







本文章根据尚硅谷MyBatis教程整理而来
原视频地址:https://www.bilibili.com/video/BV1VP4y1c7j7

MyBatis简介
MyBatis历史
MyBatis最初是Apache的一个开源项目iBatis, 2010年6月这个项目由Apache Software Foundation迁
移到了Google Code。随着开发团队转投Google Code旗下, iBatis3.x正式更名为MyBatis。代码于
2013年11月迁移到Github。
iBatis一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架。 iBatis提供的持久层框架
包括SQL Maps和Data Access Objects(DAO)。
MyBatis特性
1) MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架
2) MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集
3) MyBatis可以使用简单的XML或注解用于配置和原始映射,将接口和Java的POJO(Plain Old Java
Objects,普通的Java对象)映射成数据库中的记录
4) MyBatis 是一个 半自动的ORM(Object Relation Mapping)框架
映射:java类与mysql数据库表的对应关系
其他持久化层技术对比
JDBC
- SQL 夹杂在Java代码中耦合度高,导致硬编码内伤
- 维护不易且实际开发需求中 SQL 有变化,频繁修改的情况多见
- 代码冗长,开发效率低
Hibernate 和 JPA
- 操作简便,开发效率高
- 程序中的长难复杂 SQL 需要绕过框架
- 内部自动生产的 SQL,不容易做特殊优化
- 基于全映射的全自动框架,大量字段的 POJO 进行部分映射时比较困难。
- 反射操作太多,导致数据库性能下降
MyBatis
- 轻量级,性能出色
- SQL 和 Java 编码分开,功能边界清晰。Java代码专注业务、SQL语句专注数据
- 开发效率稍逊于HIbernate,但是完全能够接受
MyBatis下载
MyBatis下载地址:https://github.com/mybatis/mybatis-3/releases
下载完成MyBatis的压缩包后,解压会看到MyBatis的jar包和官方文档
需要关系的是MyBatis的官方文档
MyBatis入门
建议观看MyBatis的官方文档来快速入门
MyBatis前提配置
导入依赖
首先需要导入mysql和Mybatis的jar包,我这里使用的是Maven,所以导入坐标
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.11</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.31</version>
</dependency>
注意:根据自己的MySQL数据库版本来选择Jar包
接下来,导入MyBatis的配置文件。
MyBatis的配置文件有两种:一个是MyBatis的核心配置文件,另一个是映射文件。
核心配置文件
这个是可以从MyBatis的官方文档中复制粘贴过来的,无需过多关心这个MyBatis的核心配置文件,因为在Spring整合中这个配置文件会被Spring的类替代。
这个配置文件的名称是随意的,但是习惯命名为mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 配置连接数据库的环境-->
<environments default="development">
<environment id="development">
<!-- 设置事务管理器的类型,此处指定为JDBC类型,
接下来对于事务的开启、提交、回滚等操作就会是手动处理(JDBC)
-->
<transactionManager type="JDBC"/>
<!-- 设置数据源类型,POOLED是数据库连接池-->
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!-- 引入映射文件-->
<mappers>
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>
将连接数据库的环境中的标签替换为自己的数据库环境,驱动用、用户名、密码等
注意:
如果你的MySQL的版本是8.0以下,那么你的驱动名称就是com.mysql.jdbc.Driver
如果MySQL版本是8.0及以上,那么你的驱动名称就是com.mysq.cj.jdbc.Driver
创建数据库表
创建数据库表,自定义即可

创建实体类
基于数据库表来创建Java中的实体类
注意:保证表字段名与类属性名一致
一个实体类:
- 所有属性都是private
- 每个属性都有对应的setter和getter
- 对应的无参构造和有参构造
- 重写toString()方法
package com.pojo;
/**
* @ClassName : User //类名
* @Description : //描述
* @Author : 刘明凯的专属computer //作者
* @Date: 2023/1/4 0004 23:49
*/
public class User {
private Integer id;
private String username;
private String password;
private Integer age;
private String sex;
private String email;
public User(Integer id, String username, String password, Integer age, String sex, String email) {
this.id = id;
this.username = username;
this.password = password;
this.age = age;
this.sex = sex;
this.email = email;
}
public User() {
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
", email='" + email + '\'' +
'}';
}
}
创建Mapper接口
这个Mapper接口类似于我们原生JDBC开发中DAO层的接口,在使用MyBatis开发时,我们只需要给出Mapper接口,不需要给出实现类。
在Mapper中定义操作数据库的方法
MyBatis是面向接口编程的思想,会在运行时自动生成Mapper接口对应的实现类,当调用方法时会自动匹配一条SQL语句
public interface UserMapper {
/*
* 添加用户信息
* */
int insertUser();
}
一般来说,定义Dao层接口,习惯使用操作的表名+Dao来命名
对于Mapper接口,同样习惯这样来命名
比如说我这个Mapper接口要操作User表,那么可以将接口命名为UserMapper
映射文件
相关概念:ORM(Object Relationship Mapping)对象关系映射。
- 对象:Java的实体类对象
- 关系:关系型数据库
- 映射:二者之间的对应关系
| Java中的概念 | 数据库概念 |
|---|---|
| 类 | 表 |
| 属性 | 字段、列 |
| 对象 | 记录、一行数据 |
映射文件的命名规则:一般习惯使用对应Mapper接口的名称,映射文件与Mapper接口名称保持一致
比如说我的Mapper接口名叫UserMapper.java,那么我对应的映射文件就是UserMapper.xml
由于将来的映射文件有很多,所以习惯在resources目录下新建一个mappers目录,用来存放映射文件
这个映射文件的模板,依然是从官方文档中复制粘贴过来
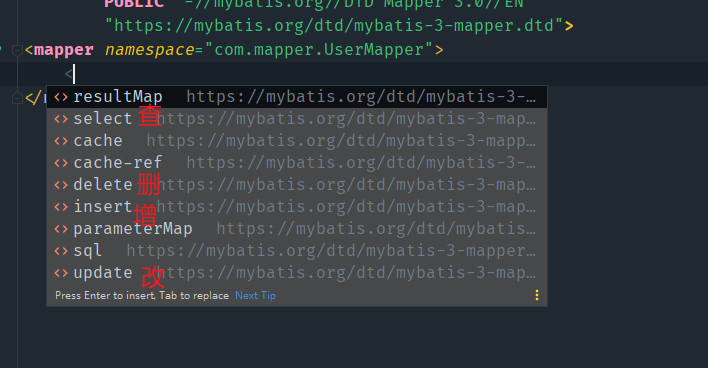
在映射文件中,可以看到有很多标签,都是用来匹配不同类型的SQL语句的,比如说,我要写一个SQL语句,那么我就用<select>标签。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mapper.UserMapper">
<insert id="insertUser" >
INSERT INTO `mybatis`.`t_user` (
`id`,`username`,`password`,`age`,`sex`,`email`
)
VALUES
(
NULL,'admin','123',21,'男','182@163.com'
);
</insert>
</mapper>
注意:两个一致
- 映射文件中的namespace属性要与对应Mapper接口的全类名保持一致(否则该配置文件无法与Mapper接口匹配)
- 映射文件中的SQL语句的id要与Mapper接口中的方法名称保持一致(否则无法在调用方法时自动匹配SQL语句)
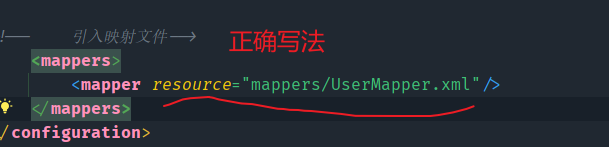
当写好了映射文件之后,就需要在MyBatis的核心配置文件中引入
注意:我们是使用Maven构建项目,配置文件要放在resources目录下,因为此目录不是源代码目录,所以引入时需要给出配置文件的路径名,不可以使用包名的方式引入
严格按照这种规范
- 查询语句使用
<select>标签- 添加语句使用
<insert>标签- 删除语句使用
<delter>标签- 修改语句使用
<update>标签

至此,MyBatis的前提配置已经完成
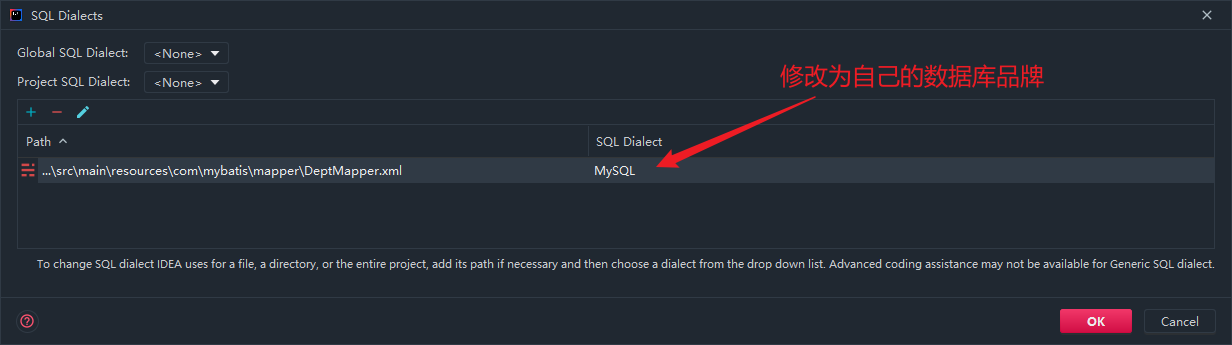
在映射文件中,我们写的SQL可能会有警告,这样的提示信息
原因是IDEA不知道这个SQL语句是哪个品牌的数据库的规范,不同的数据库之间的SQL语句可能会有细微的差别。
解决方法:


代码测试
MyBatis为我们提供了一个操作数据库的会话对象
// 加载核心配置文件
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
// 创建SqlSessionBuilder对象
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
// 获取SqlSessionFactory对象,将配置文件的输入流传入
SqlSessionFactory sqlSessionFactory = builder.build(in);
// 获取会话对象SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
SqlSession:代表Java程序与数据库的会话,类似于Web开发中,客户端与服务器的会话,能够通过这个会话对象来操作数据库
前面说过,MyBatis是面向接口编程的,会自动生成我们的Mapper接口的实现类,在执行相应方法时,是需要实现类来调用的,那么如何来获取Mapper接口的实现类呢?
// 获取Mapper接口的实现类对象,底层是代理模式
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
获取到Mapper接口的实现类之后,调用其方法即可完成数据库操作
看完整代码
// 加载核心配置文件
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
// 创建SqlSessionBuilder对象
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
// 获取SqlSessionFactory对象,将配置文件的输入流传入
SqlSessionFactory sqlSessionFactory = builder.build(in);
// 获取会话对象SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取Mapper接口的实现类对象
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
// 测试方法
int result = mapper.insertUser();
// 提交事务
sqlSession.commit();
System.out.println("result=" + result);
优化
-
自动提交事务
在上面演示的案例中,我们使用的是 JDBC的事务管理方式,这种方式需要我们手动管理事务,手动提交事务。
那么能不能自动提交事务呢?
只需要在获取SqlSession对象时,传入一个Boolean值来获取一个是否自动提交事务的会话
SqlSession sqlSession = sqlSessionFactory.openSession(true); // 默认是false,即不自动提交事务此时就需要在代码中手动提交事务了。
-
添加日志功能
为了方便我们对系统运行的监控,尤其是对于数据库的操作,我们可以导入日志框架,来监视我们的数据库操作
在这使用log4j来作为日志框架,说一下简单的使用
-
导入依赖
<!-- https://mvnrepository.com/artifact/log4j/log4j --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> -
导入配置文件
注意:log4j的配置文件名称是log4j.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"> <log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/"> <appender name="STDOUT" class="org.apache.log4j.ConsoleAppender"> <param name="Encoding" value="UTF-8"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%-5p %d{MM-dd HH:mm:ss,SSS}%m (%F:%L) \n"/> </layout> </appender> <logger name="java.sql"> <level value="debug"/> </logger> <logger name="org.apache.ibatis"> <level value="info"/> </logger> <root> <level value="debug"/> <appender-ref ref="STDOUT"/> </root> </log4j:configuration>在log4j中,日志级别分为
FATAL(致命)>ERROR(错误)>WARN(警告)>INFO(信息)>DEBUG(调试)
-
测试删改查功能
在上面的例子中,完成了添加功能的操作,接下来测试一下删改查的功能
修改功能
在UserMapper接口中,定义一个修改的方法
public interface UserMapper {
/*
* 添加用户信息
* */
int insertUser();
/**
* 修改用户信息
*/
void updateUser();
}
在对应的XML中,使用update标签来写对应的SQL语句
注意:标签的id为方法名
<!-- void updateUser();-->
<update id="updateUser">
update t_user set username = 'zhangsan' where id = 1;
</update>
测试一下
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(in);
SqlSession sqlSession = sqlSessionFactory.openSession(true);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
mapper.updateUser();
删除功能
- 在Mapper接口中定义相关方法
void deleteUser();
- 定义映射文件中的SQL语句
<!-- void deleteUser();-->
<delete id="deleteUser">
delete from t_user where id = 10;
</delete>
- 测试
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(in);
SqlSession sqlSession = sqlSessionFactory.openSession(true);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
mapper.deleteUser();
查询功能
以上的增删改功能的方法,返回值是固定的,可以设置为int,也可以设置为void。
但是对于查询功能来说,必须有一个返回结果,而且sql语句不同,返回结果不同。
查询功能的基本步骤
- 在接口中定义相关的方法,返回值类型为一个POJO
User getUserById();
- 在XML中使用select 标签来定义SQL语句,必须要指定resultType或resultMap
<!-- User getUserById();-->
<select id="getUserById" resultType="com.pojo.User">
select * from t_user where id = 1;
</select>
需要将查询结果集封装到Java的类中,此时就需要用到映射,所以要设置resultType或resultMap
- resultType:设置默认的映射关系,根据表的字段名来直接匹配类的属性名,只有相同时才会映射。
- resultMap:设置自定义的映射关系,如果表的字段名与类的属性名不匹配,则需要但单独指定某个字段与类属性的映射关系。
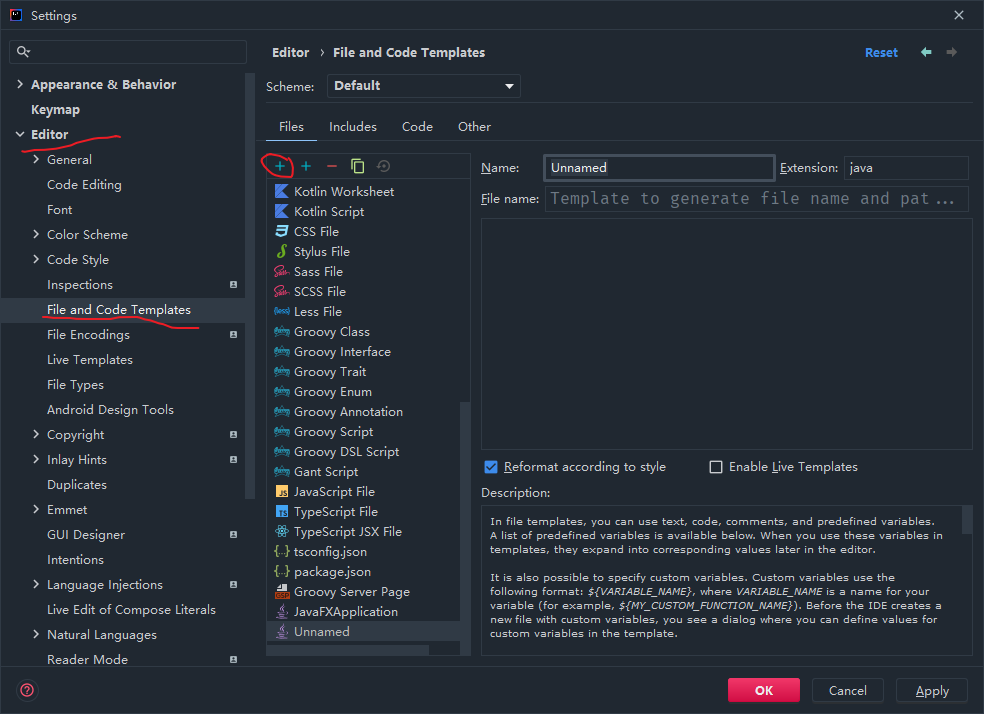
创建文件模板
当在创建新的项目时,需要创建mybatis的核心配置文件和mapper映射文件,每次都需要去官方文档中复制粘贴,或者将原先的配置文件复制到新的项目中,甚是麻烦。
可以使用IDEA的模板功能,然后就可以根据模板直接创建出配置模板,然后在新的文件中稍作修改就可以作为新项目中的配置文件来使用。
模板
Mybatis核心配置文件的模板
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//MyBatis.org//DTD Config 3.0//EN"
"http://MyBatis.org/dtd/MyBatis-3-config.dtd">
<configuration>
<properties resource="jdbc.properties"/>
<settings>
<!--将表中字段的下划线自动转换为驼峰-->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!--开启延迟加载-->
<setting name="lazyLoadingEnabled" value="true"/>
</settings>
<!-- 设置别名-->
<typeAliases>
<package name=""/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<!--引入映射文件-->
<mappers>
<mapper resource=""/>
<package name=""/>
</mappers>
</configuration>
Mapper映射文件的模板
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="">
</mapper>
IDEA配置模板
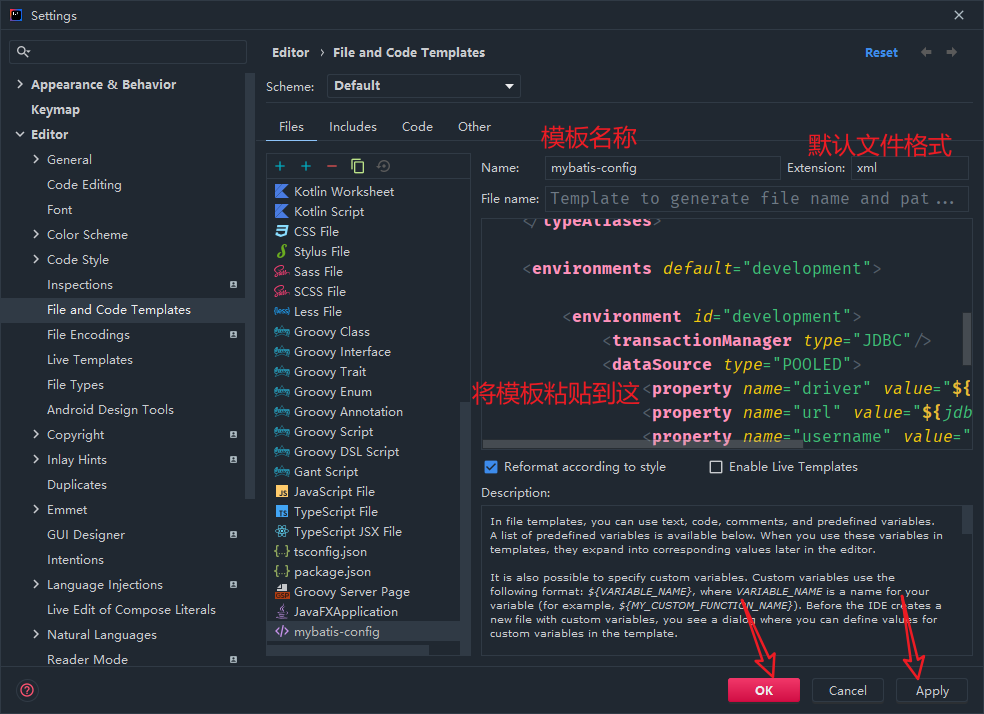
此时new时就会看到模板
创建成功

