







FSRNet: End-to-End Learning Face Super-Resolution with Facial Priors 2018 CVPR

FSRNet:通过人脸先验实现 端到端学习人脸超分辨率
1.引言

主要思想:
本文主要提出了一种新颖的深度端到端可训练人脸超分辨率网络(FSRNet),该网络利用人脸地标热图和解析图等几何先验信息,在没有良好排列要求的情况下实现对非常低分辨率(LR)人脸图像的超分辨率,并且还提出了人脸超分辨率生成对抗网络(Face Super-Resolution Generative Adversarial Network, FSRGAN),将对抗损失引入FSRNet。此外,引入了两个相关的任务,人脸对齐和解析,作为人脸SR的新的评估指标,解决了经典指标与视觉感知不一致的问题。
本文贡献
•据我们所知,这是第一个以方便和优雅的端到端训练方式利用面部几何先验的深度人脸超分辨率网络。
•同时引入两种人脸几何先验:人脸地标热图和解析图。
•拟议的FSRNet通过放大8倍实现了对无序和极低分辨率(16× 16像素)人脸图像的幻觉,而扩展的FSRGAN进一步生成更真实的人脸。
•采用人脸对齐和解析作为人脸超分辨率的新评价指标,进一步解决了经典指标与视觉感知不一致的问题。
2、网络结构
2.1 概述FSRNet
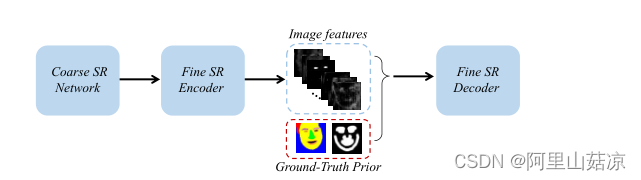
构建一个粗糙的SR网络来恢复一个粗糙的高分辨率(HR)图像。然后,将粗HR图像发送到精细SR编码器和先验信息估计网络两个分支,分别提取图像特征和估计地标热图/解析图。同时将图像特征和先验信息发送到一个良好的SR解码器,以恢复HR图像。
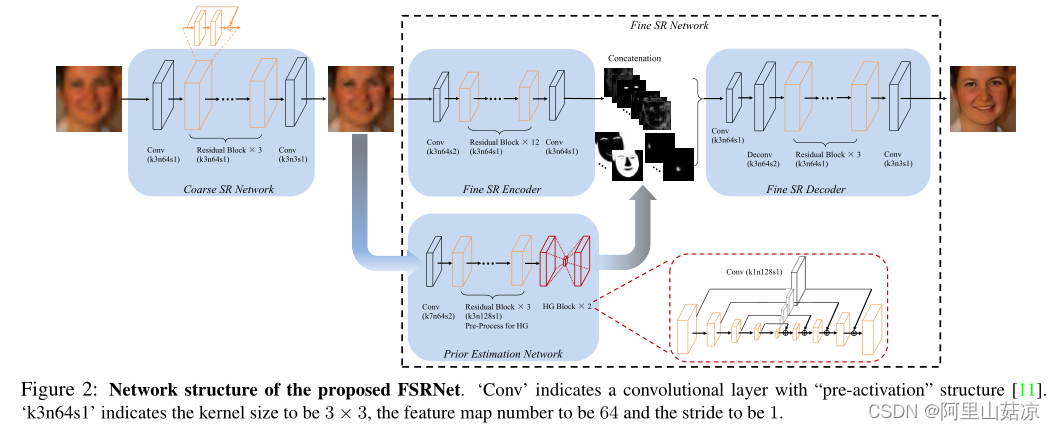
为了生成逼真的人脸,还提出了人脸超分辨率生成对抗网络(Face Super-Resolution Generative Adversarial Network, FSRGAN),将对抗损失引入FSRNet。此外,我们引入了两个相关的任务,人脸对齐和解析,作为人脸SR的新的评估指标,解决了经典指标与视觉感知不一致的问题。(适用于基于MSE和基于GAN的模型)
函数公式:

(1) C表示 粗SR网络 从LR图像x 映射 到粗SR图像 的yc ,然后将yc发送到先验估计网络P和精细SR编码器F
(2) f为F提取的特征 p为P的估计地标热图/解析图
(3) 编码后,利用SR解码器D将图像特征F与先验信息P拼接,恢复SR图像,
损失函数:损失函数就是(真实的高分辨图像-粗糙的恢复图像)+(真实的高分辨图像-精细的的恢复图像)+(真实的人脸先验分布-估算的人脸先验分布)

