






数字化这两年在国内企业开展地如火如荼,各类数字化系统竞相部署上线,但每个系统背后都需要花费大量的成本,包括人力、时间、经济等。我发现在实际业务活动中,伴随着竞争日趋激烈的商业环境,企业大多希望能在最短的时间内构建解决方案以尽早满足业务需求,不过现在通常一个数字化项目投入较大、耗时较长,另外也会有一些阶段性的需求,比如新冠疫情带来的封城政策对供应链的影响,当疫情结束后,这类影响也随之结束,如果当时企业已为此投入建设数字化项目,可能后期投资回报率将大为降低,因此综合上述因素考虑,目前企业在数字化建设过程中以第三方参与开发大型应用为主,辅以一些通过技术工具(如Power BI, Python, RPA等)自主开发的轻量级数字化应用。
我大学毕业后至今已从业20年,期间做过市场分析员、数据分析工程师、商业分析经理、数字化经理等多个与系统和数据打交道的岗位,涉及多个行业的不同业务部门,主要是在供应链管理领域。我在业余时间会钻研程序编写、数据库、可视化等IT技术,并结合实际业务场景为企业开发了多款小型轻量化应用工具,从在第一家公司采用VBA开发客户贡献度系统,到最近应用ChatGPT辅助编程开发供应商返利跟踪管理平台,这些轻量级的应用在时间、经济等约束条件下较好地满足了企业的业务需求。当然,这20年来技术也在不断发展,我也在不断学习新的技术,从Excel,Power BI到Python,再到最近火热的人工智能(如ChatGPT,文心一言等),能将自己的兴趣与工作相结合我也感到十分幸运。后面我会不定期分享一些案例给到大家,希望能给大家带来启发和借鉴,同时也欢迎大家留言交流。
第一期案例的主题是Power BI绘制供应链路线图,我将分上下两篇给大家介绍。
这两年随着企业对供应链风险管理的愈加关注,企业往往需要快速准确地获知风险所涉及到的上下游供应商与客户,以此能快速评估某一个风险要素对于供应链的影响范围与程度大小。
当时公司刚成立风险管理团队,管理方法和工具都在摸索阶段,作为部门数字化负责人,也一直在思考风险管理工具该何从下手。直到我在2023年看到一份第三方咨询机构发布的有关供应链风险管理的报告中提到供应链路线图这个概念的时候,给了我启发与灵感,我发现供应链路线图是一个十分有效的风险管理工具,当时从成本和业务匹配度角度考量,决定自主开发一款轻量级应用,接下来我要思考的就是用什么软件工具来绘制供应链路线图。
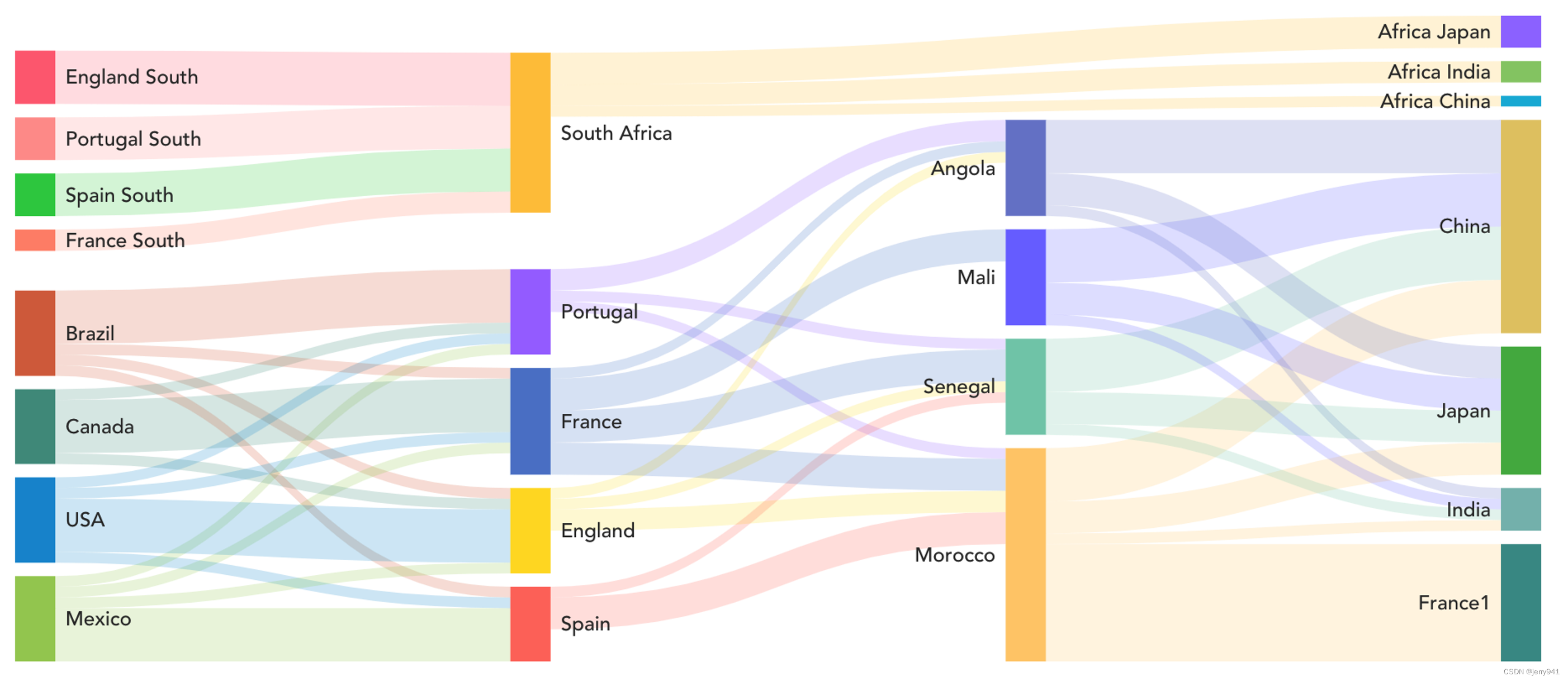
既然是路线图,那就属于可视化的范畴,当时公司在推广Power BI这款可视化工具,所以就决定采用Power BI来开发,平时我也会从书籍、网络、工作分享等渠道留意好的Power BI作品,看看能不能给到我一些灵感。那天我在浏览一个网络上发布的帖子,讲的是关于人口流动的案例,采用桑基图来绘制,如图0所示,这和供应链中从原料、零件、半成品、成品一路流动的情况十分相似,这不就是我想要的效果么?于是我就在Power BI中安装了绘制桑基图的控件并通过学习相关案例了解如何设置并构建报表。
图0