同时将mapper映射文件的模板也创建一下。
创建SqlSession工具类
每次获取SqlSession都是一个重复的过程,可以将这个重复的过程封装到一个工具类中,直接调用工具类的静态方法来获取SqlSession对象。
private static SqlSession sqlSession = null;
public static SqlSession getSqlSession() {
try {
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
sqlSession = factory.openSession(true);
} catch (IOException e) {
Logger logger = Logger.getLogger(SqlSessionUtils.class.getName());
logger.debug("获取SqlSession对象失败" + e);
}
return sqlSession;
}
配置文件详解
因为引入了外部约束,所以标签的顺序是这样的
properties?,settings?,typeAliases?,typeHandlers?,objectFactory?,objectWrapperFactory?,reflectorFactory?,plugins?,environments?,databaseIdProvider?,mappers?
environment
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--
environments:
配置多个连接数据库的环境
default属性:设置默认使用的环境id
-->
<environments default="development">
<environment id="test">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
<environment id="development">
<!--
environment:设置具体的链接数据库的环境
id属性:环境的唯一标识,不可重复
可通过environments标签的default属性来指定使用的环境id
-->
<transactionManager type="JDBC"/>
<!-- transactionManager事务管理器
type:设置事务管理器的方式,共有两个属性值 JDBC|MANAGED
JDBC: 表示当前环境中,执行SQL时,使用的是JDBC中原生的管理事务的方式
事务的提交或回滚需要手动
MANAGED:当前环境的事务被管理,例如Spring
-->
<dataSource type="POOLED">
<!--
设置数据源类型,
type:设置数据源类型,一共有三个属性值
POOLED使用数据库连接池来缓存数据库连接
UNPOOLED不使用数据库连接池
JNDI:表示使用上下文中的数据库连接池
-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!-- 引入映射文件-->
<mappers>
<mapper resource="mappers/UserMapper.xml"/>
</mappers>
</configuration>
引入配置文件
像数据库的配置信息,直接在environment中写死,会造成高耦合。
在日常开发中,会把数据库的配置信息单独放到一个配置文件中,然后在mybatis的配置文件中引入这个数据库配置文件。
先来写一个数据库配置文件
在项目中,可能会有很多的同类型配置文件,在.properties的配置文件中,是key = value的形式,在其他的配置文件中,难免会造成key重复的情况,所以为了避免这种情况,一般都会在key前加上一个标识。
比如我们的这个配置文件名称是jdbc.properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/mybatis
jdbc.username=root
jdbc.password=root
在mybatis的配置文件中,利用<properties>标签来引入,使用${}的方式来引用配置文件中的value
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="jdbc.properties"/>
<!--
environments:
配置多个连接数据库的环境
default属性:设置默认使用的环境id
-->
<environments default="development">
<environment id="development">
<!--
environment:设置具体的链接数据库的环境
id属性:环境的唯一标识,不可重复
可通过environments标签的default属性来指定使用的环境id
-->
<transactionManager type="JDBC"/>
<!-- transactionManager事务管理器
type:设置事务管理器的方式,共有两个属性值 JDBC|MANAGED
JDBC: 表示当前环境中,执行SQL时,使用的是JDBC中原生的管理事务的方式
事务的提交或回滚需要手动
MANAGED:当前环境的事务被管理,例如Spring
-->
<dataSource type="POOLED">
<!--
设置数据源类型,
type:设置数据源类型,一共有三个属性值
POOLED使用数据库连接池来缓存数据库连接
UNPOOLED不使用数据库连接池
JNDI:表示使用上下文中的数据库连接池
-->
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
<environment id="test">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!-- 引入映射文件-->
<mappers>
<mapper resource="mappers/UserMapper.xml"/>
</mappers>
</configuration>
typeAliases
在查询的标签中,必须要设置resultType或restltMap,需要给出映射类的全类名,当项目大了后,会有很多类,此时一直频繁地写类的全类名就较为繁琐。
MyBatis支持为某个类起别名
<typeAliases>
<!-- 设置类型别名-->
<typeAlias type="com.pojo.User" alias="User"/>
</typeAliases>
- type:给出某个类的全类名
- alias:为这个类的别名
- alias属性可以选择性设置,如果不设置,那么默认的别名就是去掉包名的类名
- 别名在使用时不区分大小写
那么此时在Mapper文件中,resulType就可以这样写
<select id="getUserById" resultType="User" >
select * from t_user where id = 1;
</select>
这样写较为简单,但是需要单独写每一个类,有没有能够批量别名的功能呢?
这时候可以使用<package>标签,也是在开发中最常用的方式
<typeAliases>
<package name="com.pojo"/>
<!-- 以包为单位起别名,别名直接为类名-->
</typeAliases>
- package是以包为单位,为包下的所有类起别名,别名就是类名,不区分大小写
mappers
用来引入映射文件的标签,如果使用<mapper>标签来一个一个地导入映射文件,也是较为繁琐的。
同样这个,映射文件也是支持以包为单位批量导入的。
首先,我们要根据源代码目录下的mapper接口所在的包,在resources目录下创建相同的目录结构
注意:因为resources不是源代码目录,所以在创建目录时,不能使用.,要使用/
源代码目录下的mapper包中放的都是mapper接口,所以在resources的同级目录下放的都是对应的映射文件。
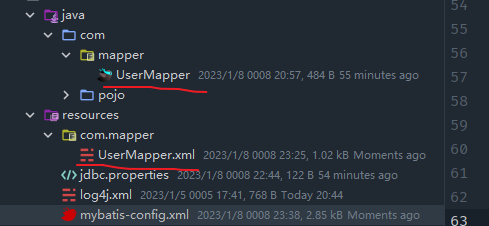
此时配置文件中,使用<package>标签来导入以包为单位的映射文件即可
<mappers>
<!--
<mapper resource="mappers/UserMapper.xml"/>
-->
<package name="com.mapper"/>
</mappers>
完善的配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//MyBatis.org//DTD Config 3.0//EN"
"http://MyBatis.org/dtd/MyBatis-3-config.dtd">
<configuration>
<!--引入properties文件,此时就可以${属性名}的方式访问属性值-->
<properties resource="jdbc.properties"/>
<settings>
<!--将表中字段的下划线自动转换为驼峰-->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!--开启延迟加载-->
<setting name="lazyLoadingEnabled" value="true"/>
</settings>
<typeAliases>
<!--
typeAlias:设置某个具体的类型的别名
属性:
type:需要设置别名的类型的全类名
alias:设置此类型的别名,若不设置此属性,该类型拥有默认的别名,即类名且不区分大小
写
若设置此属性,此时该类型的别名只能使用alias所设置的值
-->
<!--<typeAlias type="com.atguigu.mybatis.bean.User"></typeAlias>-->
<!--<typeAlias type="com.atguigu.mybatis.bean.User" alias="abc">
</typeAlias>-->
<!--以包为单位,设置改包下所有的类型都拥有默认的别名,即类名且不区分大小写-->
<package name="com.atguigu.mybatis.bean"/>
</typeAliases>
<!--
environments:设置多个连接数据库的环境
属性:
default:设置默认使用的环境的id
-->
<environments default="mysql_test">
<!--
environment:设置具体的连接数据库的环境信息
属性:
id:设置环境的唯一标识,可通过environments标签中的default设置某一个环境的id,
表示默认使用的环境
-->
<environment id="mysql_test">
<!--
transactionManager:设置事务管理方式
属性:
更多Java –大数据 – 前端 – UI/UE - Android - 人工智能资料下载,可访问百度:尚硅谷官网(www.atguigu.com)
四、MyBatis的增删改查
1、添加
2、删除
3、修改
type:设置事务管理方式,type="JDBC|MANAGED"
type="JDBC":设置当前环境的事务管理都必须手动处理
type="MANAGED":设置事务被管理,例如spring中的AOP
-->
<transactionManager type="JDBC"/>
<!--
dataSource:设置数据源
属性:
type:设置数据源的类型,type="POOLED|UNPOOLED|JNDI"
type="POOLED":使用数据库连接池,即会将创建的连接进行缓存,下次使用可以从
缓存中直接获取,不需要重新创建
type="UNPOOLED":不使用数据库连接池,即每次使用连接都需要重新创建
type="JNDI":调用上下文中的数据源
-->
<dataSource type="POOLED">
<!--设置驱动类的全类名-->
<property name="driver" value="${jdbc.driver}"/>
<!--设置连接数据库的连接地址-->
<property name="url" value="${jdbc.url}"/>
<!--设置连接数据库的用户名-->
<property name="username" value="${jdbc.username}"/>
<!--设置连接数据库的密码-->
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<!--引入映射文件-->
<mappers>
<mapper resource="UserMapper.xml"/>
<!--
以包为单位,将包下所有的映射文件引入核心配置文件
注意:此方式必须保证mapper接口和mapper映射文件必须在相同的包下
-->
<package name="com.atguigu.mybatis.mapper"/>
</mappers>
</configuration>
MyBatis基础功能
MyBatis获取Sql参数值
接收参数的两种方式
在使用增删改差时,需要涉及到参数,根据参数来完成指定的增删改查,那么在映射文件中的SQL 语句应该如何来接收这些参数,如何把这些参数拼接形成一个SQL语句呢?
在MyBatis中获取参数值的两种方式
#{}${}
在学习原生的JDBC时,有两种SQL 语句拼接参数的方式
- 字符串拼接
String sql = "select * from user where username='" + username + "'and id = '"+ id + "'";
使用字符拼接的方式来接收参数,需要注意SQL注入的问题,还要自己手动在参数值前后输入单引号
- 占位符赋值
PreparedStatement pstm = conn.prepareStatement(sql);
pstm.setString(1, username);
pstm.setInt(2,id);
使用占位符替换的方式来接收参数值,不用考虑单引号的问题,也不用担心SQL注入的问题。
在MyBatis中,#{}和${}这两种方式也就对应上面的两种方式
${}本质字符串拼接#{}本质占位符赋值
知道了参数的接收方式之后,还要考虑参数类型的问题,传过来的是一个int或String还是Map,应该怎样拼接参数值。
单个字面量
如果在Mapper接口中的方法的参数是单个的字面量,例如int、String
先来看Mapper接口中的方法
User getUserById();
先用#{}来试试
<!-- User getUserById(int id);-->
<select id="getUserById" resultType="User" >
select * from t_user where id = #{id}
</select>
来看测试代码
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUserById(1);
System.out.println(user);
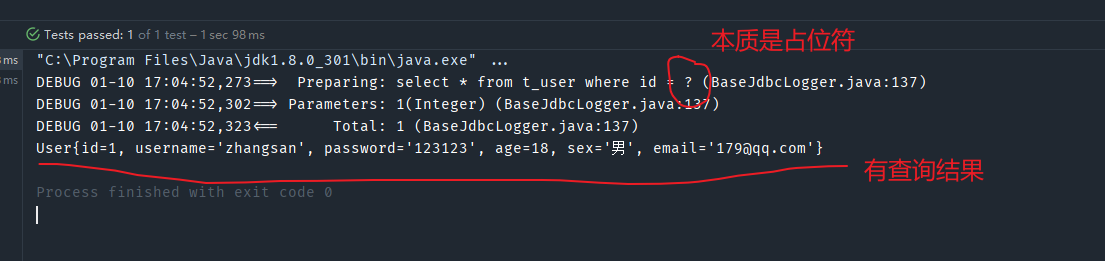
在映射文件中的SQL语句,我们使用了#{id}来接收并拼接参数,此时id是对应方法的形参名
此时更换为#{abc}也是可以的,说明参数参数替换给形参名无关,只与位置相关。
但是为了方便代码阅读,使用形参来替换
再来看看${}
重新定义一个新的方法
User getUserByUserName(String username);
映射文件
<!--User getUserByUserName(String username);-->
<select id="getUserByUserName" resultType="User">
select * from t_user where username = ${username};
</select>
测试一下
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUserByUserName("zhangsan");
System.out.println(user);
会看到报错了
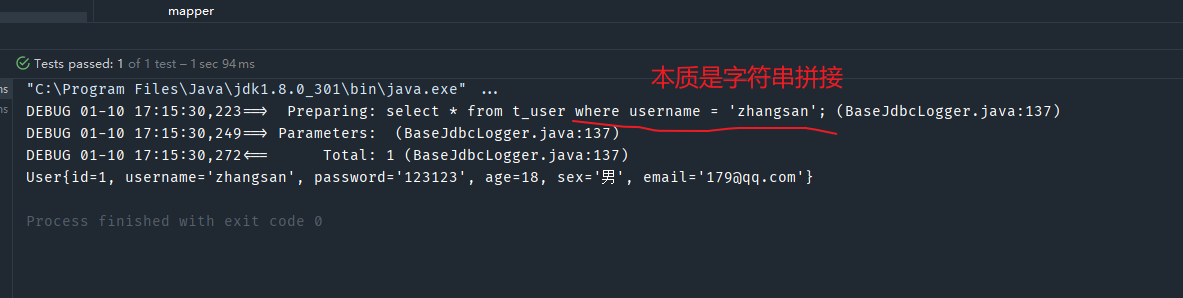
原因是${}本质是字符串拼接,我们没有处理单引号问题。
可以在映射文件中这样来修改
<!--User getUserByUserName(String username);-->
<select id="getUserByUserName" resultType="User">
select * from t_user where username = '${username}';
</select>
再来测试一下
多个字面量
当Mapper接口中的方法的参数有多个字面量时,如何接收参数呢?
在Mapper接口中定义一个这样的方法
/**
* 检验用户登录
* @param username String类型的用户名
* @param password String类型的密码
* @return 返回一个封装好的User,如果用户名密码正确,则User不为空,否则为空
*/
User checkLogin(String username,String password);
在映射文件中,如果继续使用参数名来接收,像这样,看看可不可以
<!--User checkLogin(String username,String password);-->
<select id="checkLogin" resultType="User">
select * from t_user where username = #{username} and password = ${password}
</select>
测试一下
User user = mapper.checkLogin("zhangsan","123123");
System.out.println(user);

MyBatis发生了报错,报错信息是没有找到我们在SQL语句中接收的参数,并给出了可供选择的参数。
当参数有多个时,MyBatis会将这些参数封装到一个Map集合中,给出默认的键,传递的参数作为值,有两种类型的键
- 键的名称为
arg开头的,序号从0开始,按照传递参数的顺序 - 键的名称为
param开头的,序号从1开始
我们需要将映射文件中的SQL语句改成
<!--User checkLogin(String username,String password);-->
<select id="checkLogin" resultType="User">
select * from t_user where username = #{arg0} and password = ${arg1}
</select>
或者改成
<!--User checkLogin(String username,String password);-->
<select id="checkLogin" resultType="User">
select * from t_user where username = #{param1} and password = #{param2}
</select>
也可以arg与param混用
<!--User checkLogin(String username,String password);-->
<select id="checkLogin" resultType="User">
select * from t_user where username = #{arg0} and password = #{param2}
</select>`
Map参数
当方法中需要的参数有多个时,我们可以将这些参数封装成一个Map集合传递给方法,然后就就可以在映射文件中使用传递过来的这个Map集合的键来获取值,不需要使用MyBatis自封装的以arg和param为键的集合了。
/**
* 自封装参数到一个Map集合中,这样在映射文件的sql语句接收参数时,
* 就可以使用自定义的map的键来接收参数
* @param map 将多个参数自封装到Map集合中
* @return User类型的对象,如果登录失败,则返回值为null
*/
User checkLoginByMap(Map<String, Object> map);
看测试代码
SqlSession sqlSession = SqlSessionUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Map<String,Object> map = new HashMap<String,Object>();
map.put("username","zhangsan");
map.put("password","123123");
User user = mapper.checkLoginByMap(map);
System.out.println(user);
映射文件中就可以使用自定义的键来获取值
<!-- User checkLoginByMap(Map<String, Object> map);-->
<select id="checkLoginByMap" resultType="User">
select * from t_user where username = #{username} and password = #{password};
</select>
参数类型是实体类
这种方式是我们平时用的最多的一种方式,例如:当前台表单传过来登录信息时,我们经常将这些信息封装成一个实体类对象然后传递给DAO层。
在MyBatis中,如何接收实体类对象身上的属性值呢?
对象也可以看做成一个Map集合,对象的属性作为key,属性值作为value,所以在映射文件中可以直接通过属性名来接收参数即可
前提是实体类必须设置了相应的setter和getter,否则无法访问到属性
Mapper接口中的方法,参数是User类型
/**
* 根据封装好的实体类对象来插入用户
* @param user User类型的对象
* @return int SQL执行对数据库表的影响行数
*/
int insertUser(User user);
映射文件
<!-- int insertUser(User user);-->
<insert id="insertUser">
insert into t_user values(null,#{username},#{password},#{age},#{sex},#{email})
</insert>
测试代码
User user = new User(null, "lisi", "123123", 21, "男", "@123.com");
int lines = mapper.insertUser(user);
if (lines > 0) {
System.out.println("插入成功");
} else {
System.out.println("插入失败");
}
@Param注解自定义键
我们可以利用@Param注解来标注参数, MyBatis在封装到Map集合时,就会以注解的值为键来添加参数。
/**
* 利用@Param注解来标注参数,在映射文件中就可以以指定的键来获取参数
* @param username String类型的用户名
* @param password String类型的密码
* @return USer对象
*/
User checkLoginByParam(@Param("username") String username,@Param("password") String password);
在映射文件中的SQL就可以直接使用@Param的值来作为key获取参数值
<select id="checkLoginByParam" resultType="User">
select * from t_user where username = #{username} and password = #{password};
</select>

会看到,当我们使用了@Param注解后,将原来的arg的键替换成了我们自定义的键
因此使用@Param来标注参数,共有两种获取参数的方式
- 使用自定义的键来获取参数
- 使用默认的
param来获取参数
不论参数是单个还是多个,都可以使用@Param来标注
总结
大致上就可以将参数的获取分为两种方式
- 不使用
@Param注解的,通过Map集合的键或实体类的属性来获取参数 - 使用
@Param注解的,就使用自定义的key来获取就可以了
推荐使用@Param注解来注解并获取参数,能够见名知意,代码可读性强。
查询功能
在增删改查这四个功能中,最复杂、最核心的功能就是查询。
查询结果为一条数据
当查询的结果是一条数据时,就可以将方法的返回值设置为一个实体类对象,也可以使用集合来接收。
- 实体类对象
- List集合
- Map集合
User getUserById(@Param("id") Integer id);
// 或
List<User> getUserById(@Param("id") Integer id);
映射文件SQL
<select id="getUserById" resultType="User">
select * from t_user where id = #{id}
</select>
查询结果为多条数据
当查询结果为多条数据时,一定不能以单个实体类对象接收,必须使用集合接收
- List集合
- Map集合
当查询结果有多条,但是返回值是一个实体类对象时,就会报错:结果集太多的错误

