骤,1998-2013年7400256条专利所涉及的专利申请主体(企业全称)由原来的517586个(企业全称清理前)调整为507828个(企业全称清理后),并从中提取出475679个企业名称主干。
2、匹配过程
企业全称精确匹配
基于清理后的企业全称,逐年匹配1998-2013年的专利数据与工企数据。因同一年同一家工业企业可能申请多条专利,故每年的匹配结果均呈现一对多的情况,即工企数据:专利数据=1:m。
企业名称主干精确匹配
根据清理得到的企业名称主干,我们将无法通过全称精确匹配的那部分专利数据,再次与所有工企数据进行逐年匹配。因前文提取企业名称主干时,不仅剔除了省份和城市相关的地址信息,还剔除了“总公司,分公司,总院,分院,总部,分部,总厂”等总(分)机构标识的词汇。为了解决总分机构专利错匹的问题,本文在企业名称主干匹配的过程中,同时限定地区,即要求专利的申请地址与工业企业在同一城市。换句话说,我们认为作为一家工业企业,在同一城市设立总分支机构或设立多家分支机构的概率不高。
利用工商库补充匹配
步骤(1)和(2)无法完全解决企业名称书写错误的问题,更无法解决名称变更所引起的漏匹。寇宗来和刘学悦(2020)采用编辑距离算法,尝试以模糊匹配的方式,对精确匹配的结果做进一步补充。然而,这种方法无法解决企业名称变更所带来的遗漏匹配。He et al.(2018)使用ever-match的匹配方法,在一定程度上解决了企业名称书写错误和名称变更所产生的漏批的问题。在没有其他数据源补充的情况下,这种方法确实提供了一个解决企业名称书写错误和名称变更问题的最优解决方案。然而,我们在前文中也已经指出,ever-match匹配方法有其局限性。其主要缺陷是,基于工企库整理的工业企业历史名称清单可能并不完整。
本文采用了一种新的思路,即尝试以工商库数据为桥梁,对精确匹配的结果进行补充。具体步骤如下:
首先,将工企库与工商库进行匹配。不同于专利数据,这两个库有较多重合指标,这些指标都可用于辅助匹配。此外,我们还可以根据工商库整理出更为完整的企业历史名称清单[9],提高两个库的匹配率。大致匹配步骤为:① 将工企库中的组织机构代码与工商库处理后的统一社会信用代码进行匹配;② 将工企库中的企业名称与工商库中的企业历史名称进行匹配;③ 将工企库和工商库中的工商注册号进行匹配;④ 将工企库和工商库中的企业成立年月、行政区划代码、法定代表人进行匹配;⑤ 将工企库和工商库中的企业所在地邮政编码与电话号码进行匹配。详细匹配过程参见社科大数据公众号推送的《企业数据库匹配系列(一)工企库与工商库匹配报告》。
其次,对通过工商库整理的企业历史名称清单,与专利申请人名称进行企业名称清洗,然后基于企业名称将专利库与工商库进行匹配,从而为专利库匹配上工商库唯一识别的企业ID。(未来我们将在社科大数据公众号上推送更为详细的《专利库与工商库匹配报告》)。
最后,将专利库与工企库进行匹配。我们为工企库中的工业企业匹配对应的工商库中的企业ID,同时为专利库中的企业申请人匹配工商库中的企业ID,通过工商库中的企业ID,实现工企库与专利库的匹配。
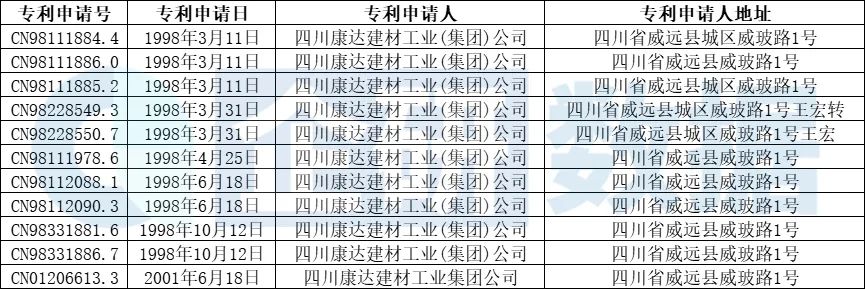