要绘制供应链路线图需要有各级供应商和客户的信息,以及供应链上每个节点与其上下游节点之间的关系数据或者说权重数据,对于数据的数量和质量有一定的要求,要求越高,绘制出来的供应链路线图越准确、越有商业价值。具体我是如何采用Power BI工具来一步一步构建应用的,接下来让我给大家作详细介绍。
我把如何使用桑基图绘制供应链路线图的思路整理总结为以下5个步骤:
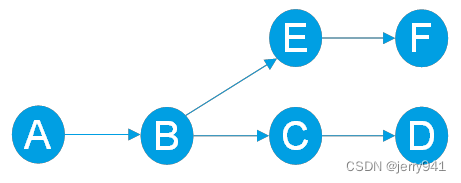
第一步:为更好地理解供应链路线图,我们先画一张供应链路线简图(图1),下图显示从节点A出发,A供货至B,B分别供货至C和E,C供货至D,E供货至F,我们将在这张简图的基础上展开讨论。
图1
第二步:建立桑基图所需数据模型
桑基图数据模型其实很简单,只要构建一个包含起点(source),终点(destination)和权重(weight)数据的数据表,我们以上述供应链路线简图中A到B这条链路为例,起点(Source)为A,终点(Destination)为B,权重(Weight)为2,这里的权重在实际业务中可以理解为运输量(Delivery Volume)、采购量(Purchase Volumn)、采购额(Purchase Turnover)等,我们将其他链路按此方法解析后,可以获得如下数据表(表1):
表1
| 起点 | 终点 | 权重 |
| A | B | 2 |
| B | C | 1 |
| C | D | 1 |
| B | E | 1 |
| E | F | 1 |
第三步:构建适合实际业务的数据模型
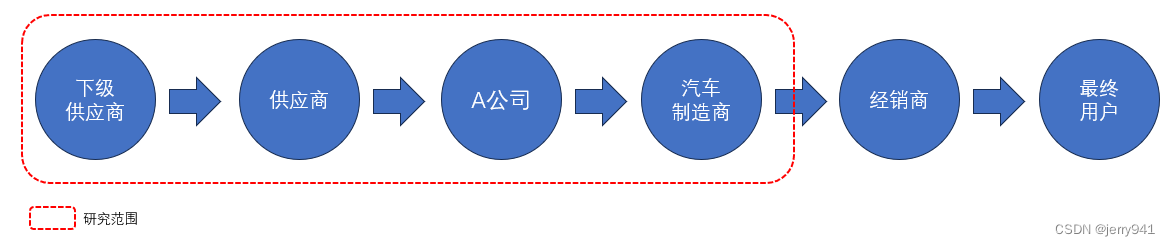
回到实际业务,我目前服务的公司(下文简称A公司)主要生产汽车零部件,客户是各大汽车制造商(主机厂),公司供应链的上游节点有供应商、供应商的供应商、…,供应链的下游节点有汽车制造商、经销商、最终用户(如图2所示)。
图2
整个供应链涉及节点众多,如果每个节点都要做风险监测,势必要投入大量的资源,因此在实际业务活动中,作为采购部门,我们将供应链上游三级以内供应商作为我们风险监测的主要对象,我们先建立一个包含A公司和三级以内供应商的最简单的数据模型(表2):
表2
| 起点 | 终点 | 权重 |
| 三级供应商 | 二级供应商 | 1 |
| 二级供应商 | 一级供应商 | 1 |
| 一级供应商 | A公司 | 1 |
| A公司 | 汽车制造商 | 1 |
实际情况下,链路要复杂许多,比如一家三级供应商给多家二级供应商供货,一家一级供应商从多家二级供应商采购货物,甚至有些供应商既是一级供应商也是二级供应商,等等。
第四步:准备模型所需要的数据
从表2的链路数据模型可以了解到,我们需要能够反映三级以内供应商、A公司和汽车制造商之间关系和关联程度(即权重)的数据,当时我们基于手头已有的数据构建了一级供应商->A公司->汽车制造商的链路数据表,主要用到销售订单/预测、采购零件价格和物料清单等数据表,数据表简单介绍如下:
(1)销售订单/销售预测表(表3)
表3
| 客户 | 产品号 | 月订货量/月预测量 | … |
| 客户001 | 123456-A | 100 | … |