查询单个数据
当查询的结果就是一个普通的单个数据,例如查询表的总记录数,查询某条指定记录的某个字段。
此时的结果集是一个一行一列的结果集,此时应该如何设置返回值类型呢?
接口方法正常写
/**
* 查询用户表的总记录数
* @return Integer
*/
Integer getCount();
在映射文件中,resutlType应该如何指定,第一感觉是指定Integer的全类名
<!-- Integer getCount();-->
<select id="getCount" resultType="java.lang.Integer">
select count(*) from t_user
</select>
这样是可以运行成功的
将resultType改成Integer或integer或int或Int,你会发现也是可以正常运行的,这就说明MyBatis为我们JDK中常用的基本数据类型以及对应的包装类设置类别名。
可以通过查看MyBatis的官方手册来查看
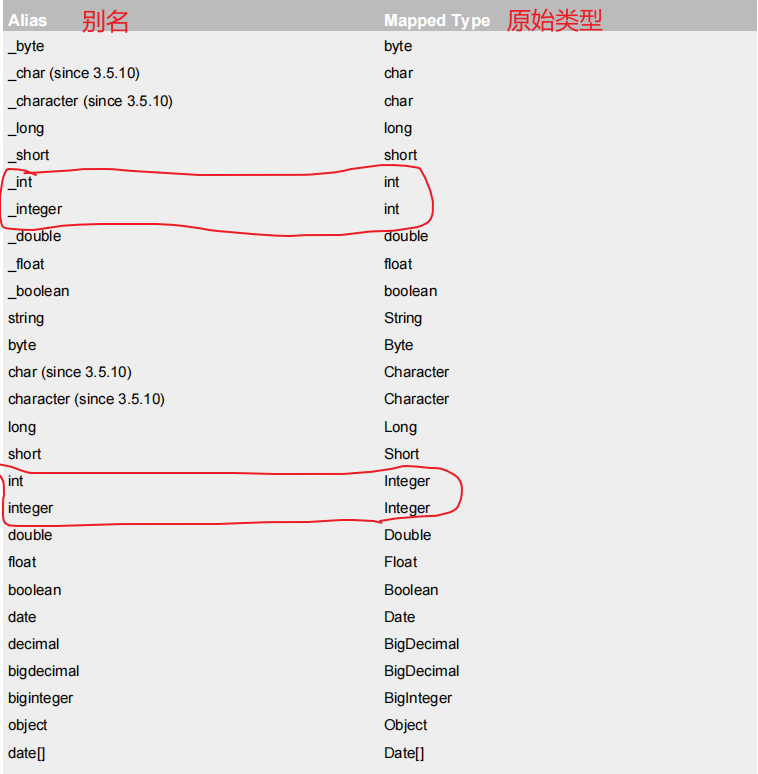
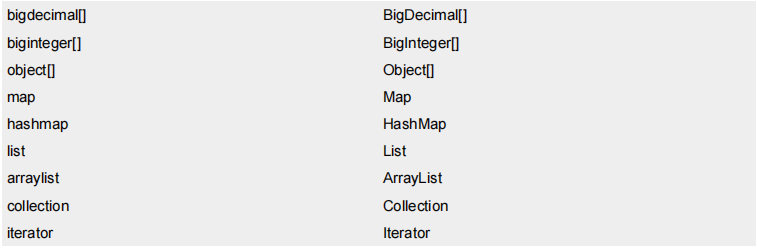
这是MyBatis为我们指定的常用的数据类型的别名,可以发现一个规律
- 基本数据类型的别名是
下划线+名称和下划线+包装类名称 - 包装类的别名就是名称和基本数据类型的名称
在resultType的返回值是一个基本数据类型和包装类都是可以的,因为两者是可以自动装箱和自动拆箱的。
查询结果为Map集合
在resultType为一个实体类时,为什么会将数据封装成一个实体类对象,是因为类的属性名和字段名相同,所以就会自动封装成一个实体类对象。
返回值是一个Map集合也是这样的原理,将表字段名称作为key,对应的值作为value。
在实际开发中,用到最多的一个场景就是查询结果并没有实体类对象,此时可以将返回值设置为Map,Map本身就是一个键值对的形式,可以作为JSON返回给前台
接口方法
/**
* 获取Map形式的User
* @return Map<String,Object>
*/
Map<String,Object> getUserByIdAsMap(@Param("id") Integer id);
映射文件的SQL
<!-- Map<String,Object> getUserByIdAsMap();-->
<select id="getUserByIdAsMap" resultType="map">
select * from t_user where id = #{id}
</select>
测试一下
SelectMapper mapper = sqlSession.getMapper(SelectMapper.class);
System.out.println(mapper.getUserByIdAsMap(1));

多条数据作为Map集合
上面演示的是一条数据转换为Map,此时会将这条数据的字段名称作为key,字段值作为value。
但是当我们的查询结果为多条数据时,也想装换为Map集合,按照道理来说就应该是一条完整的数据作为value。
此时如果接口方法还是像刚才那样定义
Map<String,Object> getAllUsersAsMap();
映射文件
<!-- Map<String,Object> getAllUsersAsMap();-->
<select id="getAllUsersAsMap" resultType="map">
select * from t_user
</select>
此时测试就会报错,仍然是结果集太多的错误

因为返回值类型是Map<String,Object>,MyBatis在转换时会将字段名称作为key,如果有一条数据时会成功,但是现在的结果是多条数据,MyBatis不知道如何转换了。
此时可以这样来优化:将返回值类型修改为List<Map<String,Object>>,此时一条记录对应一个Map,将这多个Map再放到一个List集合中。
List<Map<String,Object>> getAllUsersAsMap();

还有一种更好的解决办法:MyBatis中提供了@MapKey的注解,用此注解来指定某个字段的值作为key,这一条记录作为value
定义接口方法时这样写
@MapKey("id")
Map<String,Object> getAllUsersAsMap();
映射文件不变
<select id="getAllUsersAsMap" resultType="map">
select * from t_user
</select>
测试一下
SelectMapper mapper = sqlSession.getMapper(SelectMapper.class);
System.out.println(mapper.getAllUsersAsMap());

注意:选择某个字段的值作为key时,此字段的值应该是可以唯一标识一条记录的,因为Map中是不可以key重复的
特殊SQL的执行
模糊查询
#{}和${}两种替换参数的方式
#{}本质上是占位符替换${}本质上是字符串拼接
我们用的比较多的是#{},因为它能避免Sql注入,还不用考虑单引号的问题。
但是并不是所有的场景都适合用#{},例如模糊查询。
先来看一个使用#{}来模糊查询的例子
这是接口方法
/**
* 根据用户名来实现模糊查询
* @param username
* @return List集合,因为模糊查询的结果可能不止一个
*/
List<User> getUserByLikeUsername(@Param("username") String username);
映射文件
<!-- List<User> getUserByLikeUsername(@Param("username") String username);-->
<select id="getUserByLikeUsername" resultType="User">
select * from t_user where username like '%#{username}%'
</select>
此时测试就会报错

分析:
此时可以看到SQL语句是可以正常解析的,但是由于模糊查询是
‘%%’的形式,当我们使用#{}来接收参数时,会将#{}替换为?,然后根据问号占位符去替换,但是由于这个?号是在'%%'中,所以这个?号就当做了字符串的一部分,并不会将它作为占位符,但是我们又传递了参数,此时MyBatis认为不需要传参,但是我们传了参数,此时就会报无法设置参数的错误。
这就说明了并不是所有的场景都适用#{}来传参
此时将SQL语句中的#{}替换成${}就可以解决问题
<select id="getUserByLikeUsername" resultType="User">
select * from t_user where username like '%${username}%'
</select>
这是实现模糊查询的第一个方式,在学习MySQL时,有一个字符串函数concat,能够实现字符串的拼接,能够在这个函数中使用#{}来实现模糊查询的效果,SQL语句应该这样来写
<select id="getUserByLikeUsername" resultType="User">
select * from t_user where username like concat('%',#{username},'%')
</select>
此时是可以使用#{}来接收参数的,因为#{}被正常识别为占位符,并自动替换了字符串,也同时加上了单引号
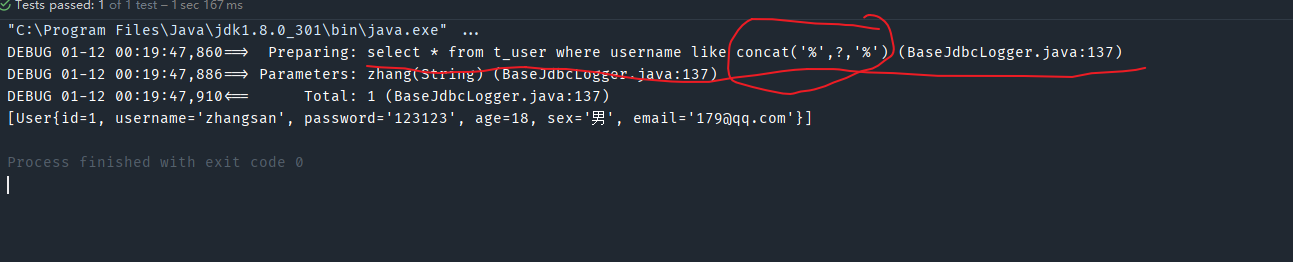
在开发中,实现模糊查询还有一种更简便的方式,也是用的最多的一种方式
select * from t_user where username like "%"#{username}"%"
在MySQL中双引号是可以直接拼接单引号的,像这样的SQL语句是可以在MySQL中成功执行的
SELECT * FROM t_user WHERE username = "zhang"'san'
总结
实现模糊查询的三种方式
- 利用
${}
<select id="getUserByLikeUsername" resultType="User">
select * from t_user where username like '%${username}%'
</select>
- 利用MySQL中的concat字符串拼接函数
<select id="getUserByLikeUsername" resultType="User">
select * from t_user where username like concat('%',#{username},'%')
</select>
- 最简便的方式:双引号的方式
<select id="getUserByLikeUsername" resultType="User">
select * from t_user where username like "%"#{username}"%"
</select>
批量删除
在学习MySQL时,一个最容易想到的批量删除的语句是
delete from t_user where id = 1 or id = 2 or ....
还有一种更简便的方式,就是in这个关键字
delete from t_user where id in (1,2,3)
在MyBatis中应该如何处理批量删除呢?
我们在删除时,往往根据id来删除,因为id能够唯一标识一条记录。
一般这些id会封装到一个String中,然后传递给MyBatis,此时我们不可以使用#{},因为#{}会自动补全单引号,但是id是整形,就会出现这样的错误:
String ids = "1,2,3"
此时使用#{}解析出来的参数是
delete from t_user where id in ('1,2,3')
将’1,2,3’作为了一个整体,虽然这条语句可以正常执行,但是达不到逾期的效果,就不会正常删除。
此时要要使用${}
/**
* 批量删除
* @param ids String类型的id , 例如 "1,2,3"
* @return 影响的行数
*/
Integer deleteUserByIds(@Param("ids") String ids);
映射文件
<!-- Integer deleteUserByIds(@Param("ids") String ids);-->
<delete id="deleteUserByIds" >
delete from t_user where id in (${ids})
</delete>
动态设置表名
当查询的表时不固定的时,这个表名也是动态的,需要根据传过来的参数来访问表。
例如:将一张表的数据差分成多个表,每个表的表名都不是一样的。
因为在SQL语句中,表名是不能加单引号的,所以要用${}
接口方法
/**
* 根据不同的表名来获取数据
* @param tableName String类型的表名
* @return List<USer>
*/
List<User> getUsersByTableName(@Param("tableName") String tableName);
映射文件
<!-- List<User> getUsersByTableName(@Param("tableName") String tableName);-->
<select id="getUsersByTableName" resultType="User">
select * from ${tableName}
</select>
获取自增的主键值
在大部分的表中,我们一般都不会去维护主键,而是让主键自增,这样只需要把剩余字段维护好即可。
但是,在其他的一些表中,还需要参考本表的主键作为外键,此时就需要将这个主键值获取到,然后才能继续执行接下来的业务。
在原生的JDBC中,返回自增长的主键的方法是
Connection conn = DriverManager.getConnection(url,username,password);
// 1.使用一个常量来告知此执行对象需要携带自增主键
PreparedStatement pstm = conn.prepareStatement(sql,Statement.RETURN_GENERATED_KEYS);
// 2. 获取自增结果集
ResultSet rs = pstm.getGeneratedKeys();
// 3. 遍历结果集
while(rs.next()){
rs.getInt(1);
}
在MyBatis中,获取自增的主键应该如何设置?
首先来写一个接口方法
/**
* 获取自增的主键值
* @param user 一个实体类对象
* @return 影响的行数
*/
int insertUser(User user);
映射文件
<!-- int insertUser(User user);-->
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
insert into t_user values(null,#{username},#{password},#{age},#{sex},#{email})
</insert>
测试一下
SelectMapper mapper = sqlSession.getMapper(SelectMapper.class);
User user = new User(null, "wangwu", "123",18,"男","123@qq.com");
mapper.insertUser(user);
System.out.println(user);

增删改这种SQL语句的返回值是固定的:操作对表影响的行数。因此无法将自增的主键作为返回值。
所以,要想获取自增的主键,需要传递的参数是一个实体类对象,该实体类对象与数据库的表对应,然后MyBatis会将获取到的自增的主键设置到这个实体类对象身上,这就是MyBatis实现获取自增主键的原理
注意:
- 对应的SQL语句需要设置
useGeneratedKeys= true,表示这条语句有自增的主键 - 同时设置
keyProperty为实体类对象的某个属性,告诉MyBatis将获取到的自增的主键值设置到这个实体类对象的哪一个属性上
自定义映射resultMap
解决属性名与字段名不一致问题
在设置查询语句的返回值时,resultType是默认的返回值类型,要求字段名与属性名一致。
但是对于字段名与属性名不一致的情况,例如表字段习惯带有下划线,但是在实体类的规范中不能有下划线,此时就可以使用resultMap来自定义字段与属性的映射关系。
先来看表的结构,其中有一个字段是带有下划线,这是按照表字段的命名规范
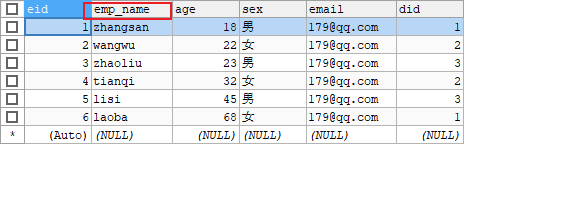
然后根据表创建对应的实体类,属性的命名规范就是驼峰命名的样式
接口方法
/**
* 返回所有的员工
* @return List集合
*/
List<Emp> getAllEmp();
映射文件,我们先使用resultType来试试
<!-- List<Emp> getAllEmp();-->
<select id="getAllEmp" resultType="Emp">
select * from t_emp
</select>
测试一下:发现有一个属性值为null
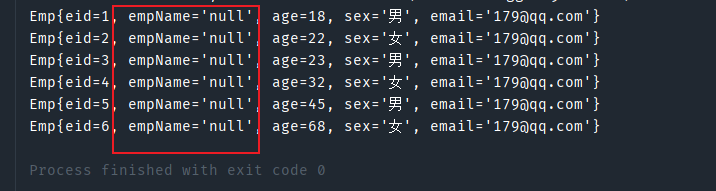
因为字段的名称是emp_name,而对应的类的属性名称是empName,不相同,所以MyBatis没有找到字段的对应属性,所以就没有设置empName的值。
解决方法一:字段设置别名
我们利用SQL语句为表设置别名,使得别名与属性名相同。
<select id="getAllEmp" resultType="Emp">
select eid, emp_name empName,age, sex,email from t_emp
</select>
此时MyBatis就可以成功将字段值设置到属性身上。
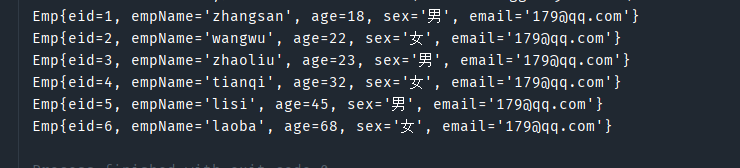
但是这不是最理想的解决方式,因为较为繁琐。
解决方式二:全局配置
在MyBatis中,可以通过全局配置来解决。
关于MyBatis的全局配置选项,可以在MyBatis的官方文档中查看。
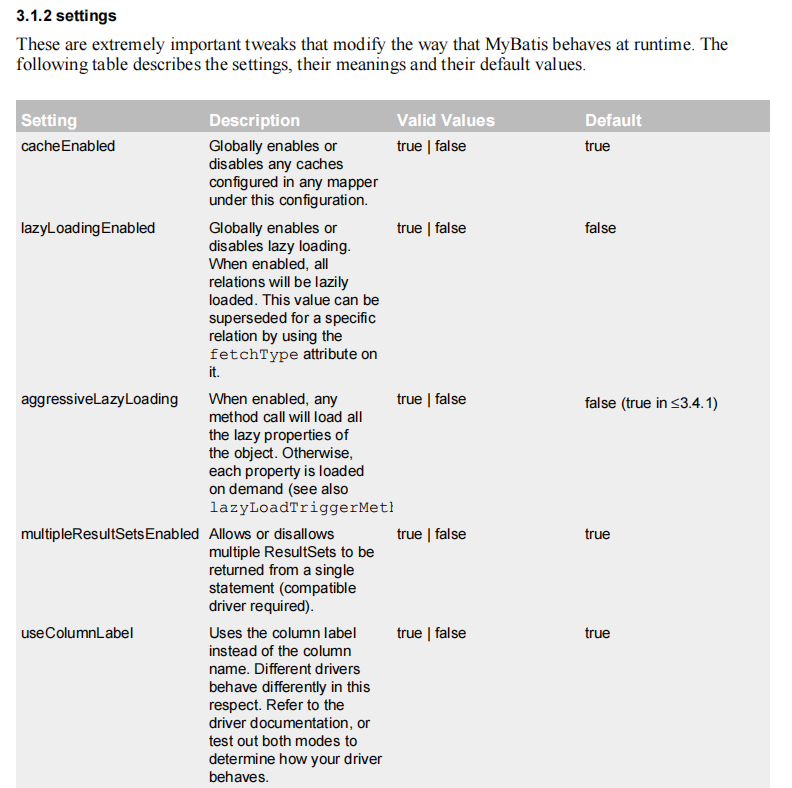
其中就有一个选项mapUnderscoreToCamelCase,可以设置下划线自动转换驼峰命名
在MyBatis中,添加这个全局配置选项,注意标签放置的位置
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
此时的映射文件就可以正常书写了
<select id="getAllEmp" resultType="Emp">
select * from t_emp
</select>
注意
- 表字段名称要符合规范,例如
emp_name - 类属性名称也要符合规范,例如
empName
解决方法三:resultMap设置自定义的映射关系
- 首先我们在映射文件中自定义一个映射关系
- 使用
<resultMap>标签来自定义映射关系 - 自定义的映射关系需要指定id,这是这个映射关系的唯一标识
- 需要指定
type给出需要映射的实体类 - 在
<resultMap>中,<id>标签专门用来映射主键字段 - 其余的字段使用
<result>标签来映射 property属性用来写类的属性名,column属性用来写表的字段名
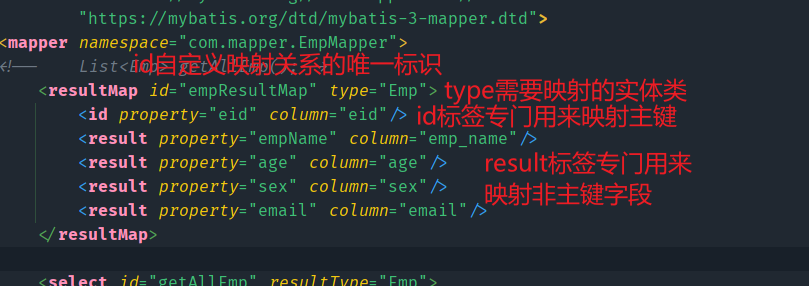
注意:因为使用了自定义映射关系,不是默认的resultType了,即使类的属性名与字段名相同,也要给出映射
- 在SQL语句的标签中使用
resultMap属性来指定使用哪一个自定义的映射关系,传入自定义映射关系的id
<select id="getAllEmp" resultMap="empResultMap">
select * from t_emp
</select>