(1) ˜y(i)是LR图像x(i)的ground-truth HR图像,˜p(i)是相应的ground-truth先验信息
(2)FSRNet的损失函数为上式(4)
(3)Θ为参数集, α为粗SR损失权重 , β为先验损失的权重
y(i)为恢复后的HR图像 ,p(i)为第i幅图像的估计先验信息
2.2 详述FSRNet
基本FSRNet:一个粗SR网络和一个细SR网络,其中细SR网络包含三个部分:先验估计网络、细SR编码器和细SR解码器。
2.2.3 粗糙的SR网络(第一阶段)
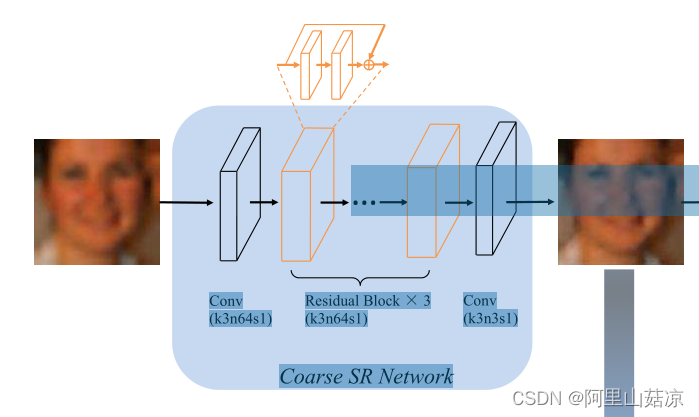
首先,我们使用粗糙的SR网络对粗糙的HR图像进行粗略的恢复。
动机:从LR输入图像直接估计面部地标位置和解析地图是比较困难的,使用粗糙的SR网络可以缓解先验估计的困难。
2.2.2精细的SR网络(第二阶段)
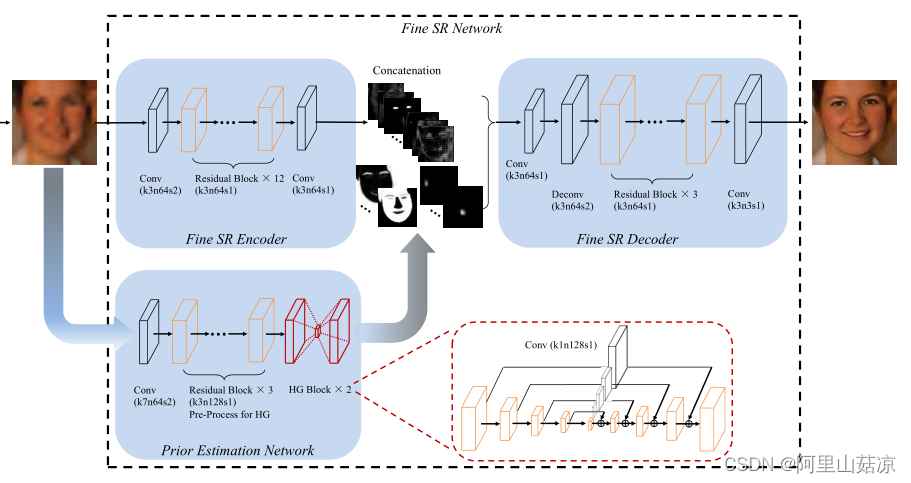
在精细SR网络中,将粗糙的HR图像发送给两个分支,即先验估计网络和精细的SR编码器中,分别用于估计人脸先验和提取特征,然后解码器联合使用这两个分支的结果来恢复精细的HR图像
(1)先验信息估计网络
本文采用HourGlass (HG)结构在我们的先验估计网络中估计面部地标热图和解析图。为了有效地整合跨尺度的特征,保存不同尺度的空间信息,沙漏块 HourGlass block 在对称层之间采用了跳跃连接 skip-connection 机制。生成地标热图和解析图