| 客户001 | 123456-B | 120 | … |
| 客户002 | 123456-A | 70 | … |
| … | … | … | … |
(2)物料清单BOM(表4)
表4
| 产品号 | 采购零件号 | 单位产品用量 | 供应商 | … |
| 123456-A | Part1 | 1 | 供应商001 | … |
| 123456-A | Part2 | 2 | 供应商002 | … |
| 123456-A | Part3 | 5 | 供应商003 | … |
| 123456-B | Part1 | 1 | 供应商001 | … |
| 123456-B | Part4 | 2 | 供应商004 | … |
| … | … | … | … | … |
(3)采购零件价格清单(表5)
表5
| 采购零件号 | 采购公司 | 供应商 | 采购单价 | 币种 | … |
| Part1 | A公司 | 供应商001 | 1 | CNY | … |
| Part2 | A公司 | 供应商002 | 1 | CNY | … |
| Part3 | A公司 | 供应商003 | 1 | CNY | … |
| Part4 | A公司 | 供应商004 | 1 | CNY | … |
| … | … | … | … | … | … |
(4)客户需求与供应商采购对接表(表6)
我通过VBA编程,将表3、表4和表5基于关键字段“产品号”与“采购零件号”对接并选取所需字段后生成表6,大家也可以采用所擅长的工具(如SQL, Python等)高效生成该表。
表6
| 客户 | 产品号 | 月订货量/月预测量 | 生产(采购)公司 | 采购零件号 | 单位用量 | 供应商 | 月采购量 (月订货量/月预测量*单位用量) | 采购单价 | 采购额(月采购量*采购单价) |
| 客户001 | 123456-A | 100 | A公司 | Part1 | 1 | 供应商001 | 100 | 1 | 100 |
| 客户001 | 123456-A | 100 | A公司 | Part2 | 2 | 供应商002 | 200 | 1 | 200 |
| 客户001 | 123456-A | 100 | A公司 | Part3 | 5 | 供应商003 | 500 | 1 | 500 |
| 客户001 | 123456-B | 120 | A公司 | Part1 | 1 | 供应商001 | 120 | 1 | 120 |
| 客户001 | 123456-B | 120 | A公司 | Part4 | 2 | 供应商004 | 240 | 1 | 240 |
| 客户002 | 123456-A | 70 | A公司 | Part1 | 1 | 供应商001 | 70 | 1 | 70 |
| 客户002 | 123456-A | 70 | A公司 | Part2 | 2 | 供应商002 | 140 | 1 | 140 |
| 客户002 | 123456-A | 70 | A公司 | Part3 | 5 | 供应商003 | 350 | 1 | 350 |