接下来就会根据自定义的映射关系来映射到实体类

resultMap处理多对一的关系
resultMap使用更多的场景是解决一对多和多对一的关系
例如员工表和部门表,员工与部门是多对一的关系,那么可以在表设计时,在员工表中添加部门表的id。
但是在实体类中,应该如何设置多对一的关系呢?
我们只需要在员工的实体类中,添加一个私有属性,这个属性的类型是部门类,并设置这个属性的setter和getter
public class Emp {
private Integer eid;
private String empName;
private Integer age;
private String sex;
private String email;
private Dept dept;
@Override
public String toString() {
return "Emp{" +
"eid=" + eid +
", empName='" + empName + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
", email='" + email + '\'' +
", dept=" + dept +
'}';
}
public Dept getDept() {
return dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
public Emp() {
}
public Emp(Integer eid, String empName, Integer age, String sex, String email) {
this.eid = eid;
this.empName = empName;
this.age = age;
this.sex = sex;
this.email = email;
}
public Integer getEid() {
return eid;
}
public void setEid(Integer eid) {
this.eid = eid;
}
public String getEmpName() {
return empName;
}
public void setEmpName(String empName) {
this.empName = empName;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}
在处理时,如何使用Mybatis来处理多对一的映射关系呢?
方式一:级联属性赋值
先定义接口方法
/**
* 获取员工及其部门的信息
* @param eid 员工的唯一标识
* @return Emp实体类对象
*/
Emp getEmpAndDept(@Param("eid") Integer eid);
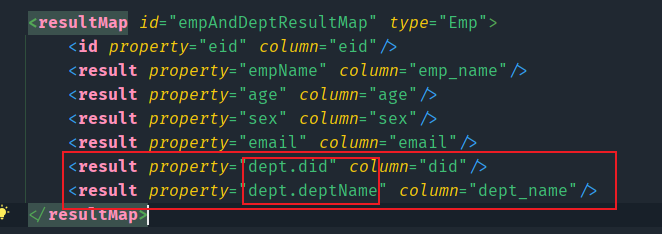
映射文件:
<resultMap id="empAndDeptResultMap" type="Emp">
<id property="eid" column="eid"/>
<result property="empName" column="emp_name"/>
<result property="age" column="age"/>
<result property="sex" column="sex"/>
<result property="email" column="email"/>
<result property="dept.did" column="did"/>
<result property="dept.deptName" column="dept_name"/>
</resultMap>
<!--Emp getEmpAndDept(@Param("eid") Integer eid);-->
<select id="getEmpAndDept" resultMap="empAndDeptResultMap">
SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp.`did` = t_dept.`did` where eid = #{eid}
</select>
因为部门表的字段无法直接映射到员工类 ,而是映射的是员工类中的部门属性身上的属性
方式二:通过<association>标签来解决
在resultMap中,有一个特殊的标签<association>,这个标签就是用来专门处理多对一关系的
- property用来指定需要映射的属性名
- javaType用来指定属性的类型
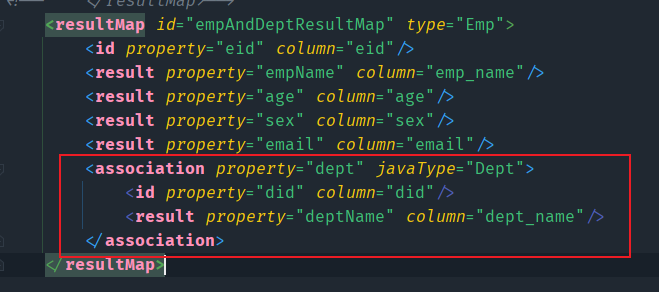
MyBatis会根据反射来拿到这个类型的对象,然后封装我们指定的数据,然后再将这个对象赋给员工类中的同类型的属性。
方式三:分步查询
在开发中用的比较多的处理多对一关系的方法
如果没有多表连接时,如何获取一个员工及其部门的信息呢?
我们可以分两步,第一步先查询员工信息,第二步根据查询出来的员工信息的部门id再来查询部门信息。
其实这就是分步查询的原理。
我们在MyBatis来实现一下这个功能。
- 定义一个Emp的接口中定义方法,表示第一步,来查询一个员工信息
- 第二步,在Dept的接口中定义方法,表示第二步,来根据员工信息中的部门id来查询部门信息
接下来实现这两个步骤
第一步:在Emp接口中定义方法
/**
* 分步查询第一步,先根据员工id查询员工信息
* @param eid 员工的唯一标识
* @return Emp对象
*/
Emp getEmpAndDeptByStep(@Param("eid") Integer eid);
第二步:在EmpMapper的映射文件中定义SQL,继续使用<association>标签,但是此标签中属性需要解释一下
property用来指定员工类中需要复制的属性名称select用来将哪一条sql语句的结果赋给该属性column用来指定将员工信息的哪一个属性作为参数传递给第二个接口方法,也就是说需要将第一条SQL语句的查询结果的哪一个字段值传递给第二条SQL语句
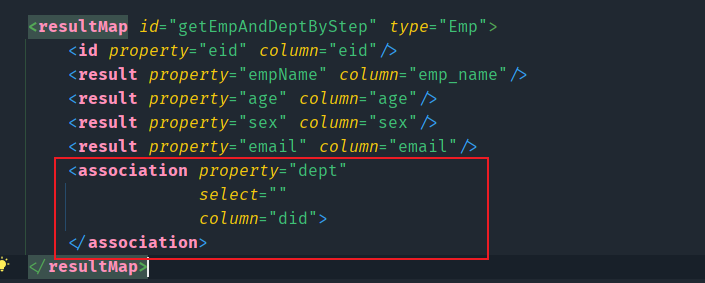
第三步:定义Dept接口中的方法,用该方法来查询部门信息,返回值是一个Dept类型,因为该返回值需要赋给员工类的属性,必须要与员工类型的属性同类型。
/**
* 分步查询的第二步
* @param did 第一步传递过来的参数
* @return Dept类型的对象
*/
Dept getEmpAndDeptByStepTwo(@Param("did") Integer did);
第四步:定义Dept映射文件的SQL
<!--Dept getEmpAndDeptByStepTwo(@Param("did") Integer did);-->
<select id="getEmpAndDeptByStepTwo" resultType="Dept">
select * from t_dept where did = #{did}
</select>
此映射SQL写好之后,因为第一步需要参考该SQL语句,所以需要在第一个映射文件的SQL的resultMap标签中的select属性中来指定第二条sql语句。
如何唯一标识一条SQL语句呢?
在MyBatis中,一条SQL语句的唯一标识就是:接口的全类名+ 该方法名,因为一个接口方法对应一条SQL语句
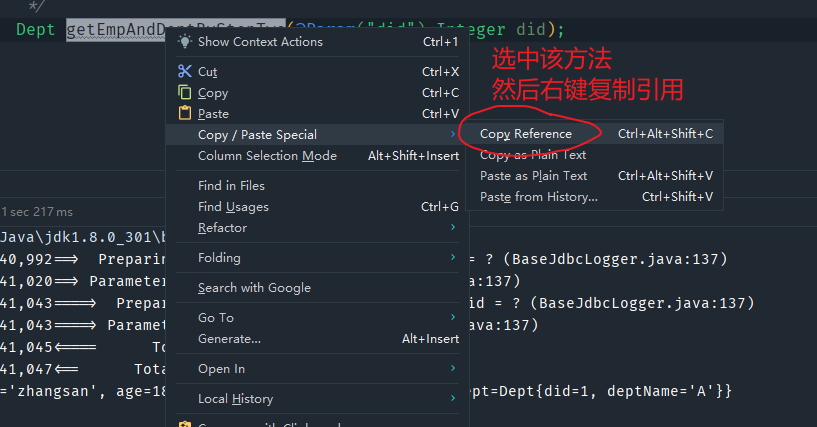
将这条SQL语句的唯一标识,也就是对应方法的唯一标识粘贴到第一条SQL语句的resultMap标签中的select属性中