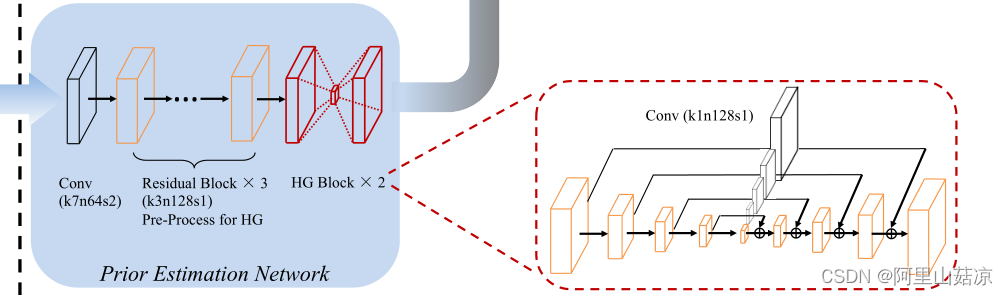
(2)精细的SR编码器
利用残差块 residual block 进行特征提取,考虑到计算成本,将先验特征的大小降采样到64 × 64。为了使特征大小一致,精细SR编码器从stride 2的3 × 3卷积层开始向下采样特征映射到64 × 64,再利用ResNet结构提取图像特征。
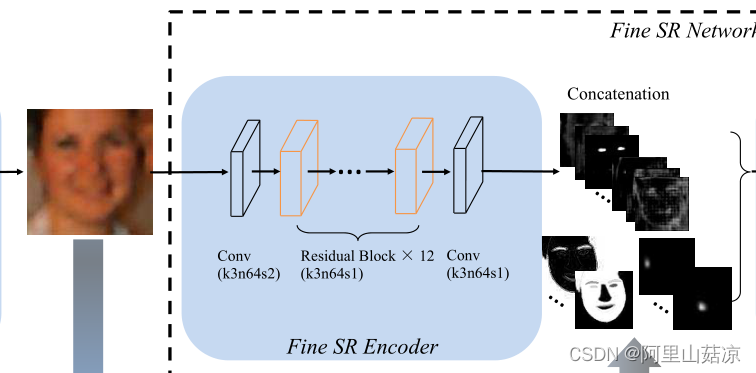
(3)精细的SR解码器
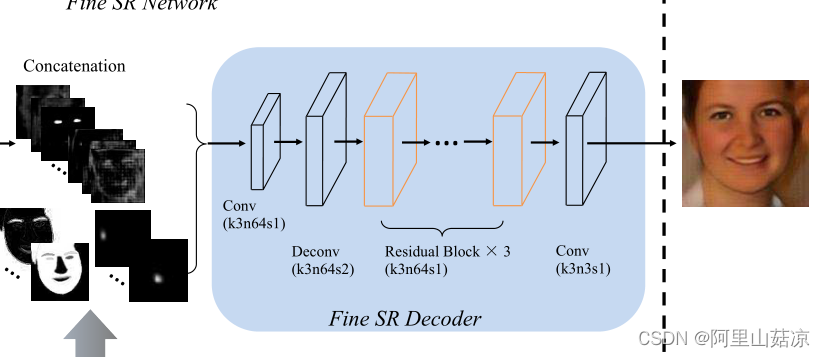
首先,将先验特征p和图像特征f串联起来作为解码器的输入。然后一个3 × 3的卷积层将特征映射的数量减少到64个。利用一个4 × 4的反卷积层对特征图进行上采样,使其尺寸达到128 × 128。然后用3个残差块对特征进行解码。最后,利用3 × 3的卷积层对HR图像进行恢复。
2.3 FSRGAN
核心思想: 利用判别网络 discriminative network 来区分超分辨率图像和真实的高分辨率图像,并训练SR网络欺骗判别器the SR network to deceive the discriminator 。
Structure of “upper-bound” model.