第五步:构建链路数据表
基础数据准备工作已完成,接下来我们将基于表6数据构建满足链路模型要求的链路数据表。链路数据要求一条记录代表一条链路,如果直接将表6作为链路数据表,则可能会出现一条链路上存在多条记录,如A公司采购供应商001零件Part1用于生产客户A和客户B所订购的123456-A产品,这时供应商001至A公司的链路为一条,但表6有两条记录,这样桑基图就无法体现关联累计程度(权重)的大小,所以我们需要先将记录作组内合并求和,这里主要有两类链路,一类是供应商为起点,A公司为终点,这时将采购额按照“供应商+A公司”为组求和,另一类是以A公司为起点,客户为终点,考虑到监测对象为供应商,“A公司+客户”为组求和将无法识别各供应商对客户的贡献程度),这时需要按照“供应商+A公司+客户”为组求和;因为监测(查询)对象为供应商,所以在链路数据表中增加一列数据用于存放供应商信息,通过该列数据筛选出需要监测(查询)的供应商。构建完成后的链路数据表(表7)如下所示,A公司与4家供应商、2家客户合计有11条供应链路:供应商至A公司有4条链路,各供应商经A公司至客户有7条链路。
表7(供应商下游链路数据表)
| 监测供应商 | 起点 | 终点 | 权重 |
| 供应商001 | 供应商001 | A公司 | 290 |
| 供应商002 | 供应商002 | A公司 | 340 |
| 供应商003 | 供应商003 | A公司 | 850 |
| 供应商004 | 供应商004 | A公司 | 240 |
| 供应商001 | A公司 | 客户001 | 220 |
| 供应商001 | A公司 | 客户002 | 70 |
| 供应商002 | A公司 | 客户001 | 200 |
| 供应商002 | A公司 | 客户002 | 140 |
| 供应商003 | A公司 | 客户001 | 500 |
| 供应商003 | A公司 | 客户002 | 350 |
| 供应商004 | A公司 | 客户001 | 240 |
为什么采用采购额作为权重?因为采购额没有采购量、销售量存在的单位不一致的问题,容易统计,另外通常来说采购占销售约60%,所以采购比重可以近似看作销售比重即客户比重,这样我们就能通过可视化方便了解某供应商所对应的各家客户的大致比重,在风险管理和决策过程中快速抓住重点客户。
到这里,供应商下游链路数据表已基本完成,不过接下来才是链路数据表的硬核部分,也就是构建供应商上游链路数据表。
在实际业务中,我们通常将一级供应商称为供应商,二级供应商、三级供应商等则统称为子供应商,供应商与A公司直接交易,因此数据比较齐全,而子供应商参与间接交易,A公司一般需要与供应商一起协作收集。当时在做这个项目的时候,恰好集团总部在准备筹建子供应商数据库,要求每个区域收集子供应商基本数据,老板就委派我成立一个项目小组并带领大家开展收集工作,当时我们设计的收集模板,其中主要字段如下所示(表8):
表8
| A公司供应商名称 | 子供应商属性 | 子供应商层级 | 子供应商交付品类 | 子供应商名称 | 子供应商地址 |