到此为止,分布查询结算完成了,测试一下,成功查询。
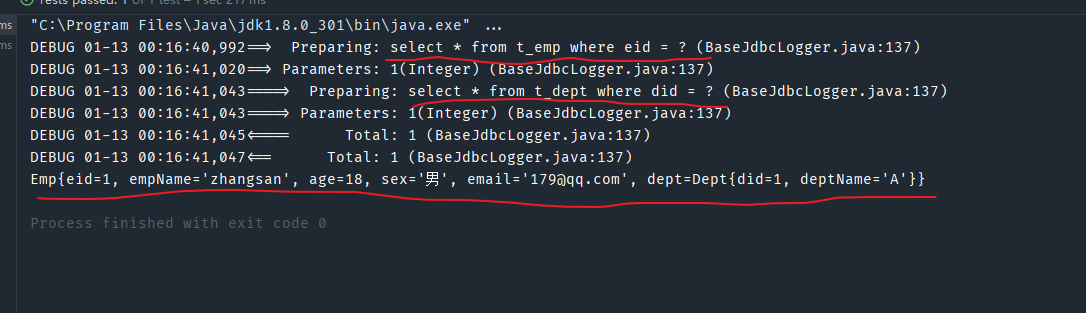
总结一下分布查询的原理:
将第一步的查询结果中的某个属性值作为参数传递给第二个方法,然后第二个方法的的返回值会是一个与前面属性值同类型的,然后将该查询结果直接赋给该属性
分布查询的优点——延迟加载
分布查询的优点就是延迟加载,但是需要在MyBatis的配置文件中设置一下全局配置信息(默认是关闭的)
什么是延迟加载?
因为刚才的分布查询是分两步的,第一步查询用户信息,第二步查询部门信息。
延迟加载也可以叫按需加载,当我们开启了延迟加载之后,获取员工的基本信息时(除员工的部门信息外),就会只调用第一步,当我们需要获取员工的部门信息时,再去执行第二步。
也就是说,延迟加载会按照所需来调用,如果第二步的结果不是你的所需,那么就不会去调用第二步。
在MyBatis中如何实现延迟加载?
需要在MyBatis中的全局配置中设置一个属性
lazyLoadingEnabled:延迟加载的全局开关,默认是false,当开启后,所有的关联方法都会延迟加载
如果你的MyBatis是3.4.1及以下的版本,那么还需要关注一个全局设置的属性
aggressiveLazyLoading:该设置在3.4.1及以下的版本中是默认开启的,当该选项开启后,任何方法的调用都会加载该对象的所有属性,也即是说,这个选项开启后,所有的方法都是立即加载。需要关闭该属性才能实现延迟加载。该属性在3.4.1以后的版本中默认是关闭的。
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
</settings>
当开启了延迟加载之后,我们来看一下效果
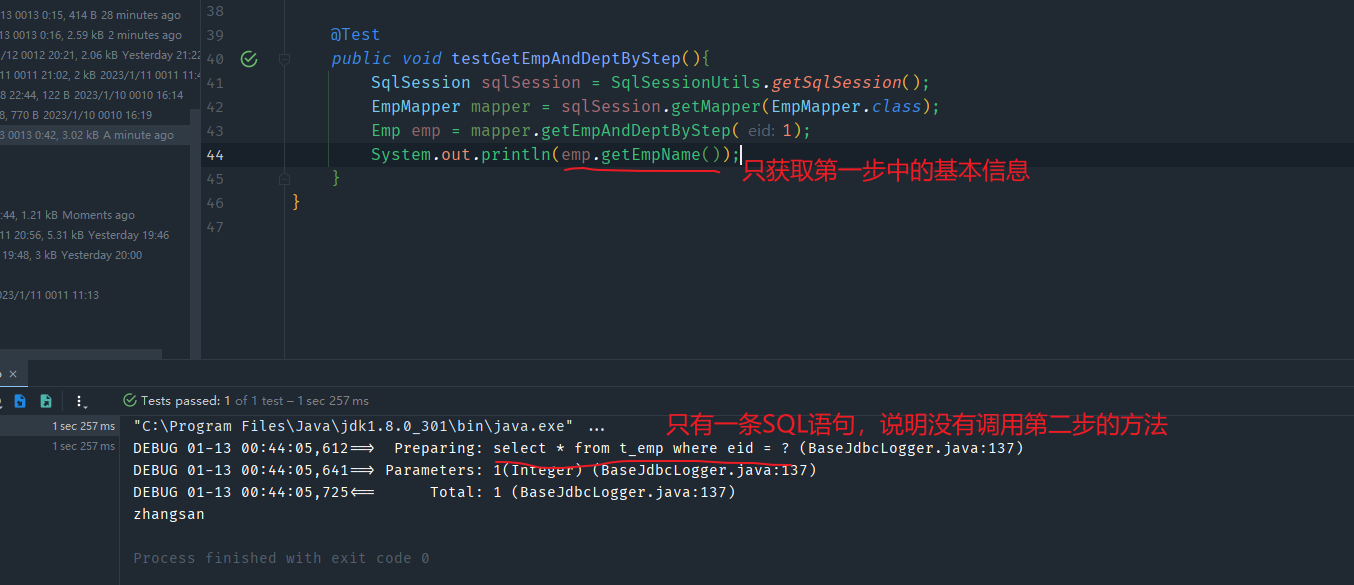
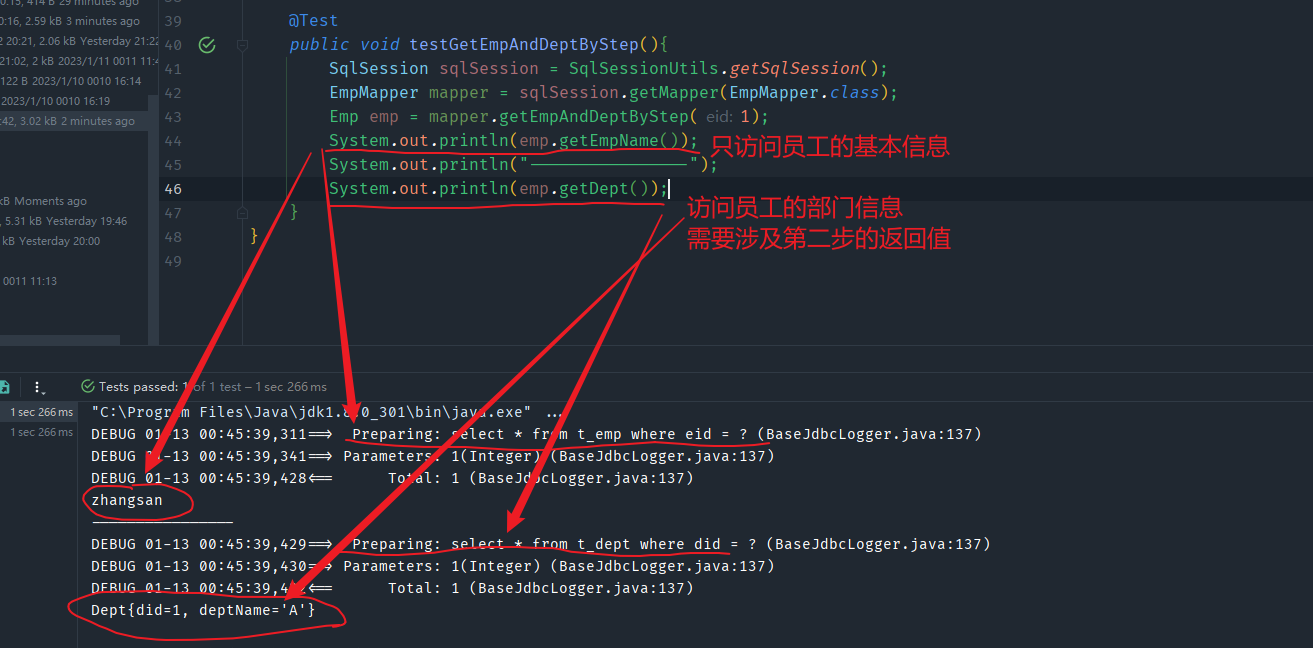
当开启了全局延迟加载后,所有的有管理的方法都会启用延迟加载,但是我们有一个方法不想启用延迟加载呢?
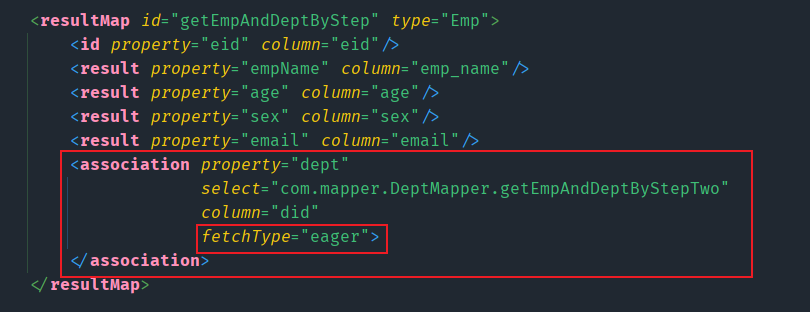
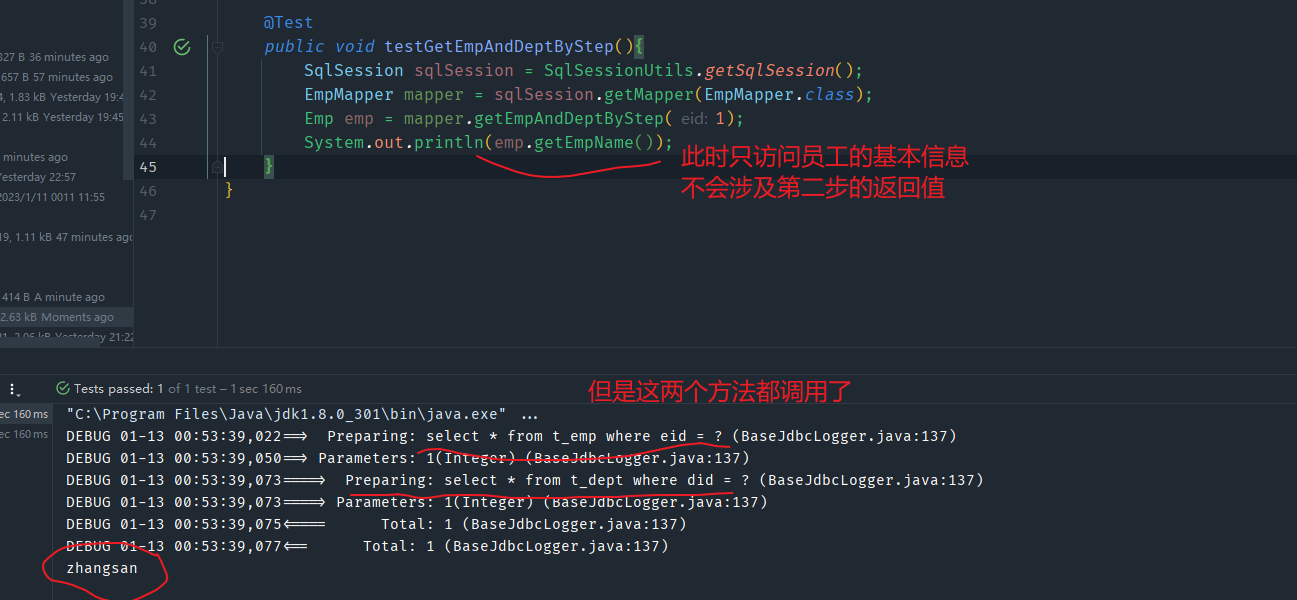
此时可以使用association标签中的fetchType属性来单独控制某个方法是否开启延迟加载(前提是开启了全局延迟加载)
fetchType有两个属性值
lazy默认值,延迟加载eager,立即加载
注意:只有开启了全局加载,即设置了lazyLoadingEnabled后,才能使用fetch属性来单独控制某个方法是否延迟加载
来测试一下该属性
resultMap处理一对多关系
如何在实体中表示一对多的关系呢?
例如一个部门可以有多个员工,部门与员工的关系就是一对多。
我们只需要在部门的实体类中添加一个集合的属性即可,集合中元素的类型是员工类。
collection处理一对多关系
比如说,我们来实现一个功能:查看某个部门的信息以及这个部门中所有员工的信息
先定义一个接口方法
/**
* 根据部门id获取某个部门以及该部门的所有员工
* @param did 唯一标识一个部门
* @return Dept实例
*/
Dept getDeptAndEmps(@Param("did") Integer did);
再来定义中映射文件中的SQL语句
<resultMap id="getDeptAndEmpsResultMap" type="Dept">
<id property="did" column="did"/>
<result property="deptName" column="dept_name"/>
<collection property="emps" ofType="Emp">
<id property="eid" column="eid"/>
<result property="empName" column="emp_name"/>
<result property="age" column="age"/>
<result property="sex" column="sex"/>
<result property="email" column="email"/>
</collection>
</resultMap>
<!-- Dept getDeptAndEmps(@Param("did") Integer did);-->
<select id="getDeptAndEmps" resultMap="getDeptAndEmpsResultMap">
select * from t_dept left join t_emp on t_dept.did = t_emp.did where t_dept.did = #{did}
</select>
在resultMap中,collection标签专门用来处理一对多个关系。
property属性,指定需要映射的属性,这个属性应当是一个集合,用来体现一对多关系ofType属性,用来指定集合中元素的类型
通过分步查询来实现一对多
还是实现查询部门信息以及部门所有员工的信息的功能。
通过分步查询来实现,我们首先要缕清逻辑。
先通过部门id查询到部门的信息,然后在通过部门id查询员工。
先定义第一个接口方法
/**
* 通过分步查询来实现获取部门信息以及所有员工的信息
* @param did 部门的唯一标识
* @return Dept实例
*/
Dept getDeptAndEmpsByStep(@Param("did") Integer did);
再来写对应的SQL
<resultMap id="getDeptAndEmpsByStepResultMap" type="Dept">
<id property="did" column="did"/>
<result property="deptName" column="dept_name"/>
<collection property="emps"
select="com.mapper.EmpMapper.getEmpByDid"
column="did">
</collection>
</resultMap>
<!-- Dept getDeptAndEmpsByStep(@Param("did") Integer did);-->
<select id="getDeptAndEmpsByStep" resultMap="getDeptAndEmpsByStepResultMap">
select * from t_dept where t_dept.did = #{did}
</select>
再来写第二个接口方法
/**
* 通过部门id来查询部门员工
* @param did 部门的唯一标识
* @return 一个集合
*/
List<Emp> getEmpByDid(@Param("did") Integer did);
对应的映射文件的SQL
<!-- List<Emp> getEmpByDid(@Param("did") Integer did);-->
<select id="getEmpByDid" resultType="Emp">
select * from t_emp where did = ${did}
</select>
一对多实现分布查询的原理与多对一实现分布查询的原理是相同的
只不过
- 一对多使用的是
collection标签来映射一对多个关系,对应实体类中有一个集合属性 - 多对一使用
association标签来映射多对一的关系,对应实体类中有一个“一”的属性
动态SQL
Mybatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决
拼接SQL语句字符串时的痛点问题。
if
实现一个多条件查询的功能。员工有姓名、性别、年龄、邮箱等基本信息,这些都可以作为多条件查询的条件。
往往会将这些信息封装成一个实体类对象,然后将这个对象传递给数据访问层。
来使用MyBatis中提供的 if标签来实现这个多条件查询
if标签是用来判断的标签,只有当判断条件为真时,标签体中的SQL语句才会拼接上
首先定义一个接口方法
/**
* 多条件查询
* @param emp 封装了查询条件的实体类对象
* @return List集合
*/
List<Emp> getEmpByCondition(Emp emp);
映射文件
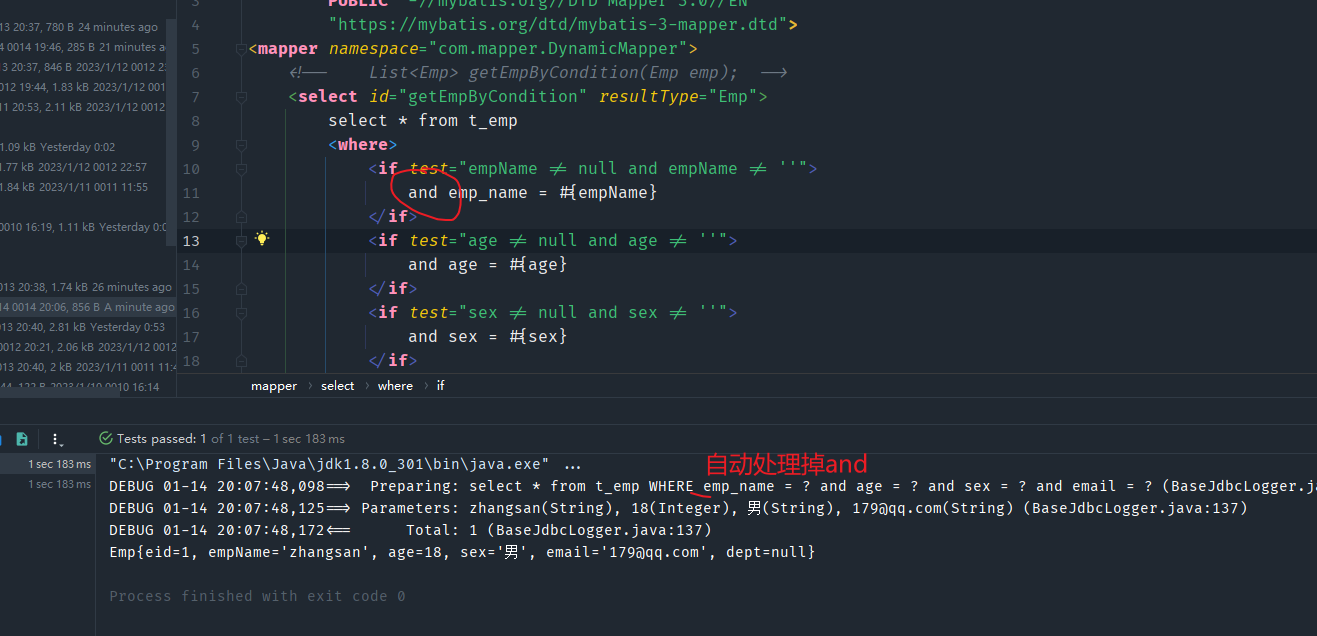
<select id="getEmpByCondition" resultType="Emp">
select * from t_emp where 1 = 1
<if test="empName != null and empName != ''">
and emp_name = #{empName}
</if>
<if test="age != null and age != ''">
and age = #{age}
</if>
<if test="sex != null and sex != ''">
and sex = #{sex}
</if>
<if test="email != null and email !=''">
and email = #{email}
</if>
</select>
测试代码
DynamicMapper mapper = sqlSession.getMapper(DynamicMapper.class);
Emp emp = new Emp(null, "zhangsan", 18, "男", "179@qq.com");
List<Emp> list = mapper.getEmpByCondition(emp);
list.forEach(System.out::println);
注意:
- 在使用if标签来实现SQL拼接时,tset属性中是判断条件,只有此条件为真时,标签体中的SQL才会拼接上去。
- 由于在XML中不能直接使用"&&"来作为判断的逻辑表达,所以要使用“and”这个关键字来表示 ”与“
- 在查询时,为了防止拼接SQL时发生语法错误,一般习惯在查询的SQL语句后面加上
1=1这个恒成立的式子,其他需要拼接的sql语句前都加上and
where
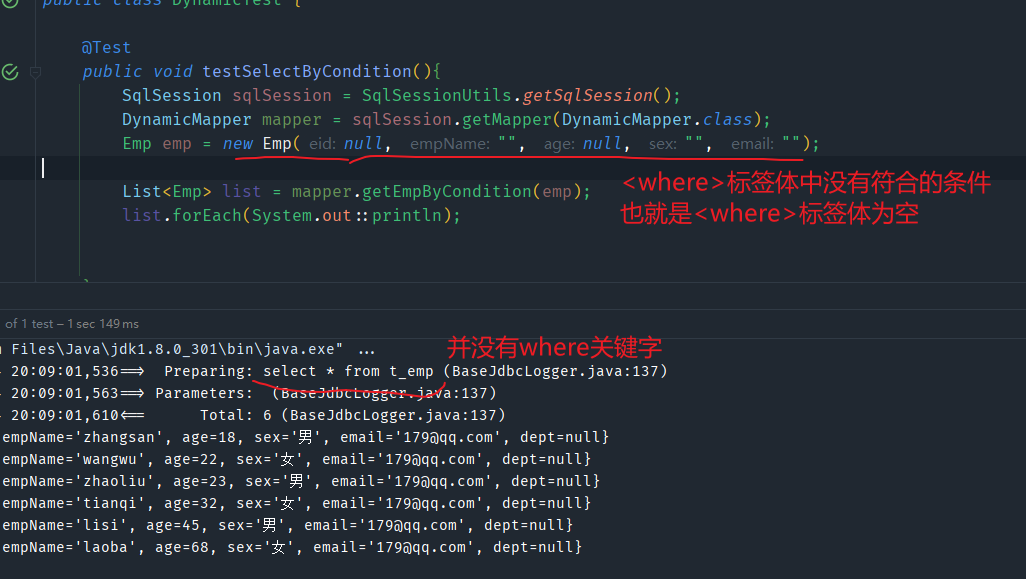
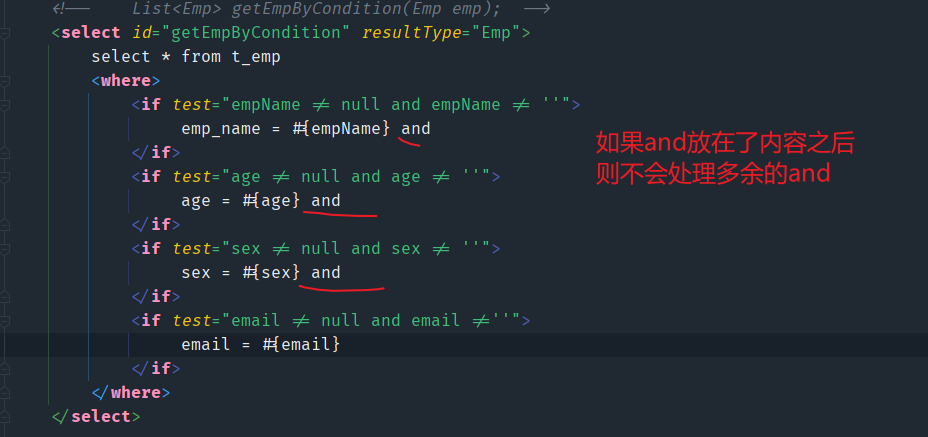
对于以上的使用if标签来拼接查询条件的情况,如果后面的if标签都不成立,那么where关键字就显得多余。
所以在MyBatis中,提供了where关键字动态生成的标签<where>标签
- where标签会根据标签体中是否有内容来动态的生成sql语句中的
where关键字 - where标签会自动处理标签体中的and和or关键字,会将内容前多余的and和or删除
来看使用<where>标签的映射文件中的SQL语句,现在就可以不用加1=1的条件了
<select id="getEmpByCondition" resultType="Emp">
select * from t_emp
<where>
<if test="empName != null and empName != ''">
and emp_name = #{empName}
</if>
<if test="age != null and age != ''">
and age = #{age}
</if>
<if test="sex != null and sex != ''">
and sex = #{sex}
</if>
<if test="email != null and email !=''">
and email = #{email}
</if>
</where>
</select>
trim
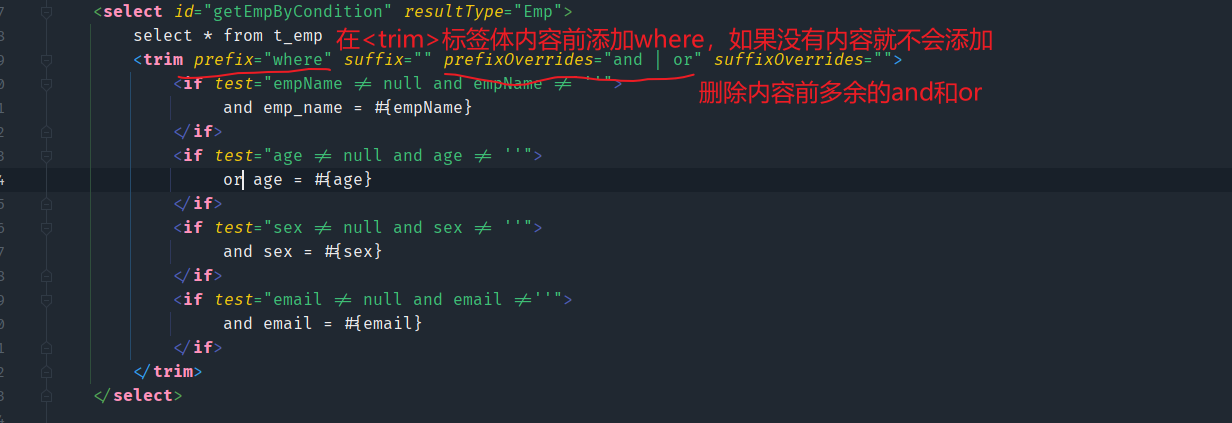
where标签 会将内容前 的多余的and和or去除,但是内容后多余的and和or就不会删除。
trim标签可以用来在内容前添加指定内容,也可以在内容后删除多余的内容
- prefix | suffix : 在trim标签体的内容前 或 后 添加指定内容
- prefixOverrides | suffixOverrides : 删除trim标签中, 内容前 或 后的指定内容
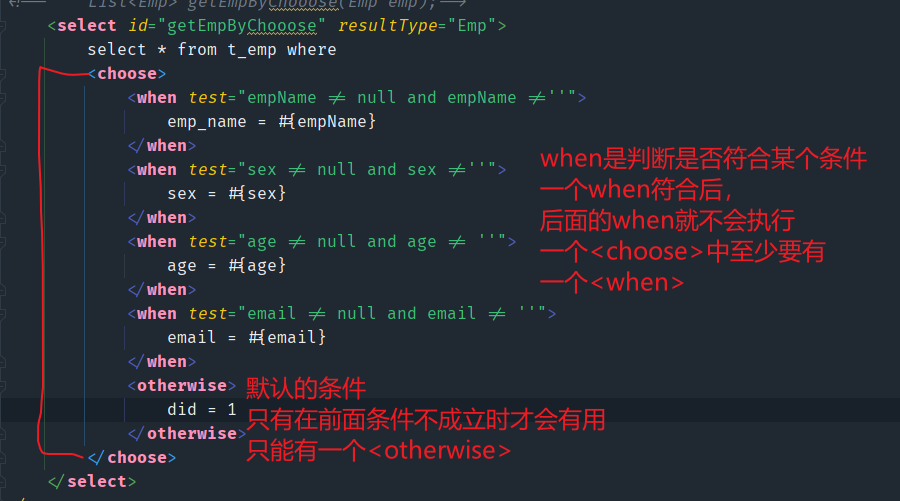
choose、when、otherwise
choose、when、otherwise这是一套标签,相当于Java中的swtich、case、default
在学习JSP时,JSTL中也有这样的用法。
when和otherwise需要写在choose标签中
如果使用多个if来判断,那么这几个if都会执行判断。如果使用choose、when来判断,有一个符合,其余的就不会执行。
forEach
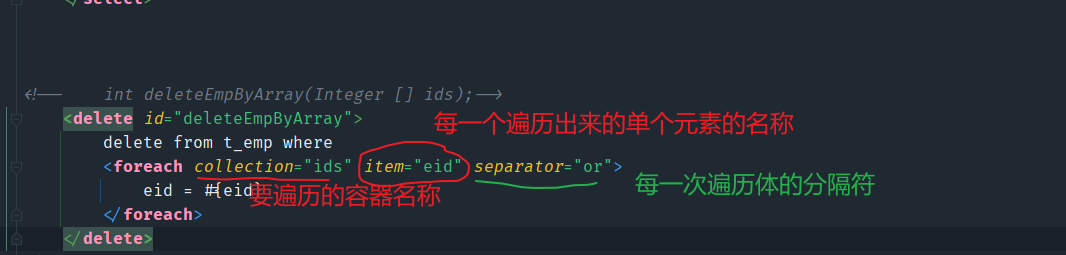
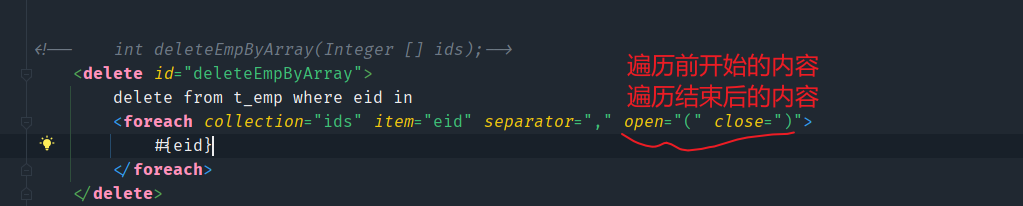
当方法的参数是一个数组或集合时,映射文件中的SQL语句应该如何处理参数?
这时就需要用到forEach这个标签了,能够遍历容器,将容器中的参数动态地拼接到SQL语句中。
参数是数组
来实现一个批量删除的功能,方法的参数是一个数组
批量删除对应的SQL应该是
delete from t_user where id = 1 or id =2 or id = 3
// 或
delete from t_user where id in (1,2,3)
这是对应的接口方法
/**
* 通过数组实现批量删除,测试MyBatis中的forEach标签
* @param ids Integer[]
* @return 影响的行数
*/
int deleteEmpByArray(@Param("ids") Integer [] ids);
当我们传递的参数是一个数组时,MyBatis也会将这个数组对象放到Map集合中,默认以array和arg为键
所以建议使用@Param()注解来为每一接口参数都设置别名

