







scrapy实例:爬新片场视频
写在前面
新片场地址
https://www.xinpianchang.com/channel/index/sort-like?from=navigator

1、新建项目
创建项目xpc:scrapy startproject xpc

在xpc项目根目录下创建虚拟环境:virtualenv env

启用虚拟环境:
cd env/Scripts/
activate.bat

在项目目录xpc/env/Scripts下,创建文件1.txt,用来保存我们需要用到的包名

编辑1.txt内容如下:
scrapy
redis
requests
pymysql
安装:pip install -r 1.txt

上面这一步,如果是在linux中,
创建文件:touch 1.txt
修改文件:vim 1.txt
创建爬虫文件discovery(注意:这一步在xpc根目录下进行)
scrapy genspider discovery xinpianchang.com
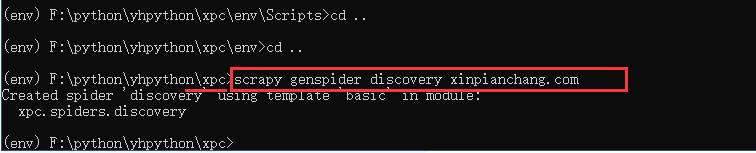
用pycharm打开项目


修改入口地址,我们要爬的是新片场的发现页


2、设置prcharm一键启动scrapy项目
先找到虚拟环境里 scrapy安装位置:where scrapy

复制地址,开始配置



运行试试

配置成功

3、爬取视频详情页
通过检查代码发现,每个视频都在 < ul class=“video-list” >这个标签里的 < li >标签里面

查看里面的a标签我们发现视频并不是直接以一个链接形式存在的

3.1、断点运行分析
我们查看事件也没有发现有用的信息:
鼠标点击事件、鼠标按下事件等目前只看到一些公用的函数


我们给点击事件增加一个断点运行试试

现在点一下第一个视频

分析了会jq里面的各个参数也并没有发现有用的信息


3.2、链接分析
断点运行分析没有发现有用的信息,我们点进一个视频,分析链接试试

我们发现链接里面包含数字,我们把这串数字在"发现页"搜索试试
选中Elements标签,用鼠标随便点html元素,然后按ctrl+f搜索

搜索结果显示每个li里面都有一串类似的数字

我们随便复制其中一个数字,带入链接里访问

所以这个网址每个视频的链接是https://www.xinpianchang.com/a数字串?from=ArticleList
我们只需要抓取每个li里面的数字串然后拼接,就能得到视频链接
3.3、xpath提取
CTRL+SHIFT+X 开启XPath Helper插件
提取数字串://@data-articleid

提取电影名://div[@class=“title-wrap”]/h3/text()

提取视频链接://video[@id=‘xpc_video’]/@src


3.4、代码
discovery.py
# -*- coding: utf-8 -*-
import scrapy
class DiscoverySpider(scrapy.Spider):
name = 'discovery'
allowed_domains = ['xinpianchang.com']
start_urls = ['https://www.xinpianchang.com/channel/index/sort-like?from=navigator']
def parse(self, response):
pid_list = response.xpath('//@data-articleid').extract()
url = "https://www.xinpianchang.com/a%s?from=ArticleList"
for pid in pid_list:
yield response.follow(url % pid, self.parse_post)
def parse_post(self, response):
post = {}
# 这里get()和extract_first()一样
post['title'] = response.xpath('//div[@class="title-wrap"]/h3/text()').get()
yield post
运行试试