这里对部分字段作简要说明:属性分为生产和贸易两大类;子供应商层级分为1级、2级等,设A公司供应商为0级,则该供应商的供应商则为1级子供应商,1级子供应商的供应商则为2级子供应商,…依此类推,应实际业务需要,我们将收集的范围定义在3级子供应商以内;定义交付品类时,我们基于历史数据总结,主要分为加工处理(如热处理、电镀、涂层等)和原材料/子零件两大类。
顺带提一下表8模板设计的问题,我们当时在设计模板的时候考虑过多种形式,主要有横向展开和纵向展开两种,横向展开是设置每个层级供应商所需的字段,字段比较多,缺点是当子供应商层级涉及不多时,很多字段会留空,优点是层次清晰便于理解;纵向展开是只设置一组供应商所需的字段,维护时需要针对同一条链路按照层级顺序(上游至下游或下游至上游)维护,否则绘制出的链路将无法准确反映实际情况,优点是无论供应商层级数量多少,均不会有字段留空的问题。我们根据实际情况综合评估后,最终选择纵向展开形式的模板。每个企业的业务特点各不相同,所以大家可以根据自己企业的实际情况来设计合适的模板。
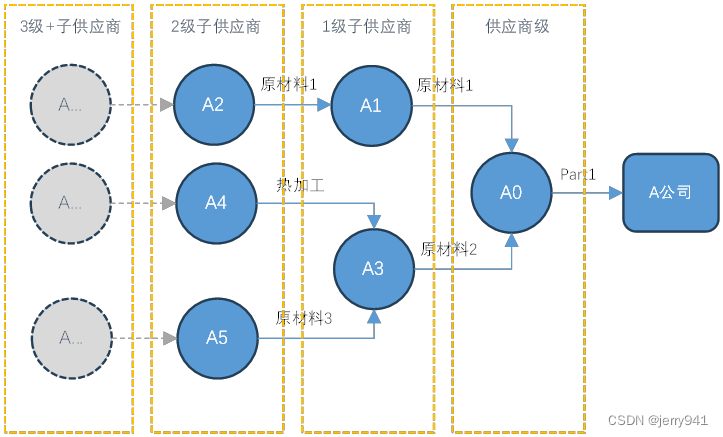
接下来,我们将以供应商001作为范例来介绍如何按步骤准备供应商上游链路数据表,首先通过A公司上游供应链树形结构图(图3)和供应链路线图(图4)帮助大家理解各供应商之间的层次关系:
图3

图4
当时我们要求采购业务人员按照以下逻辑将各供应商的层级关系维护至子供应商数据表(表9)中:
以供应商作为起点(起点即A0无需记录),从下游节点往上游节点依次记录,一条分支从分支点开始记录直至该分支末端节点或该分支中的下一个分支点,以图4为例,步骤如下:
(1)A0上游有两条分支,依次记录第一条分支上游的A1和A2两个节点,A2为收集范围内的分支末端节点,该分支记录完毕(表9记录1和2);
(2)A0第二条分支上游的第一个节点为A3,且A3是下一个分支点,记录A3(表9记录3);
(3)A3上游有两条分支,第一条分支上游的第一个节点为A4,且A4为收集范围内的分支末端节点,该分支记录完毕(表9记录4);
(4)A3第二条分支上游的第二个节点为A5,且A5为收集范围内的分支末端节点,该分支记录完毕(表9记录5);
(5)循环第1步至第4步,直至所有子供应商节点记录全部完成。
表9(子供应商数据表)
| 记录号 | 节点 | A公司供应商 | 子供应商属性 | 子供应商层级 | 子供应商交付品类 | 子供应商 | 子供应商地址 |
| 记录1 | A1 | 供应商001 | 贸易 | 1级 | 原材料1 | 1级子供应商001 | Add1 |
| 记录2 | A2 | 供应商001 | 生产 | 2级 | 原材料1 | 2级子供应商001 | Add2 |
| 记录3 | A3 | 供应商001 | 生产 | 1级 | 原材料2 | 1级子供应商002 | Add3 |
| 记录4 | A4 | 供应商001 | 生产 | 2级 | 热加工 | 2级子供应商002 | Add4 |
| 记录5 | A5 | 供应商001 | 贸易 | 2级 | 原材料3 | 2级子供应商003 | Add5 |