式(5):判别loss C输出输入的概率是实数E是概率分布的期望,除了对抗性损失LC,进一步引入了感知损失perceptual loss
式(6):感知loss φ表示固定的预训练的VGG模型,并映射图像y/˜y到特征空间
式(7):最终损失函数 γC和γP分别为GAN和知觉损失 perceptual loss的权重。
3、相关实验FSRNet: End-to-End Learning Face Super-Resolution with Facial Priors
3.1 人脸先验知识的影响
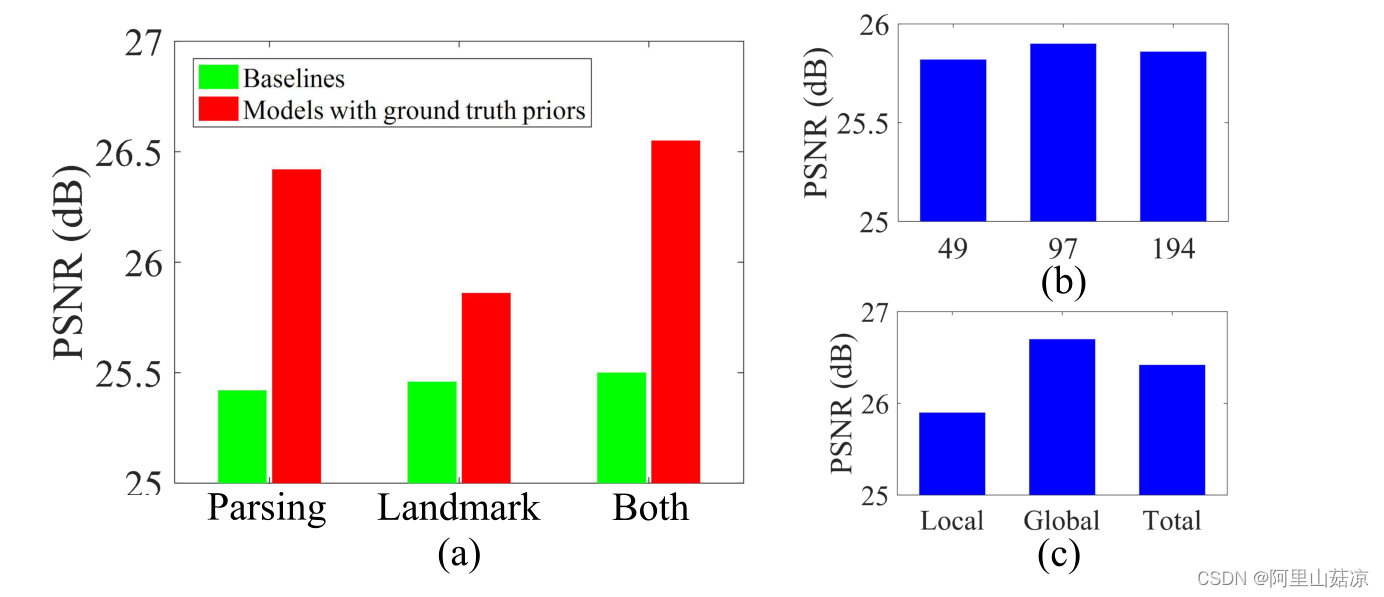
从图中可以看到用了先验信息的模型有提高,设定不同的landmark数,以及使用局部解析图或者全局解析图。得到的性能比较结果(上图右半部分)。
通过上面结果的比较,得出以下结论:
1.解析图比landmark heatmap含有更多人脸图像超分辨的信息,带来的提升更大。
2.全局的解析图比局部的解析图更有用
3.landmark数量增加所带来的提升很小
估计得到的先验信息的影响
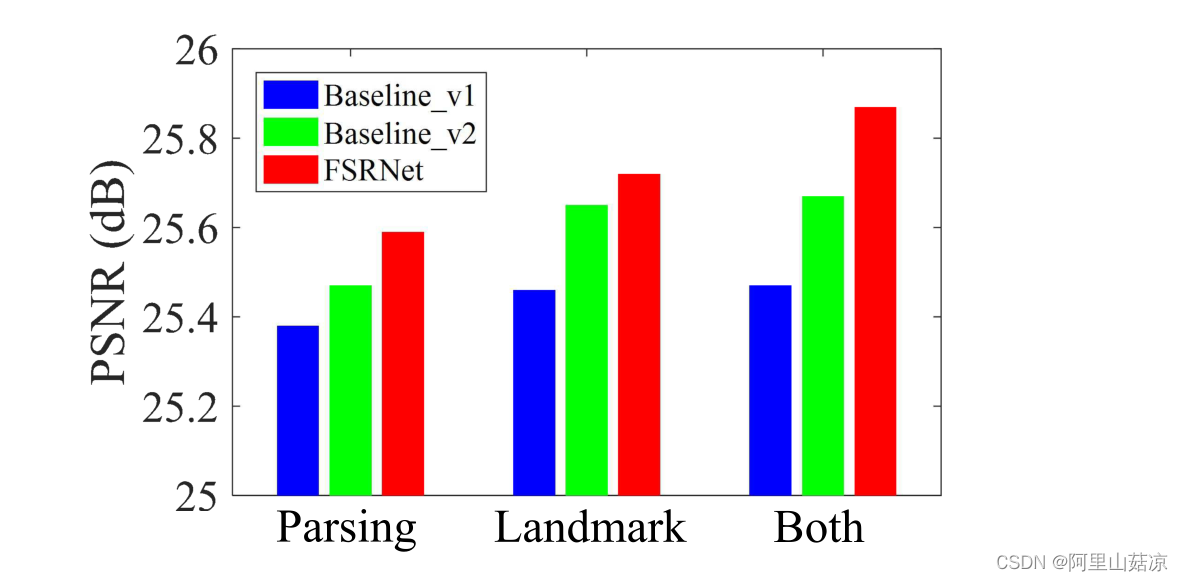
Baseline_v1:完全不包含先验信息
Baseline_v2:包含先验信息,但不进行监督训练
通过图中对比,得出以下结论:
1.即使不进行监督训练,先验信息也能帮助到SR任务,可能是因为先验信息提供了更多的高频信息。
2.越多先验信息,越好。
3.最佳性能为25.85dB,但是使用ground truth信息时,能达到26.55dB。说明估计得到的先验信息并不完美,更好的先验信息估计网络可能会得到更好的结果。
与其他方法的性能比较

定性比较。前两个例子是海伦,其他的 celebA

以PSNR/SSIMs为指标比较结果

对齐(NRMSE)/解析(IOU)的定量比较
















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