来看映射文件中的SQL语句
参数是集合
通过List集合来实现批量添加的功能。
批量添加的SQL语句应该是
insert into t_user values (...),(...),(...)
这是接口方法
/**
* 通过集合来实现批量添加,测试MyBatis中的forEach标签
* @param emps List集合
* @return 受影响的行数
*/
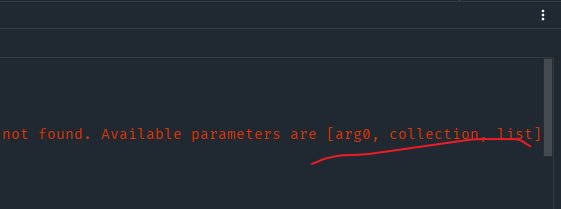
int insertByList(@Param("emps") List<Emp> emps);
集合类型的参数,MyBatis也会将其加入到Map中,默认的键为arg、collection、list
所以建议使用@Param在每一个接口参数上都添加别名
来看映射文件

sql
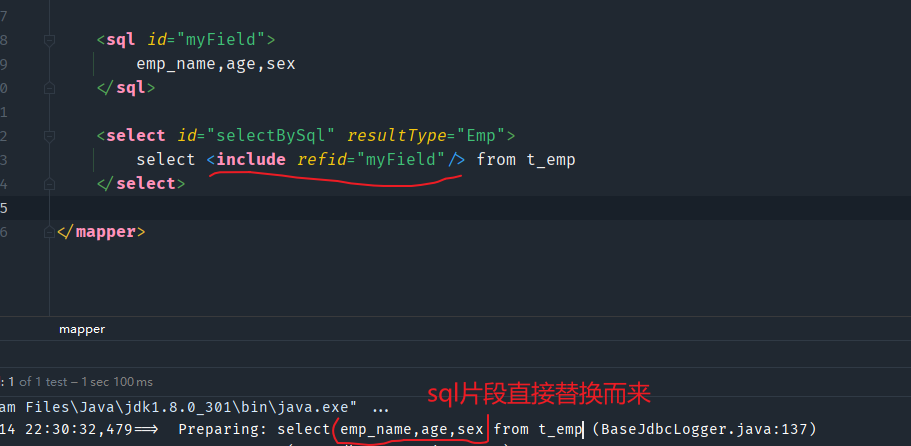
sql标签用来定义SQL片段,SQL片段就是从SQL语句中截取出来的一个片段。
这个标签的用处就是定义我们一些常用的SQL标签,然后在SQL语句的部分直接引用这个SQL标签,然后就会直接在引用处插入我们的SQL标签。
比如说,我们经常写的SQL语句是select * ,这样写是图方便,但是在实际开发中是不能这样写的,严重影响查询的性能。应该是需要哪个字段就写哪个字段select name,age。
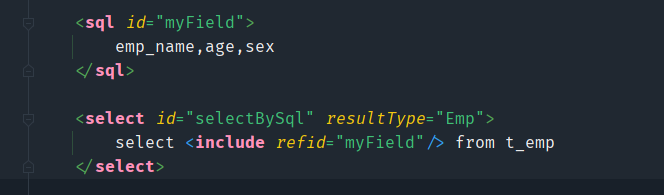
- 使用sql标签来定义sql片段
- 使用include标签来引用片段
MyBatis的缓存
MyBatis的一级缓存
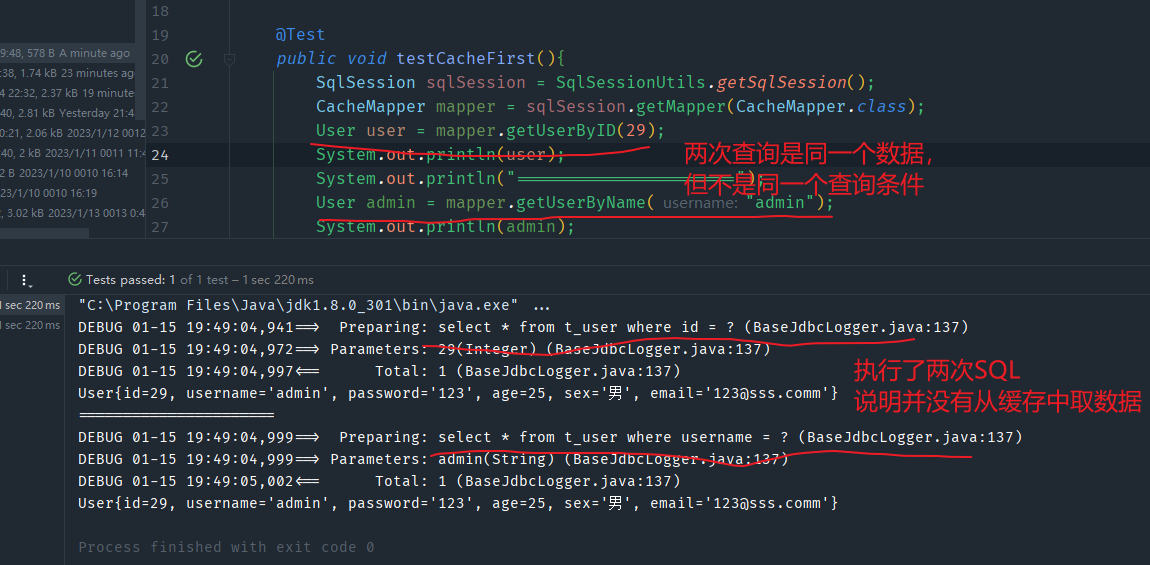
一级缓存是SqlSession级别的
通过同一个SqlSession查询的数据会被缓存,下次查询相同的数据,就会从缓存中直接获取,不会从数据库重新访问
使一级缓存失效的四种情况:
- 不同的SqlSession对应不同的一级缓存
- 同一个SqlSession但是查询条件不同
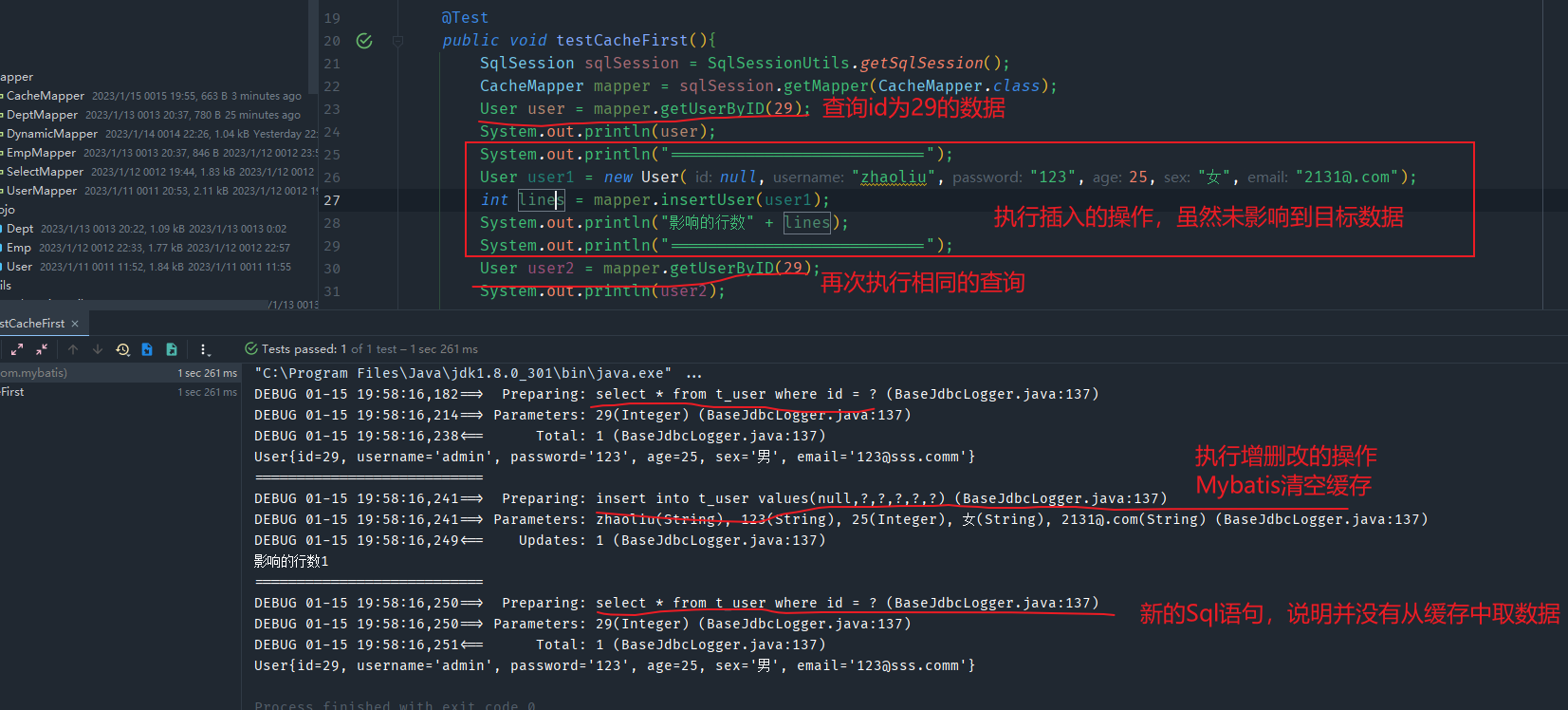
- 同一个SqlSession两次查询期间执行了任何一次增删改操作
- 同一个SqlSession两次查询期间手动清空了缓存

MyBatis一级失效情况:
第一种:不同的SqlSession,也就是不同的会话,每个会话都单独有一个缓存
第二种:使用同一SQLSession查询同一数据,但是查询条件不同
第三种:同一SQLSession,但是两次查询中间执行了增删改的操作,不管中间的这个增删改操作是否影响了这个数据,MyBatis都会清空缓存。
第四种:在两次查询之间手动执行了清空缓存