| ... | … | … | … | … | … | … | … |
接着我们来分析图4中从供应商到各级子供应商的每段链路,由于子供应商的采购和销售信息涉及商业机密,较难获得,经团队综合评估后,我们将子供应商链路表中的权重统一设置为1,子供应商的关系信息可以满足大部分业务需求,权重数据缺失的影响有限。所以我们只要通过表9将各链路的起点和终点定义出来即可,步骤如下:
(1)找到表9中供应商001对应的第一个1级子供应商(即A1),定义链路:A1为起点,供应商001为终点;
(2)查看下一条记录,为供应商001对应的一家2级子供应商(即A2),说明A2为A1的供应商,定义链路:A2为起点,A1为终点;如果该条记录的供应商不是供应商001,则结束步骤并循环进入下一个供应商(若有)或全部结束;如果该条记录为供应商001对应的一家1级子供应商,定义链路逻辑与步骤1相同,完成后继续步骤2;
(3)样例中供应商001的子供应商最多至2级,实际情况层级可能有3级甚至更多,与处理2级子供应商类似,如果是3级,则3级为起点,2级为终点;如果是2级,则跳转到步骤2;如果是1级,则跳转到步骤1…如图5所示,直至同一供应商记录全部遍历完毕,并完成链路数据表中起点终点信息的维护。
图5
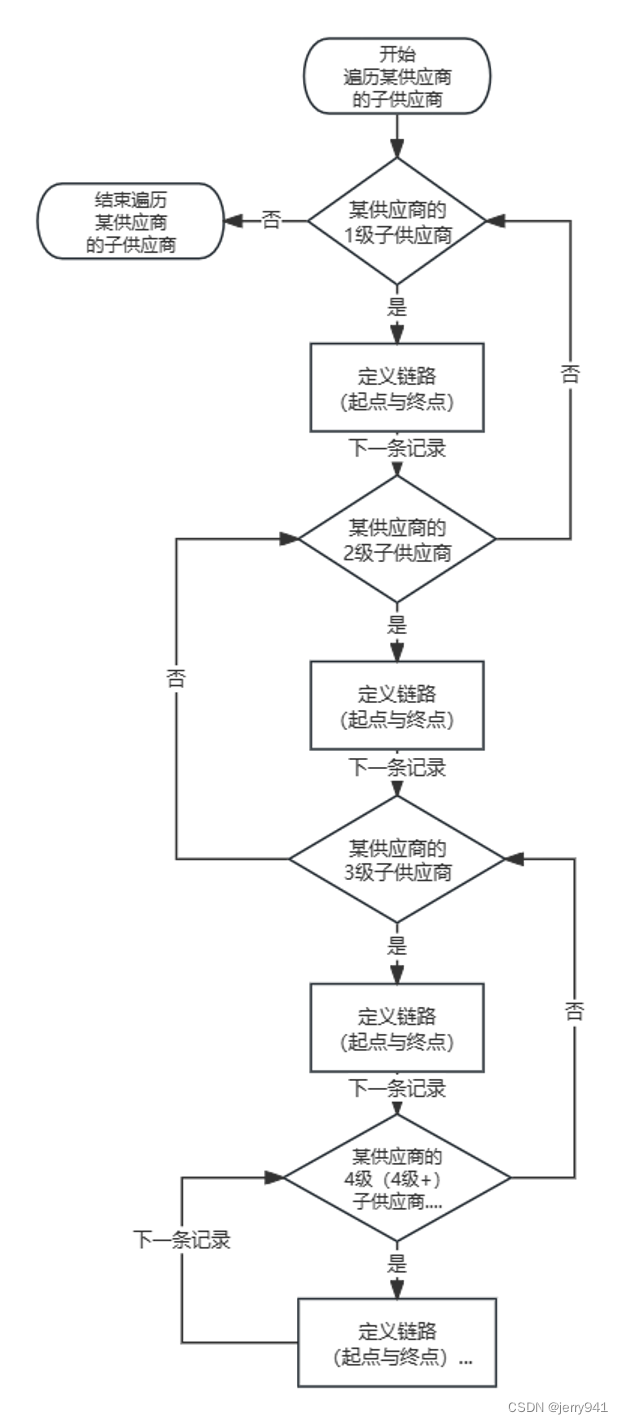
表9根据上述步骤生成供应商上游链路数据表(表10),为了文章表述方便简洁,后续采用节点编码来代表各层级子供应商,但在实际数据库记录中仍以子供应商具体名称表示,这点请大家注意。
表10(供应商上游链路数据表)
| 监测供应商 | 起点 | 终点 | 权重 |
| 供应商001 | A1 | 供应商001 | 1 |
| 供应商001 | A2 | A1 | 1 |
| 供应商001 | A3 | 供应商001 | 1 |
| 供应商001 | A4 | A3 | 1 |
| 供应商001 | A5 | A3 | 1 |
| … | … | … | … |
当时我用VBA写了一段程序实现上了上述步骤,极大提升了工作效率,当然如果你擅长Python、SQL等其他工具,也可以实现上述步骤。
现在我们已经有了供应商上游链路数据表(表7)和下游链路数据表(表10),将两张表格合并后,如下(表11)所示:
表11(供应商上下游链路数据表)
| 监测供应商 | 起点 | 终点 | 权重 |
| 供应商001 | 供应商001 | A公司 | 290 |
| 供应商002 | 供应商002 | A公司 | 340 |
| 供应商003 | 供应商003 | A公司 | 850 |
| 供应商004 | 供应商004 | A公司 | 240 |
| 供应商001 | A公司 | 客户001 | 220 |
| 供应商001 | A公司 | 客户002 | 70 |
| 供应商002 | A公司 | 客户001 | 200 |
| 供应商002 | A公司 | 客户002 | 140 |
| 供应商003 | A公司 | 客户001 | 500 |
| 供应商003 | A公司 | 客户002 | 350 |
