







导语
这是某一个漫画平台,你猜到了吗?

![]()

![]()
呐呐呐~首先是找到自己想下载的动漫
如下这部动漫就这个!安排!!!

正文
环境安装(1):
Python版本:3.6.4
pillow模块;bs4模块;requests模块;
以及一些Python自带的模块。
选取榜单第一位为爬取目标(2):

![]()
获取漫画基本信息 :
def GetBasicInfo(url):
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'lxml')
tmp = soup.find(attrs={'class': 'mhlistbody'})
chapters = tmp.ul.contents
chapters.reverse()
return chapters漫画的真实下载地址解码方式如下:
def GetRealUrls(mh_info):
imgs = []
comic_size = re.findall(r'comic_size:"(.*?)"', mh_info)[0]
base_url = 'https://mhpic.jumanhua.com/comic/{}.jpg%s.webp' % comic_size
num_img = int(re.findall(r'totalimg:(\d+)', mh_info)[0])
pageid = int(re.findall(r'pageid:(\d+)', mh_info)[0])
imgpath = re.findall(r'imgpath:"(.*?)"', mh_info)[0]
start = 0
while True:
idx = imgpath.find('\\', start)
if idx == -1:
break
imgpath = imgpath[:idx] + imgpath[idx+1:]
start = idx + 1
for i in range(num_img):
realpath = str()
for s in imgpath:
realpath += chr(ord(s) - pageid % 10)
url = base_url.format(realpath + str(i+1))
imgs.append([url, str(i+1)+'.jpg'])
return imgs 然后直接下载完成:
下载某一章漫画
'''
def DownloadChapter(savepath, url):
if not os.path.exists(savepath):
os.mkdir(savepath)
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
mh_info = re.findall(r'mh_info={(.*?)}', res.text)[0]
img_urls = GetRealUrls(mh_info)
for img_url in img_urls:
img_content = requests.get(img_url[0]).content
filename = os.path.join(savepath, img_url[1])
img = Image.open(io.BytesIO(img_content))
img.save(filename) 修改url获取你想获得的页面:
if __name__ == '__main__':
# url = 'http://www.manhuatai.com/doupocangqiong/'
url = 'http://www.manhuatai.com/wudongqiankun/'
savepath = url.split('/')[-2]
Spider(url, savepath)效果如下👑👑👑👑👑👑:
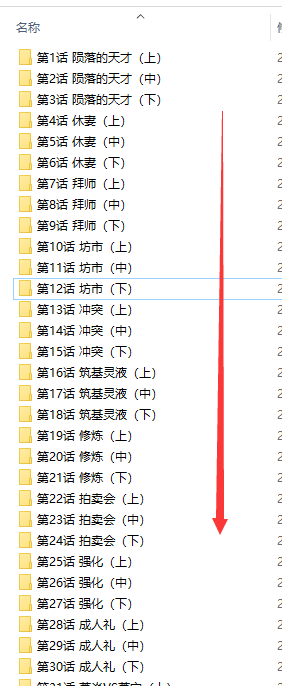
![]()
![]()
几百章节下载下来都没问题!好啦!

 总结
总结
喜欢(❤ ω ❤)看漫画的小伙伴儿不要错过这些精彩画面呀~
赶快拿到源码自己试试一次性批量下载这么多漫画叭!冲冲冲~
🎊🎊源码基地:关注小编获取哦~💝记得三连吖
ps:还有整本漫画福利免费送哦~

![]()
















 3612
3612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