MyBatis的二级缓存
二级缓存的范围是要比一级缓存的范围要大的,需要手动开启。
二级缓存是SqlSessionFactory级别,通过同一个SqlSessionFactory创建的SqlSession查询的结果会被缓存;此后若再次执行相同的查询语句,结果就会从缓存中获取二级缓存是SqlSessionFactory级别,通过同一个SqlSessionFactory创建的SqlSession查询的结果会被缓存;此后若再次执行相同的查询语句,结果就会从缓存中获取
当SqlSession被关闭或提交前,会在一级缓存中保存数据,当SqlSession关闭或提交后,会在二级缓存中保存数据。
二级缓存开启的步骤
在MyBatis的配置文件中,设置全局属性cacheEnabled=“true”,默认是true,不需要设置
在映射文件中设置标签
<cache>
二级缓存必须在SqlSession关闭或提交之后有效
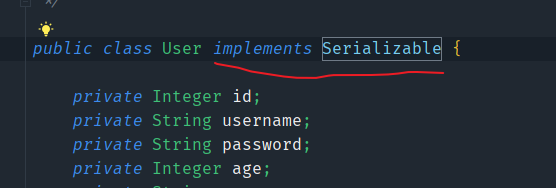
查询的数据所转换的实体类类型必须实现序列化接口
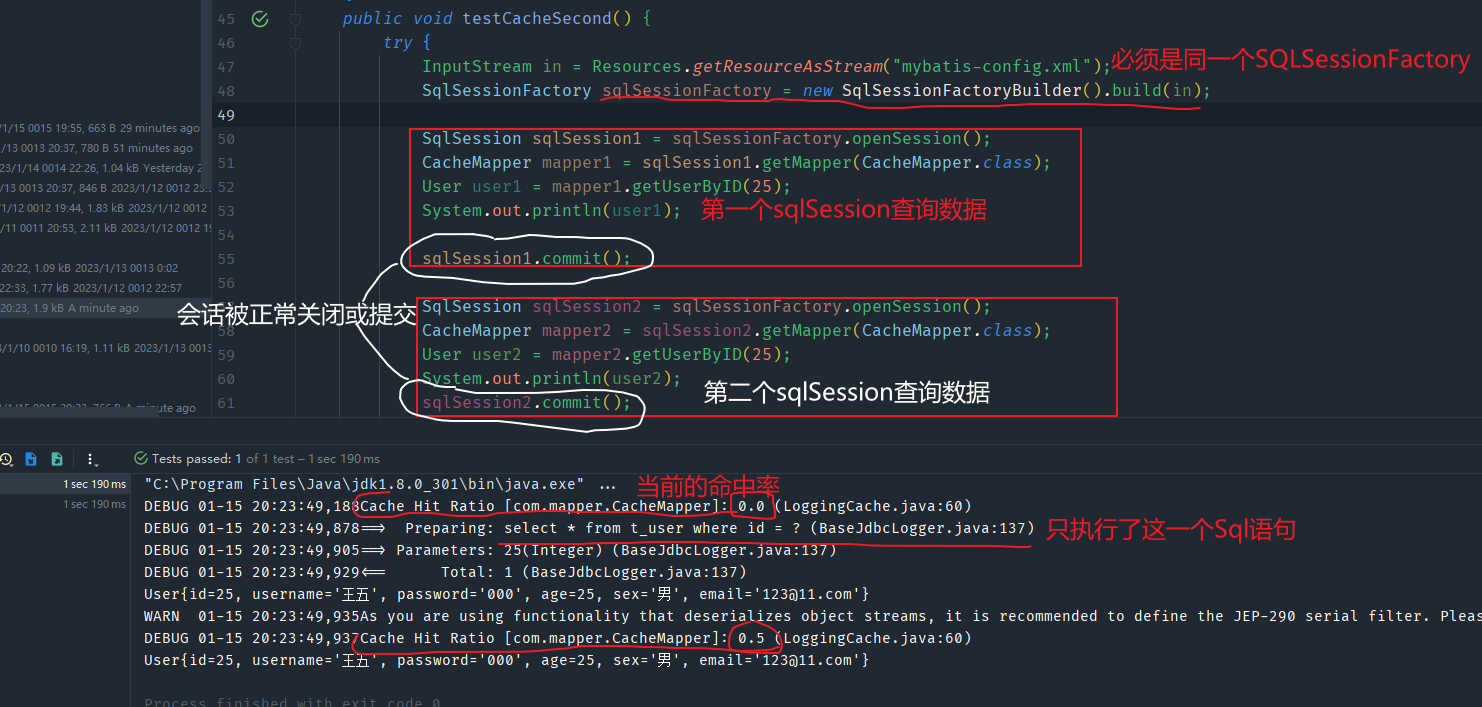
二级缓存失败的情况:两次查询之间执行了任意的增删改,会清空一级和二级缓存
二级缓存的配置信息
在映射文件中的<cache>标签中,设置二级缓存的配置信息。
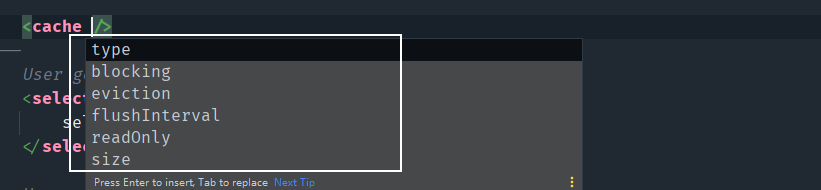
这些属性分别是
-
eviction:缓存回收策略(操作系统中学过)-
LRU(Least Recently Used) – 最近最少使用的:移除最长时间不被使用的对象。
-
FIFO(First in First out) – 先进先出:按对象进入缓存的顺序来移除它们。
-
SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
-
WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
默认的是 LRU
-
-
flushInterval:缓存刷新间隔,单位是毫秒默认不设置,也就是没有刷新,缓存仅有在调用操作(增删改)时刷新
-
size:引用数目,正整数代表缓存最多可以存储多少个对象,太大容易导致内存溢出
-
readOnly属性:只读,true/false
true:只读缓存;会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了
很重要的性能优势。
false:读写缓存;会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
缓存查询的顺序
- 先查询二级缓存,因为二级缓存中可能会有其他程序已经查出来的数据,可以拿来直接使用。
- 如果二级缓存没有命中,再查询一级缓存
- 如果一级缓存也没有命中,则查询数据库
- SqlSession关闭之后,一级缓存中的数据会写入二级缓存
整合第三方EHCache
MyBatis提供了缓存接口,允许接入更优秀的缓存框架作为MyBatis的二级缓存。
接入的缓存只能代替二级缓存,不能代替一级缓存。
介绍一个优秀的缓存框架EHCache
- 导入jar包(只需要导入一个包,Maven就会帮我们自动导入其依赖的其他包)
<!-- Mybatis EHCache整合包 -->
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.1</version>
</dependency>
<!-- slf4j日志门面的一个具体实现 -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
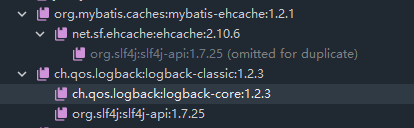
| jar包名称 | 作用 |
|---|---|
| mybatis-encache | MyBatis与EHCache的整合包 |
| EHCahe | EHCache的核心包 |
| slf4j-api | SLF4J日志门面包 |
| logback-classic | 支持SLF4j接口的一个具体实现 |
- 创建EHCache的配置文件,这个名称必须交
ehcache.xml
<?xml version="1.0" encoding="utf-8" ?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
<!-- 磁盘保存路径 -->
<diskStore path="D:\test\ehcache"/>
<defaultCache
maxElementsInMemory="1000"
maxElementsOnDisk="10000000"
eternal="false"
overflowToDisk="true"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU">
</defaultCache>
</ehcache>
- 在映射文件中二级日志的类型为EHCache
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
- 导入SLF4j的配置文件
因为导入了SLF4j的依赖,所以简单的log4j可能会失效,需要使用logback这个日志,创建logback.xml的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="true">
<!-- 指定日志输出的位置 -->
<appender name="STDOUT"
class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- 日志输出的格式 -->
<!-- 按照顺序分别是:时间、日志级别、线程名称、打印日志的类、日志主体内容、换行 -->
<pattern>[%d{HH:mm:ss.SSS}] [%-5level] [%thread] [%logger] [%msg]%n</pattern>
</encoder>
</appender>
<!-- 设置全局日志级别。日志级别按顺序分别是:DEBUG、INFO、WARN、ERROR -->
<!-- 指定任何一个日志级别都只打印当前级别和后面级别的日志。 -->
<root level="DEBUG">
<!-- 指定打印日志的appender,这里通过“STDOUT”引用了前面配置的appender -->
<appender-ref ref="STDOUT"/>
</root>
<!-- 根据特殊需求指定局部日志级别 -->
<logger name="com.mapper" level="DEBUG"/>
</configuration>
EHCache的配置文件
| 属性名 | 是否必须 | 作用 |
|---|---|---|
| maxElementsInMemory | 是 | 在内存中缓存的element的最大数目 |
| maxElementsOnDisk | 是 | 在磁盘上缓存的element的最大数目,若是0表示无穷大 |
| eternal | 是 | 设定缓存的elements是否永远不过期。 如果为true,则缓存的数据始终有效, 如果为false那么还要根据timeToIdleSeconds、timeToLiveSeconds判断 |
| overflowToDisk | 是 | 设定当内存缓存溢出的时候是否将过期的element缓存到磁盘上 |
| timeToIdleSeconds | 否 | 当缓存在EhCache中的数据前后两次访问的时间超过timeToIdleSeconds的属性取值时, 这些数据便会删除,默认值是0,也就是可闲置时间无穷大 |
| timeToLiveSeconds | 否 | 缓存element的有效生命期,默认是0,也就是element存活时间无穷大 |
| diskSpoolBufferSizeMB | 否 | DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区 |
| diskPersistent | 否 | 在VM重启的时候是否启用磁盘保存EhCache中的数据,默认是false。 |
| diskExpiryThreadIntervalSeconds | 否 | 磁盘缓存的清理线程运行间隔,默认是120秒。每隔120s, 相应的线程会进行一次EhCache中数据的清理工作 |
| memoryStoreEvictionPolicy | 否 | 当内存缓存达到最大,有新的element加入的时候, 移除缓存中element的策略。 默认是LRU(最近最少使用),可选的有LFU(最不常使用)和FIFO(先进先出) |
MyBatis逆向工程
首先要知道什么是正向工程,什么是逆向工程:
- 正向工程:先创建Java实体类,由框架负责根据实体类生成数据库表。Hibernate是支持正向工程的
- 逆向工程:向创建数据库表,由框架负责根据数据库表,反向生成如下资源
- Java实体类
- Mapper接口
- Mapper映射文件
创建逆向工程的步骤
- 导入依赖
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.11</version>
</dependency>
</dependencies>
<build>
<!-- 构建过程中用到的插件 -->
<plugins>
<!-- 具体插件,逆向工程的操作是以构建过程中插件形式出现的 -->
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.0</version>
<!-- 插件的依赖 -->
<dependencies>
<!-- 逆向工程的核心依赖 -->
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.2</version>
</dependency>
<!-- 数据库连接池 -->
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.2</version>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.31</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
- 创建MyBatis的核心配置文件
这个跟逆向工程没有关系,但是MyBatis要用
- 创建逆向工程的配置文件
配置文件的名称必须是generatorConfig.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<context id="DB2Tables" targetRuntime="MyBatis3Simple">
<!--
targetRuntime: 执行生成的逆向工程的版本,有两个值
MyBatis3Simple: 生成基本的CRUD(清新简洁版)
MyBatis3: 生成带条件的CRUD(奢华尊享版)
-->
<!-- 数据库的连接信息 -->
<jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/mybatis"
userId="root"
password="root">
</jdbcConnection>
<!-- javaBean的生成策略-->
<!-- targetPackage:生成的Bean放的包的位置
targetProject:包放在哪里,
-->
<javaModelGenerator targetPackage="com.mybatis.pojo"
targetProject=".\src\main\java">
<!-- enableSubPackages:是否使用子包,
true表示com.mybatis.pojo是层级的包
false表示“com.mybatis.pojo"这是一个目录名称
trimStrings: 去掉字段名称前后的空格
-->
<property name="enableSubPackages" value="true"/>
<property name="trimStrings" value="true"/>
</javaModelGenerator>
<!-- SQL映射文件的生成策略 -->
<sqlMapGenerator targetPackage="com.mybatis.mapper"
targetProject=".\src\main\resources">
<property name="enableSubPackages" value="true"/>
</sqlMapGenerator>
<!-- Mapper接口的生成策略 -->
<javaClientGenerator type="XMLMAPPER"
targetPackage="com.mybatis.mapper" targetProject=".\src\main\java">
<property name="enableSubPackages" value="true"/>
</javaClientGenerator>
<!-- 逆向分析的表 -->
<!-- tableName设置为*号,可以对应所有表,此时不写domainObjectName -->
<!-- domainObjectName属性指定生成出来的实体类的类名 -->
<table tableName="t_emp" domainObjectName="Emp"/>
<table tableName="t_dept" domainObjectName="Dept"/>
</context>
</generatorConfiguration>
一切准备就绪之后,直接使用Maven中导入的插件就可以。
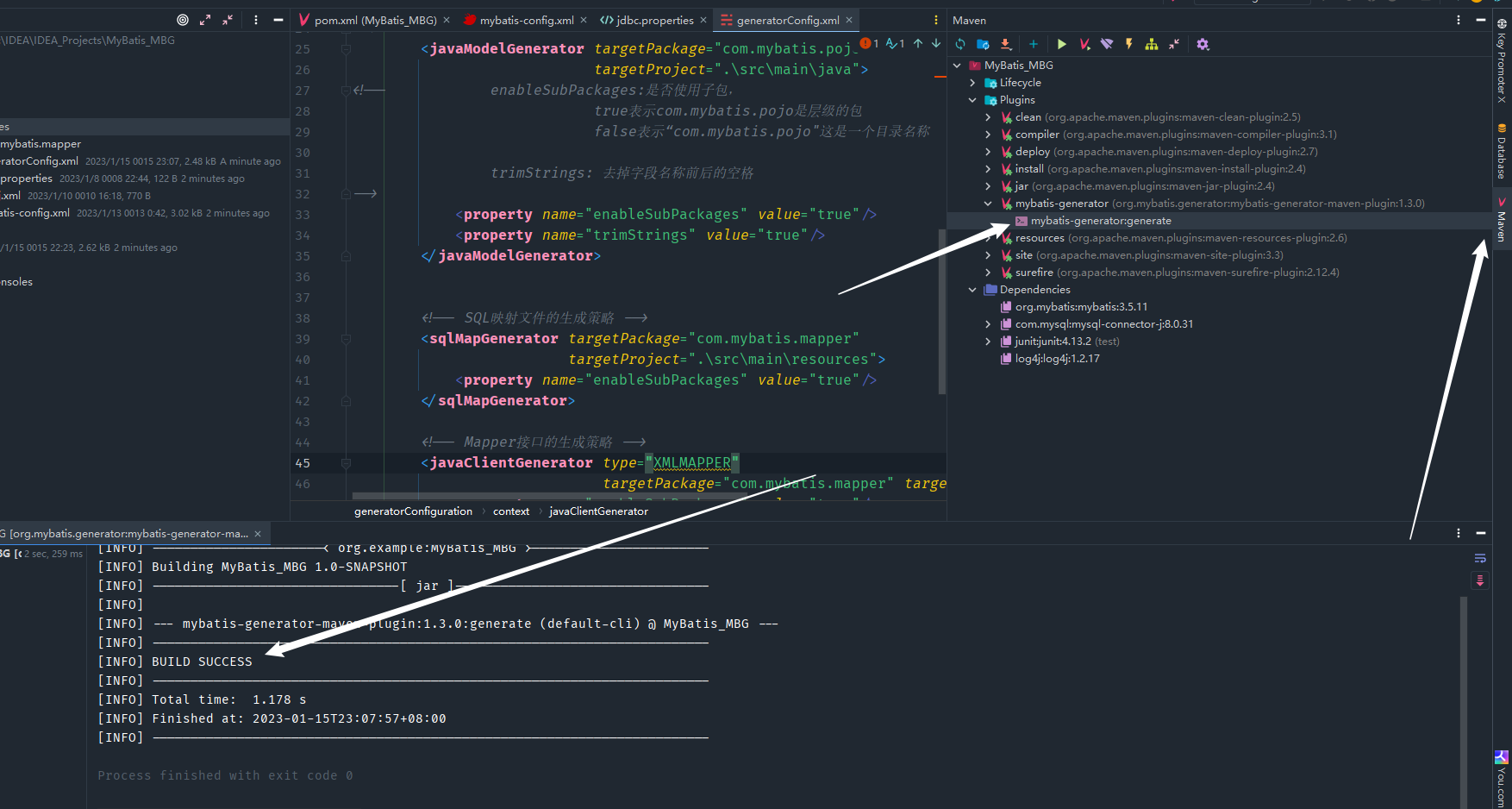
然后看自己的项目目录,就会看到自动生成的实体类、Mapper接口、映射文件
生成工具会根据表的字段名称,自动生成POJO对应的属性名称。
MyBatis3Simple——简单版
上面在演示时,指定的执行逆向工程的版本是MyBatis3Simple,这个是简单版本的生成工具。
会在对应的Mapper接口中生成5个方法
- 插入(参数为实体类)
- 根据主键查询
- 查询全部
- 根据主键修改
- 根据主键删除
其余方法需要自己写。
MyBatis3——高级版
由于简单版自动生成的内容较少,一般使用这个高级版会更多一些。
接下来就是使用这个高级版的生成工具来生成一下相关的实体类、Mapper接口、映射文件。
首先把刚才的简单版的生成的内容删除掉。
然后将构建生成工具对应的配置文件中的targetRuntime更改为MyBatis3
找到Maven插件,双击运行即可。
会看到这个高级版的生成工具,帮我们生成的实体类更多了,而且Mapper接口中的方法更多了。
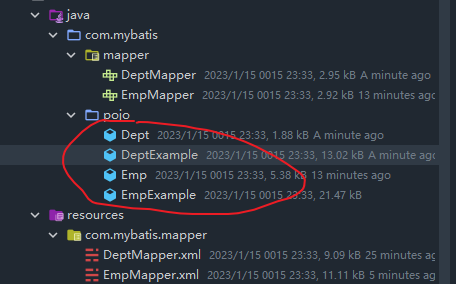
其中:带Example的实体类是封装了各种条件的实体类,可以将这个实体类作为接口方法的参数类型。
基本使用
在高级版中,每一个实体类,都额外多对应一个Example的实体类,这个实体类用来封装查询条件,非常强大。
在Mapper接口中,会有方法名称后面带Example的方法,这就是根据查询条件来查询。
如何使用?
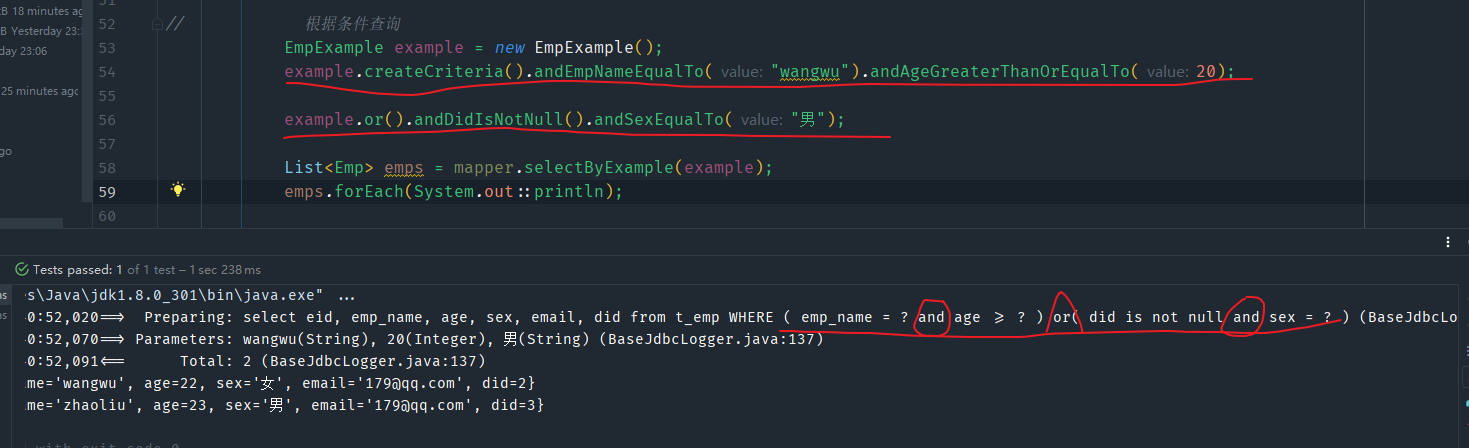
查询