4、爬取视频
4.1、分析页面
找到视频地址
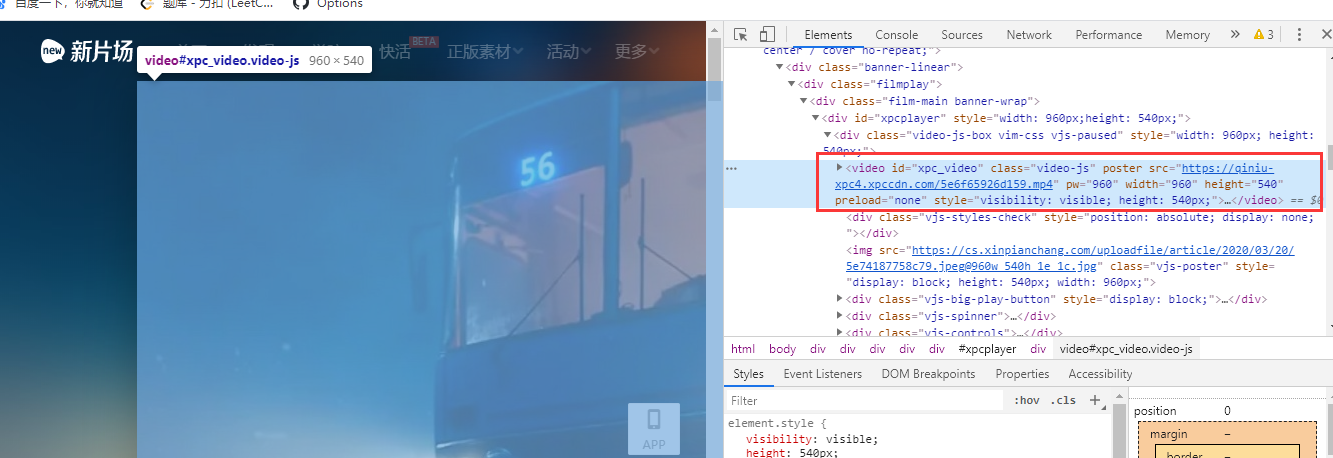
匹配地址://video[@id=“xpc_video”]/@src

写代码运行


我们发现所有的video都是None,那这个地址可能是js动态加载的
打开多个视频详情页,分析视频地址,我们发现地址请求源:

https://openapi-vtom.vmovier.com/v3/video/一串字符?expand=resource&usage=xpc_web
我们只需要找到这串字符串是从哪儿来的

找到对应的js


找到这串数字,我们发现它是直接写在html里,提取字符串
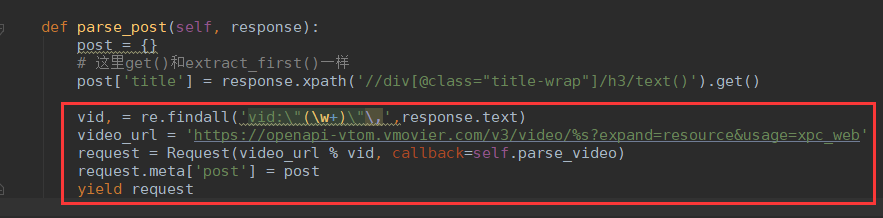
vid, = re.findall('vid:\"(\w+)\"\,',response.text)
video_url = 'https://openapi-vtom.vmovier.com/v3/video/%s?expand=resource&usage=xpc_web'
request = Request(video_url % vid, callback=self.parse_video)
request.meta['post'] = post
yield request
这个域名和首页域名不一样,我们把它加进去



def parse_video(self, response):
post = response.meta['post']
result = json.loads(response.text)
post['video'] = result['data']['resource']['default']['url']
yield post
所有代码
# -*- coding: utf-8 -*-
import json
import re
import scrapy
from scrapy import Request
class DiscoverySpider(scrapy.Spider):
name = 'discovery'
allowed_domains = ['xinpianchang.com', 'openapi-vtom.vmovier.com']
start_urls = ['https://www.xinpianchang.com/channel/index/sort-like?from=navigator']
def parse(self, response):
pid_list = response.xpath('//@data-articleid').extract()
url = "https://www.xinpianchang.com/a%s?from=ArticleList"
for pid in pid_list:
yield response.follow(url % pid, self.parse_post)
def parse_post(self, response):
post = {}
# 这里get()和extract_first()一样
post['title'] = response.xpath('//div[@class="title-wrap"]/h3/text()').get()
categorys = response.xpath('//span[contains(@class,"cate")]//text()').extract()
post['category'] = ''.join([category.strip() for category in categorys])
post['created_at'] = response.xpath('//span[contains(@class,"update-time")]/i//text()').get()
post['play_counts'] = response.xpath('//i[contains(@class,"play-counts")]/@data-curplaycounts').get()
vid, = re.findall('vid: \"(\w+)\",', response.text)
video_url = 'https://openapi-vtom.vmovier.com/v3/video/%s?expand=resource&usage=xpc_web'
request = Request(video_url % vid, callback=self.parse_video)
request.meta['post'] = post
yield request
def parse_video(self, response):
post = response.meta['post']
result = json.loads(response.text)
post['video'] = result['data']['resource']['default']['url']
yield post















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