我们以“四川康达建材工业(集团)公司”为例,对这种方法的作用做简单介绍。如表3所示,工企库中的“国营四川省威远县康达实业总公司”的组织机构代码是“206702729”,这与工商库中的“四川康达建材工业(集团)公司”从其统一社会信用代码中提取的组织机构代码相一致[10]。因此,通过统一社会信用代码(组织机构代码),我们可以将工企库中的“国营四川省威远县康达实业总公司”与工商库中“四川康达建材工业(集团)公司”相匹配。进而通过企业名称,将工商库中“四川康达建材工业(集团)公司”与专利库中的“四川康达建材工业(集团)公司”相匹配。更多案例可参见表3。
表3 通过工商数据实现专利库与工企库匹配的案例

3、匹配结果的比较
对比各版本专利库和工企库的差异
考虑到匹配结果的差异不仅取决于匹配方法的优劣,也可能由所用专利库和工企库版本的差异造成。因此,在比较匹配结果之前,我们需要先对比各版本专利库和工企库的差异。
我们在表4中列出了本文和Xie&Zhang(2015)、He et al.(2018)、寇宗来和刘学悦(2020)所使用专利库的基本情况,并根据每篇文章的统计口径,用本文的专利数据重新进行了统计。对比发现,本文所用专利数据的统计结果与文献公布的数据量无明显差异。在不同口径下,本文统计的发明专利(含未授权)、实用新型和外观设计专利的数据量与上述三篇文献公布的专利数量相差不超过5%。需要指出的是,发明专利在公开后需进行实质审查,审查通过以后,方可获得授权。因此,专利数据的更新时间必然会影响发明专利的授权数量。故本文与寇宗来和刘学悦(2020)关于发明专利授权数的统计结果相差甚大(约24.5万条),主要由二者所用专利数据的更新时间不同所致。
表4 部分代表性研究所用专利数据基本情况对比

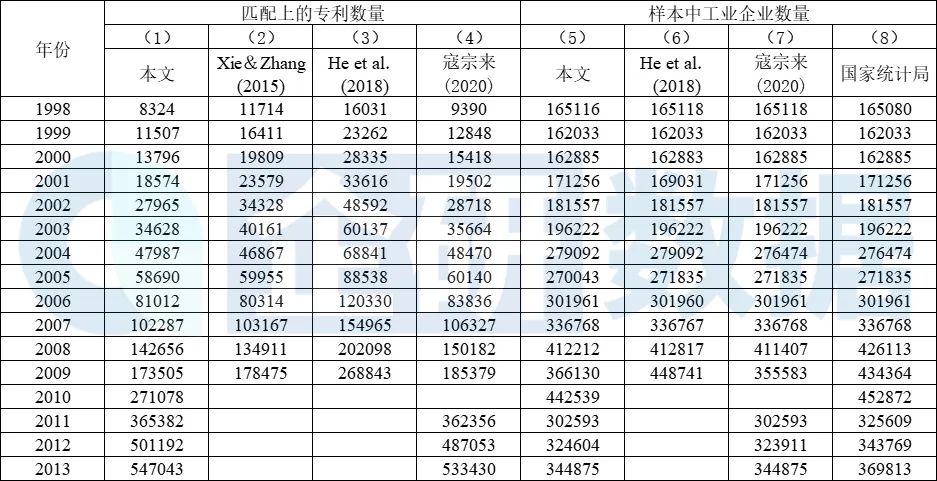
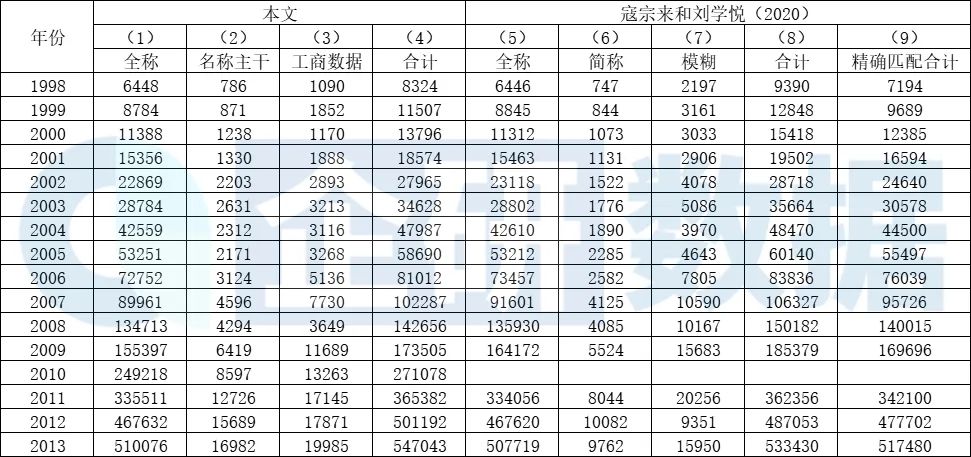
表5第(5)-(7)列分别展示了本文和He et al.(2018)、寇宗来和刘学悦(2020)所使用工企库的情况,第(8)列则是国家统计局官方公布的1998-2013年的工业企业数量。对比发现,除2009年以外,本文所使用的工企数据统计结果与国家统计局和2篇文献资料公布的工业企业数量非常相近。
表5 不同匹配结果的对比
比较匹配结果
如表4和表5第(5)-(8)列所示,本文所使用的专利库和工企库与Xie&Zhang(2015)、He et al.(2018)、寇宗来和刘学悦(2020)3篇文献所用数据无明显差异。因此,匹配结果的差异主要取决于匹配方法的优劣。表5第(1)-(4)列分别展示了本文和Xie&Zhang(2015)、He et al.(2018)、寇宗来和刘学悦(2020)这3篇文章的匹配结果。
表6第(1)-(3)列分别是本文各个步骤(企业全称精确匹配、企业名称主干匹配和利用工商库补充匹配)的匹配结果,第(4)列是本文最终的匹配结果(与表5第(1)列相一致)。第(5)-(8)列是寇宗来和刘学悦(2020)的匹配结果。总体而言,1998-2009年本文的匹配率要略低于寇宗来和刘学悦(2020),而2011-2013年本文的匹配率则更高。然而,寇宗来和刘学悦(2020)同时采用了精确匹配和模糊匹配的方法,而本文则仅采用精确匹配。相对而言,本文的匹配结果会更加可靠。如果不考虑寇宗来和刘学悦(2020)的模糊匹配结果,其仅保留企业全称和企业简称的匹配结果见第(9)列。对比(4)和(9)发现,本文的精确匹配率要明显高于寇宗来和刘学悦(2020)。