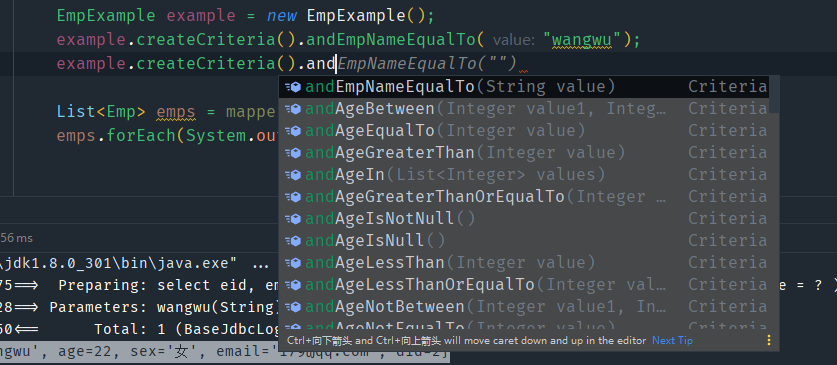
我们只需要在创建条件的createCriteria()方法后继续调用,以and开头,后面跟上自己实体类的属性名称,就会看到这个属性相关的很多的方法,创建完成条件之后,将这个条件对象传递个对应的Mapper方法,就会得到查询的的实体类对象或集合。
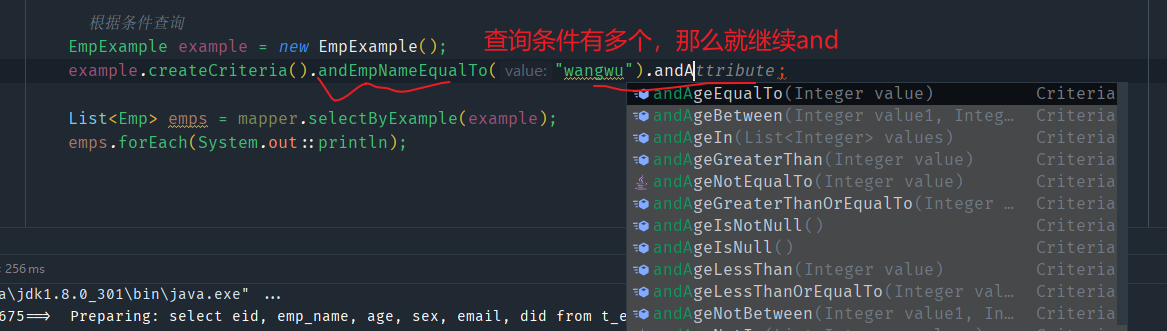
createCriteria()方法后面的多个条件之间连接都是and(生成后对应的SQL语句where后面的条件之间是and)
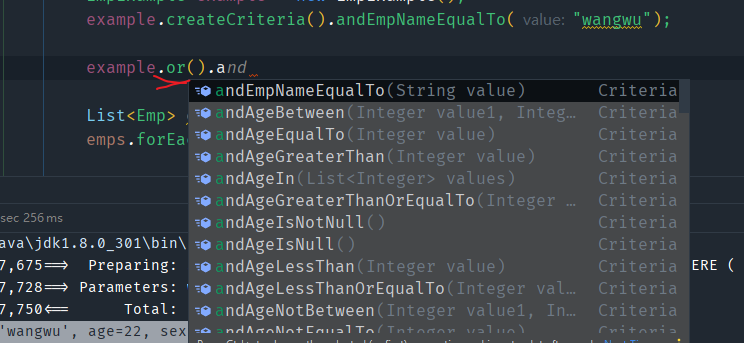
如果想要多个条件之间表示“或”,可以调用条件对象的or()方法,然后继续and+属性+条件
修改
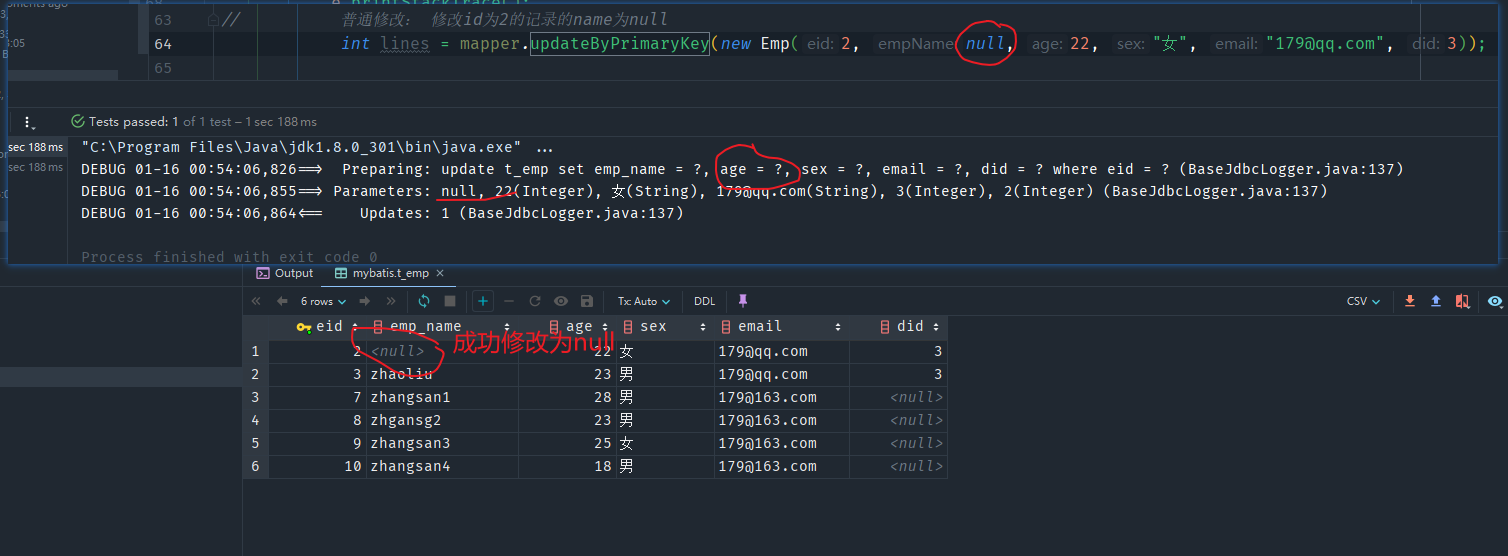
还有这个Mapper接口方法中的修改、添加的功能,Mapper接口也有对应的Example的方法。
- 如果方法名称后面没有
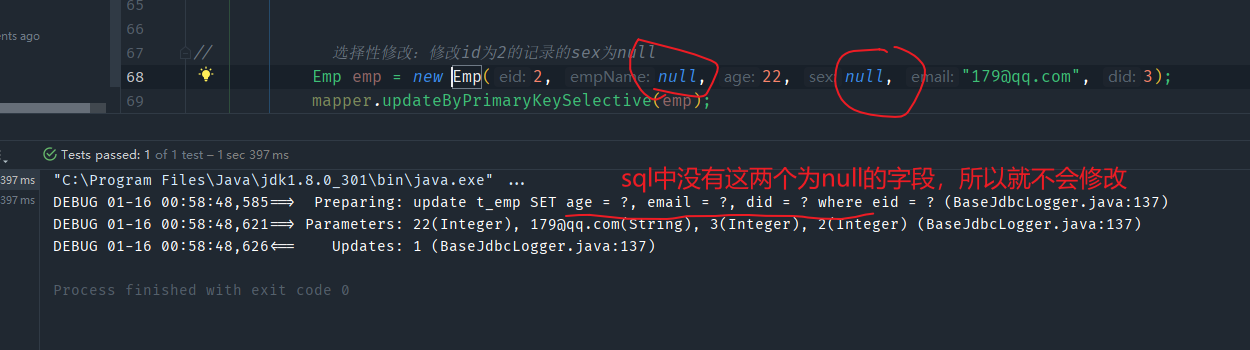
Selective这个单词,那就是一个普通的添加/删除,如果某个字段为null,那么就修改为null - 如果方法名称后面有
Selective这个单词,此时,如果某个字段为null,则不会将这个字段作为where的条件
先来看普通的方法(不带Selective单词的)
再来看带Selective单词的
MyBatis分页插件
在MySQL中的分页功能,需要我们书写对应的sql语句。
SELECT * FROM t_user LIMIT index,pageSize
其中
index: 当前页的首行索引,从0开始
pageNum:当前显示的页码
pageSize:每页显示的条数
index = (pageNum - 1)*pageSize
在MyBatis中,可以通过一个分页插件来实现分页功能。
基本使用
- 导入依赖
<!--分页插件-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.2.0</version>
</dependency>
- 添加分页插件,在MyBatis的配置文件中配置分页的插件,注意MyBatis配置文件中标签的顺序
<plugins>
<!--设置分页插件-->
<plugin interceptor="com.github.pagehelper.PageInterceptor"/>
</plugins>
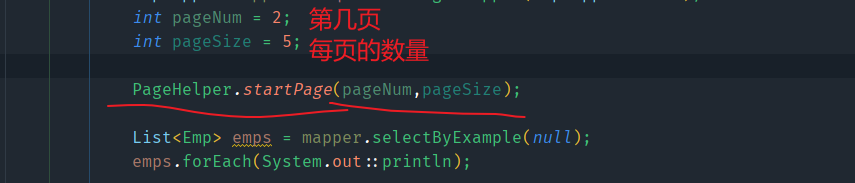
- 接下来的使用
因为分页功能是针对查询的,所以我们在查询方法执行前,开启并设置分页的基本参数即可。
分页信息
刚才我们是使用的PageHelper.startPage(pageNum,pageSize)这个方法来开启并设置分页的。
其实这个方法还有一个返回值,是一个封装了分页信息的Page对象,我们来看一下。
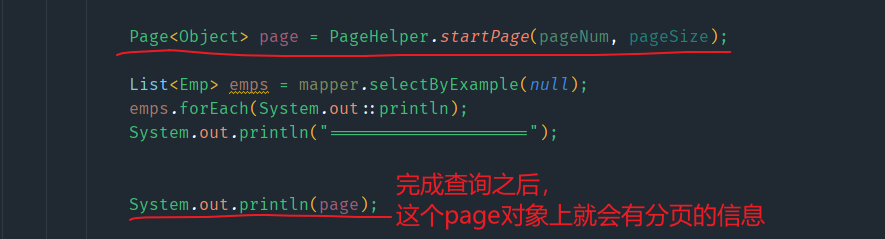
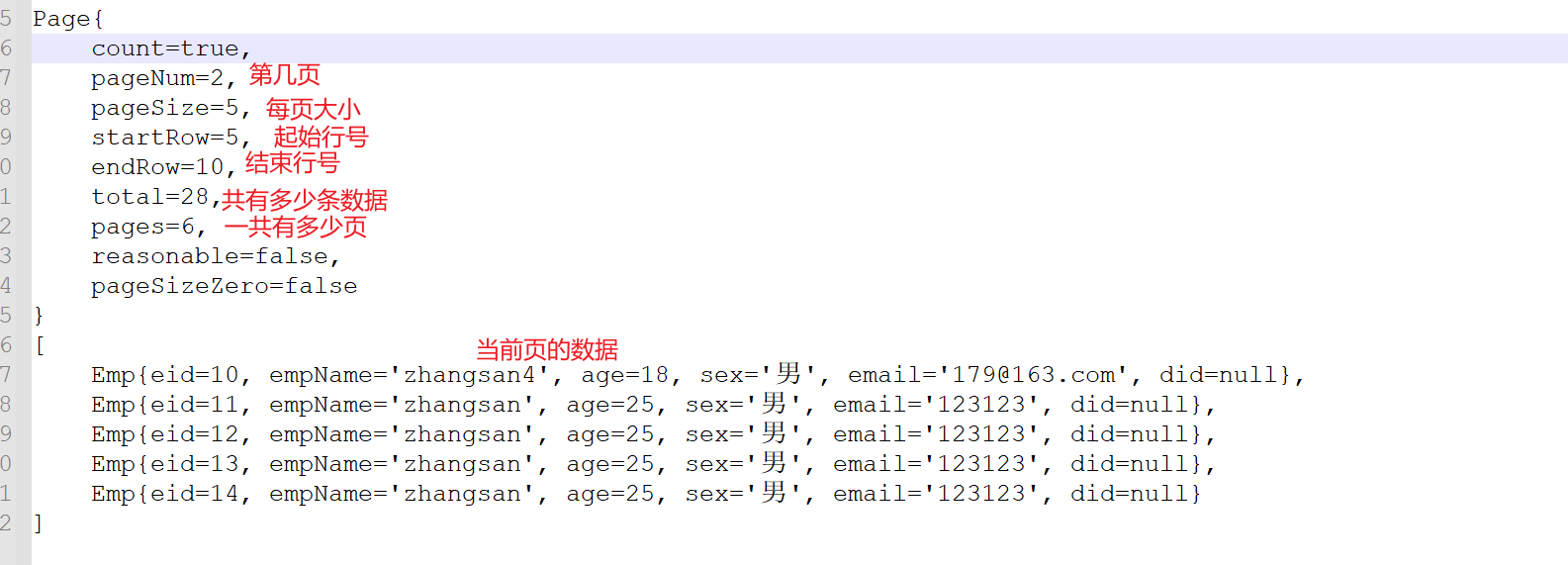
这些分页信息可以作为前台分页的数据,响应给前台,也可以将Page对象在JSP中作为域属性来访问这些分页信息。
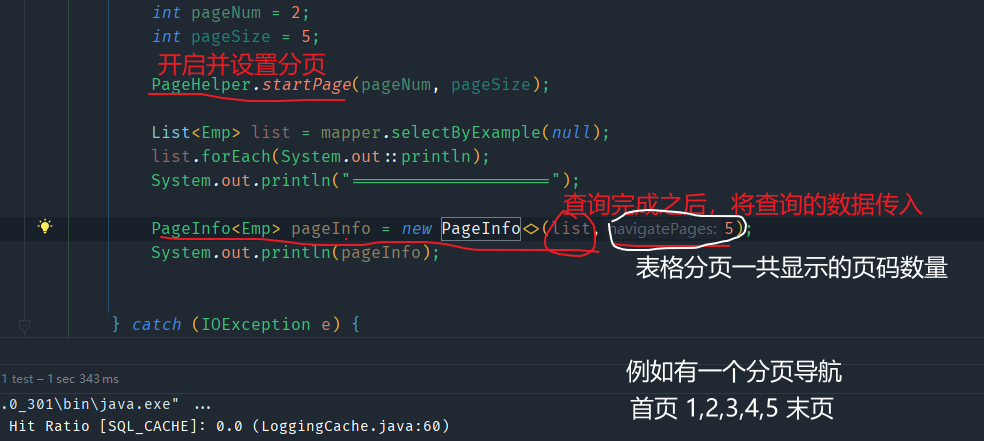
如果还想要更详细的分页信息,非常非常详细

总结
-
通过
PageHelper.start(pageNum,pageSize)来开启并设置分页功能 -
如果想要获取分页信息,可以在查询后,通过
PageHelper.start()方法的返回对象Page对象来获取一定要在查询之后再去获取Page身上的信息
-
如果想要获取更详细的分页信息,可以通过
PageInfo来获取,传入查询后的数据。
MyBatis注解开发
可以使用注解来完成一些简单的功能的开发,但是复杂的功能还是需要使用映射文件的方式。
参考文章MyBatis注解开发
基本的增删改查
首先是基本的增删改查的四个功能,分别对应这四个注解
| 注解 | 功能 | 样例 |
|---|---|---|
| @Insert | 实现插入功能 | @Insert(“insert into t_emp values(null,#{empName},#{age},#{sex},#{email},null)”) |
| @Delete | 实现删除功能 | @Delete(“delete from t_emp where eid = #{eid}”) |
| @Update | 实现修改功能 | @Update(“update t_emp set emp_name = #{empName},age=#{age},sex=#{sex},email= #{email} where eid = #{eid}”) |
| @Select | 实现查询功能 | @Select(“select * from t_emp where did = #{did}”) |
我们正常在映射文件中书写的Sql语句,直接在这些注解中写就可以,就不需要映射文件了。
/**
* 测试@Select注解,根据部门id返回查询结果
* @param did Integer
* @return
*/
@Select("select * from t_emp where did = #{did}")
List<Emp> selectByDid(@Param("did") Integer did);
正常调用即可。
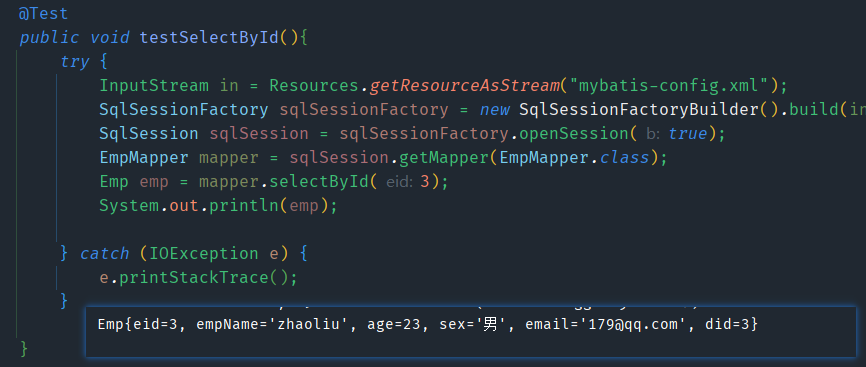
注解实现复杂映射
在使用映射文件来开发时,我们会使用<resultMap>来完成复杂的映射关系,像这样
<reslutMap>
<id></id>
<result></result>
<association></association>
<collection></collection>
</reslutMap>
其中
<id>标签用来指定表的主键字段与实体类属性的映射关系,<result>是普通的字段与实体类属性的映射关系.<association>表示多对一的关系<collection>表示一对多的关系
在注解中也有一个类似注解,其中
@Results注解相当于<resultMap>标签@Result注解相当于<resultMap>中的<id>和<result>标签@One注解实现一对一的关系@Many注解是多对一的关系
在@Result注解中有叫one和many的属性,这两个属性的值就是通过@One和@Many来实现
一对一的关系
一个员工只能属于一个部门,那么员工与部门是一对一,此时可以使用@One注解来实现。
员工的实体类中需要有一个部门类的属性。
public class Emp {
private Integer eid;
private String empName;
private Integer age;
private String sex;
private String email;
private Integer did;
private Dept dept;
public Emp(Integer eid, String empName, Integer age, String sex, String email) {
this.eid = eid;
this.empName = empName;
this.age = age;
this.sex = sex;
this.email = email;
}
public Emp() {
}
@Override
public String toString() {
return "Emp{" +
"eid=" + eid +
", empName='" + empName + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
", email='" + email + '\'' +
", did=" + did +
'}';
}
public Dept getDept() {
return dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
public Integer getEid() {
return eid;
}
public void setEid(Integer eid) {
this.eid = eid;
}
public String getEmpName() {
return empName;
}
public void setEmpName(String empName) {
this.empName = empName;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Integer getDid() {
return did;
}
public void setDid(Integer did) {
this.did = did;
}
}
这是EmpMapper接口的方法
/**
* 测试一对一,@One注解的使用
* @param eid Integer
* @return
*/
@Select("select * from t_emp where eid = #{eid}")
@Results({
@Result(id = true,property = "eid",column = "eid"),
@Result(property = "empName",column = "emp_name"),
@Result(property = "age",column = "age"),
@Result(property = "email",column = "email"),
@Result(property = "did",column = "did"),
@Result(property = "dept",column = "did",one = @One(select = "com.mybatis.mapper.DeptMapper.selectDept"))
})
Emp selectEmpAndDept(@Param("eid") Integer eid);
这是DeptMapper接口中的方法
/**
* 根据id获取部门信息
* @param did
* @return
*/
@Select("select * from t_dept where did = #{did}")
Dept selectDept(@Param("did") Integer did);
一对多的映射
员工与部门的关系, 一个部门可以有多个员工, 部门与员工的关系就是一对多。
通过@Many来实现
首先在部门的实体类中加入一个List属性
public class Dept {
private Integer did;
private String deptName;
private List<Emp> emps;
public List<Emp> getEmps() {
return emps;
}
@Override
public String toString() {
return "Dept{" +
"did=" + did +
", deptName='" + deptName + '\'' +
", emps=" + emps +
'}';
}
public void setEmps(List<Emp> emps) {
this.emps = emps;
}
public Dept() {
}
public Dept(Integer did, String deptName) {
this.did = did;
this.deptName = deptName;
}
public Integer getDid() {
return did;
}
public void setDid(Integer did) {
this.did = did;
}
public String getDeptName() {
return deptName;
}
public void setDeptName(String deptName) {
this.deptName = deptName;
}
}
这是EmpMapper接口中的方法
/**
* 测试@Select注解,根据部门id返回查询结果
* @param did Integer
* @return
*/
@Select("select * from t_emp where did = #{did}")
List<Emp> selectByDid(@Param("did") Integer did);
这是DeptMapper接口中的方法
@Select("select * from t_dept where did = #{did}")
@Results(id = "deptAndEmpResultMap",value = {
@Result(id = true,property = "did",column = "did"),
@Result(property = "deptName", column = "dept_name"),
@Result(property = "emps", column = "did",many = @Many(select = "com.mybatis.mapper.EmpMapper.selectByDid"))
})
Dept selectDeptAndEmp(@Param("did") Integer did);
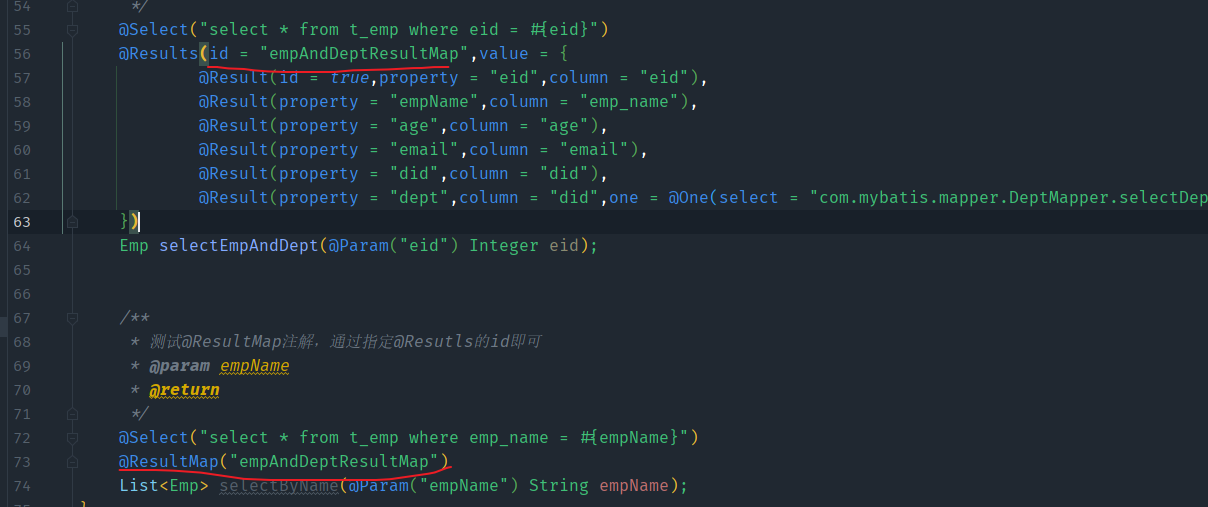
如果某一个映射关系经常被用到,还可以直接使用@ResultMap这个注解来实现,需要在@Results注解中有id属性。
注解设置二级缓存
-
首先在MyBatis的配置文件中,设置全局属性cacheEnabled=“true”,默认是true,不需要设置。
-
实体类实现序列化接口
-
在需要开启二级缓存的Mapper接口上使用
@CacheNamespace(blocking = true)
@CacheNamespace(blocking = true)
public interface EmpMapper {
/**
* 测试Mybatis中的@Select注解
* @param eid Integer
* @return Emp
*/
@Select("select * from t_emp where eid = #{eid}")
Emp selectById(@Param("eid") Integer eid);
/**
* 测试@Select注解,根据部门id返回查询结果
* @param did Integer
* @return
*/
@Select("select * from t_emp where did = #{did}")
List<Emp> selectByDid(@Param("did") Integer did);
/**
* 测试@Delete注解,根据id删除
* @param eid Integer
* @return
*/
@Delete("delete from t_emp where eid = #{eid}")
int deleteById(@Param("eid") Integer eid);
/**
* 测试@Update注解,根据id修改
* @param emp Emp
* @return
*/
@Update("update t_emp set emp_name = #{empName},age=#{age},sex=#{sex},email= #{email} where eid = #{eid}")
Integer updateById(Emp emp);
/**
* 测试@Insert注解,插入数据
* @param emp Emp
* @return
*/
@Insert("insert into t_emp values(null,#{empName},#{age},#{sex},#{email},null)")
int insert(Emp emp);
/**
* 测试一对一,@One注解的使用
* @param eid Integer
* @return
*/
@Select("select * from t_emp where eid = #{eid}")
@Results(id = "empAndDeptResultMap",value = {
@Result(id = true,property = "eid",column = "eid"),
@Result(property = "empName",column = "emp_name"),
@Result(property = "age",column = "age"),
@Result(property = "email",column = "email"),
@Result(property = "did",column = "did"),
@Result(property = "dept",column = "did",one = @One(select = "com.mybatis.mapper.DeptMapper.selectDept"))
})
Emp selectEmpAndDept(@Param("eid") Integer eid);
/**
* 测试@ResultMap注解,通过指定@Resutls的id即可
* @param empName
* @return
*/
@Select("select * from t_emp where emp_name = #{empName}")
@ResultMap("empAndDeptResultMap")
List<Emp> selectByName(@Param("empName") String empName);
}















 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