| 供应商004 | A公司 | 客户001 | 240 |
| 供应商001 | A1 | 供应商001 | 1 |
| 供应商001 | A2 | A1 | 1 |
| 供应商001 | A3 | 供应商001 | 1 |
| 供应商001 | A4 | A3 | 1 |
| 供应商001 | A5 | A3 | 1 |
| … | … | … | … |
到这里,链路数据表整体上算基本完成,我们设置完成桑基图的数据源后(具体设置参看附录1),效果如图6和图7所示(以供应商001为例,数据在表11高亮显示):
图6
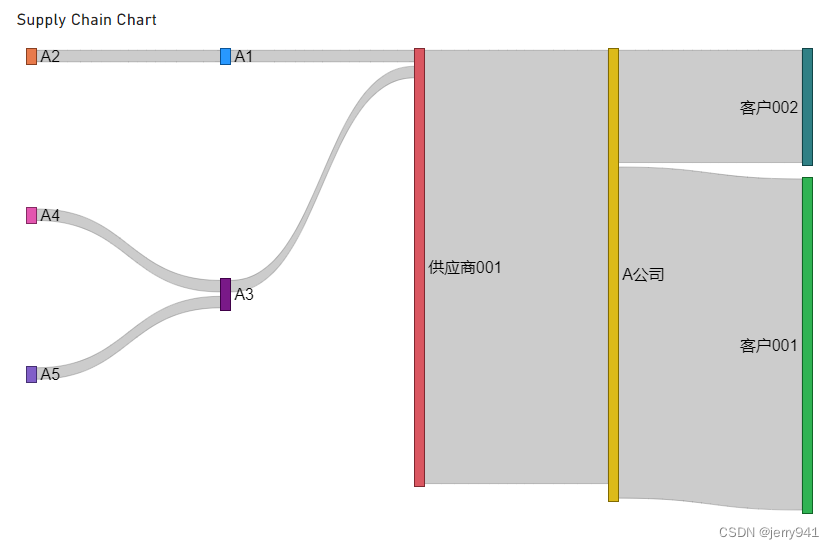
图7
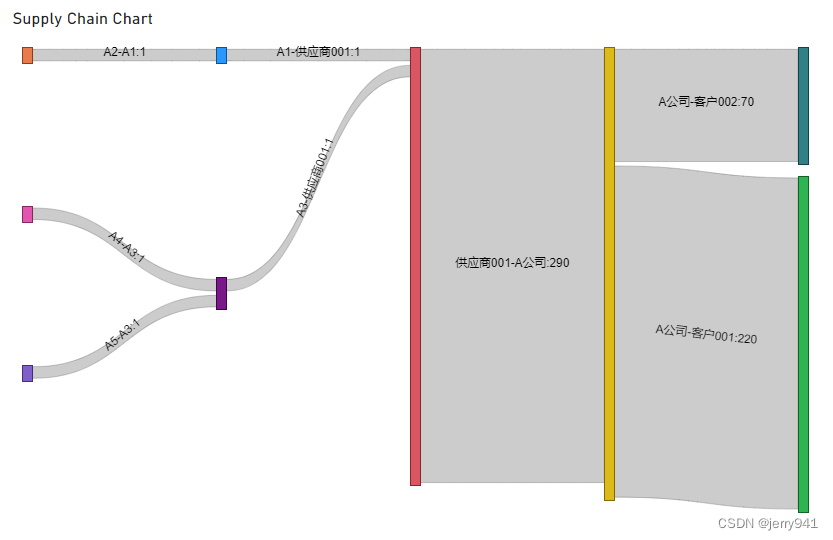
图6帮助我们清楚地看到与供应商001相关的供应链路线图,图7则通过流入线条的粗细展示了供应链上两个节点之间传递量的大小(即权重):A公司从供应商001中采购290CNY原材料中有220CNY的原材料流入客户001,70CNY的原材料流入客户002,通过可视化方便用户了解客户的大致比重,比如供应商001出现风险迹象,则可以快速评估对各个客户的影响程度。
前面介绍的是将供应商作为我们的监测(查询)对象来分析和准备链路数据,但实际业务中经常遇到某子供应商发生供应风险,需要查看涉及哪些供应商、客户,所以创建以子供应商为监测(查询)对象的链路数据表成为下一个要解决的问题。
我的思路是在供应商上下游链路数据表的基础上进行一定的处理,生成所需要的子供应商链路数据表,以A1为例,步骤如下:
(1)从表11的“起点”列找到A1,该记录对应的监测供应商为供应商001,在子供应商上下游链路数据表中新建一条记录,其中“监测子供应商”列为A1,复制“起点”、“终点”和“权重”三列数据至新建记录的对应列中(即表12记录1);
(2)接下来往A1的上游查找,查找表11中满足“终点为A1且监测供应商为供应商001”条件的记录,若查询结果不为空,在子供应商上下游链路数据表中新建一条记录,其中“监测子供应商”列为A1,复制查询结果第一条记录的“起点”、“终点”和“权重”三列数据至新建记录的对应列中,继续嵌套查找满足“终点为前一条查询结果的起点且监测供应商为供应商001”条件的记录,若查询结果不为空,在子供应商上下游链路数据表中新建一条记录,其中“监测子供应商”列为A1,复制查询结果第一条记录的“起点”、“终点”和“权重”三列数据至新建记录的对应列中,继续嵌套查找,直至无满足条件的记录,则返回至嵌套上一层,若上一层查询结果大于1条,则参照该步骤前述方式逐条处理;对于A1来说,上游记录共有1条(即表12记录2);
(3)接下来往A1的下游查找,A1至供应商001的下游链路已创建完成,所以从查找满足“起点和监测供应商均为供应商001”条件的记录开始,若查询结果不为空,在子供应商上下游链路数据表中新建记录,其中“监测子供应商”列为A1,复制查询结果第一条记录的“起点”、“终点”和“权重”三列数据至新建记录的对应列中,继续嵌套查找满足“起点为前一条查询结果的终点且监测供应商为供应商001”条件的记录,若查询结果不为空,在子供应商上下游链路数据表中新建一条记录,其中“监测子供应商”列为A1,复制查询结果第一条查询记录的“起点”、“终点”和“权重”三列数据至新建记录的对应列中,继续嵌套查找,直至无满足条件的记录,则返回至嵌套上一层,若上一层查询结果大于1条,则参照该步骤前述方式逐条处理;对于A1来说,下游记录共有3条(即表12记录3至5);