表6 分项匹配结果的对比
Part4 结论
本文在详细回顾已有文献关于专利库与工企库匹配策略的基础上,利用理论上包含中国大陆境内所有企业工商注册信息的中国全量工商企业数据库,提出了一整套实现专利库与工企库更准确匹配的方案。结果表明,不考虑准确率存疑的模糊匹配,本文的匹配精度与匹配完整性更高,从而为学界提供一套新的专利库与工企库的匹配结果。
本文所提供的数据匹配方案可为包括专利库与工企库匹配以外的中国企业数据库的跨数据库横向匹配提供一套行之有效的、可供借鉴的匹配方案。本文的研究表明,不考虑提供更多的企业信息,工商库也能够为传统的工企库与专利库匹配提供帮助,围绕工商库的开发能够提高各个企业数据库之间的匹配效能,有利于充分挖掘现有企业数据库的开发价值。
注释
[1] He et al.(2018)所使用的工业企业数据库,存在法人代码和企业名称缺失的情况。例如,2009年工业企业数据库448741条记录中,法人代码缺失的有142963条(占比31.86%),企业名称缺失的有136105条(占比30.33%),对此,作者根据往年的历史记录进行了补充。
[2] 寇宗来和刘学悦(2020)所使用的工业企业数据库,2009年43万家企业数据中,有11万家左右缺失了法人代码和企业名称信息,利用2008年经济普查数据和2009年全国税收调查数据对2009年数据进行补充。
[3] He et al.(2018)、寇宗来和刘学悦(2020)在名称预处理前还对2009年工企数据中缺失的企业名称进行了补充。前者主要基于工业数据往年的历史记录,后者则利用2008年经济普查数据和2009年全国税收调查数据。由于版本的差异,本文所用工企库2009年的数据不存在企业名称缺失的问题,因此无需做这一步。
[4] 规模以上工业企业的阈值要求曾发生过两次变化:(1)1998-2006年,涵盖全部国有工业企业及年主营业务收入500万元以上的非国有企业;(2)2007-2010年,统计范围调整为年主营业务收入500万元及以上的工业企业;(3)2011年开始至今,统计范围为年主营业务收入2000万元及以上的法人单位。
[5] 在同一专利有多个专利申请人的情况下,我们将排在第一位的专利申请人称之为“主专利申请人”,其余称之为“其他专利申请人”。
[6] 根据“专利申请人类型”指标,可将专利申请人进一步划分为自然人(个人)和机构两类,后者包括企业、事业单位、个体工商户和其他组织机构。
[7]事实上,我们也可以通过与事业单位在线(http://www.gjsy.gov.cn/)的相关信息进行比对,来判断专利申请人是否属于事业单位,进而剔除事业单位申请的专利。但综合考虑剔除事业单位申请的专利所需要的数据采集成本,以及保留这部分专利所带来的计算机运算压力,我们权衡之后最终选择了保留。
[8] 这里之所以不剔除企业名称中含有的县一级地址信息,是因为部分企业名称的主干部分含县一级地址信息。以“湖南省白云商贸有限公司”为例,其主干部分的“白云商贸”含广州市白云区的“白云”二字。
[9] 理论上来看,企业名称的变更需要在工商部门(即现在的市场监管部门)做变更登记。所以我们根据工商库整理的企业历史名称清单按理说是完整的。: 9
[10] 统一社会信用代码第9-17位为组织机构代码。“四川康达建材工业(集团)公司”的统一社会信用代码是“91511024206702729G”,对应的组织机构代码为“206702729”。
参考文献
[1] Griliches Zvi. Patent Statistics as Economic Indicators:A Survey [J]. Journal of Economic Literature,1990,12:16—61.
[2] Xie,Z.,and X.Zhang. The patterns of patents in China [J]. China Economic Journal,2015,8(2):122—142.
[3] He,Z.,T.W.Tong,Y.Zhang,and W.He. A Database Linking Chinese Patents to China’s Census Firms [J]. Scientific Data,2018,5:180042.
[4] 周煊,程立茹,王皓.技术创新水平越高企业财务绩效越好吗?——基于16年中国制药上市公司专利申请数据的实证研究[J].金融研究,2012(08):166-179.
[5] 寇宗来,刘学悦.中国企业的专利行为:特征事实以及来自创新政策的影响[J].经济研究,2020,55(03):83-99.
附录
附表1是“四川康达建材工业(集团)公司”在工企库中的基本情况,附表2是“四川康达建材工业(集团)公司”在1998-2013年期间的专利申请情况。如果只是基于企业名称的逐年匹配,我们将很难实现1998年工企库中的“国营四川省威远县康达实业总公司”与“四川康达建材工业(集团)公司”在1998年申请的专利的匹配。前者经过清理得到的企业全称是“国营四川省威远县康达实业总公司”,企业名称主干为“国营康达实业”;后者经过清理得到的企业全称为“四川康达建材工业集团公司”,企业名称主干为“康达建材工业”。无论是通过企业全称还是企业名称主干,都无法将这两个名称联系起来。
附表1 “四川康达建材工业(集团)公司”在工企库中的基本情况

然而,采用ever-match匹配方法,可以很好地解决这一难题。ever-match匹配方法用组织机构代码来识别不同年份的工业企业。根据附表1可知,“国营四川省威远县康达实业总公司”在1999年和2000年更名为“四川康达建材工业(集团)公司”,组织机构代码为“206702729”保持不变。采用ever-match匹配方法,多年合并匹配,就可以轻松实现两个数据库的匹配。
附表2 “四川康达建材工业(集团)公司”在1998-2013年期间的专利申请情况















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