(4)完成A1的上游和下游记录即链路数据的创建。
表12
| 记录号 | 监测子供应商 | 起点 | 终点 | 权重 |
| 记录1 | A1 | A1 | 供应商001 | 1 |
| 记录2 | A1 | A2 | A1 | 1 |
| 记录3 | A1 | 供应商001 | A公司 | 290 |
| 记录4 | A1 | A公司 | 客户001 | 220 |
| 记录5 | A1 | A公司 | 客户002 | 70 |
遍历子供应商数据表(表9)中的子供应商,循环执行上述4个步骤,直至表9遍历完毕,生成子供应商上下游链路数据表(表13)。
表13(子供应商上下游链路数据表)
| 监测子供应商 | 起点 | 终点 | 权重 |
| A1 | A1 | 供应商001 | 1 |
| A1 | A2 | A1 | 1 |
| A1 | 供应商001 | A公司 | 290 |
| A1 | A公司 | 客户001 | 220 |
| A1 | A公司 | 客户002 | 70 |
| A2 | A2 | A1 | 1 |
| A2 | A1 | 供应商001 | 1 |
| A2 | 供应商001 | A公司 | 290 |
| A2 | A公司 | 客户001 | 220 |
| A2 | A公司 | 客户002 | 70 |
| A3 | A3 | 供应商001 | 1 |
| A3 | A4 | A3 | 1 |
| A3 | A5 | A3 | 1 |
| A3 | 供应商001 | A公司 | 290 |
| A3 | A公司 | 客户001 | 220 |
| A3 | A公司 | 客户002 | 70 |
| A4 | A4 | A3 | 1 |
| A4 | A3 | 供应商001 | 1 |
| A4 | 供应商001 | A公司 | 290 |
| A4 | A公司 | 客户001 | 220 |
| A4 | A公司 | 客户002 | 70 |
| A5 | A5 | A3 | 1 |
| A5 | A3 | 供应商001 | 1 |
| A5 | 供应商001 | A公司 | 290 |
| A5 | A公司 | 客户001 | 220 |
| A5 | A公司 | 客户002 | 70 |
将表11与表13合并后生成链路数据总表,并作为桑基图的数据源(具体设置参看附录1)。至此,项目的主要工作完成大半,接下来的任务是如何进行界面设计来提升用户体验,我将在下篇给大家分享一些总结的经验。

















 9222
9222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









