






1.try/except 的使用,判断异常情况
try:
****
except 异常:
****
常见异常:syntaxerror 语法错误 systemerror 编译器系统错误
systemexit 编译器进程被关闭
NoSuchElementException 定位元素在页面上不存在
//详细可见csdn收藏夹(python try语句相关使用(try/except/else/finally))
try:
a=b
print(a)
except SyntaxError:
print("<<<<syntaxerror")
except NameError:
print("<<<<nameerror")
print("so difficult!")2.输出台无法输出情况,但可以在终端运行 python youfile.py 运行
可以考虑安装扩展code runnner
3.webdriverwait 等待时间用法
开头调用:from selenium.webdriver.support import expected_conditions as EC
用于判断当前页面是否有你所需要的元素
title_is: 等待页面标题与给定的字符串完全匹配。title_contains: 等待页面标题包含给定的字符串。presence_of_element_located: 等待页面上出现一个元素,可以使用By定位到它。element_to_be_clickable: 等待一个元素变得可点击(通常是可见的并且enabled)。visibility_of_element_located: 等待一个元素在页面上可见(不一定要可点击)。visibility_of: 等待一个特定的元素变得可见。text_to_be_present_in_element: 等待某个元素的文本包含特定的字符串。text_to_be_present_in_element_value: 等待某个表单元素的值包含特定的字符串。frame_to_be_available_and_switch_to_it: 等待一个iframe变得可用,自动切换到它。invisibility_of_element_located: 等待一个元素变得不可见。element_to_be_selected: 等待一个HTML选项变得被选中。element_located_to_be_selected: 等待一个元素(如单选按钮或复选框)被选中。alert_is_present: 等待一个警告框出现。
webdriverwait.until显式等待使用方法
webdrriverwait(driver,timeout,poll-frequency=每隔几秒执行until中的方法)
from selenium import webdriver
from selenium.webdrivwer.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
br = webdriver.Chrome()
wait = webDriverWait(br,10)
br.get("https://kimi.moonshot.cn/")
title_element = wait.until(EC.presence_of_element_located((By.TAG_NAME,"title")))
#等待直到网页中<titile>元素出现,即浏览器加载了页面的标题部分
4.读取本地excel文件中的内容
import pandas as pd
excel_file = r'D:\桌面\zyj\universities.xlsx'
df = pd.read_excel(excel_file)
print(df.head()) #输出前几行5.如何定位到页面唯一标识
使用F12后快捷键ctrl+F,搜索这个biaoshi(id或其他)是否在前端代码中存在
send_button = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'button[data-testid="msh-chatinput-send-button"]')))
其中data-testid常常用于测试目的,以便于在自动化测试脚本中定位和识别这个按钮
if not send_button.get_attribute("disabled"):get_attribute 是一个webdriver方法,允许获取对应元素的属性值。
eg:下面HTML代码中当输入框中没有内容时,发送按钮为disable
<button
class="MuiButtonBase-root Mui-disabled MuiIconButton-root Mui-disabled MuiIconButton-sizeMedium css-i0tiaf"
tabindex="-1"
type="button"
data-testid="msh-chatinput-send-button"
id="send-button"
disabled="">
</button>此情况用于获取disabled的属性已经明确设置为不可用
如果按钮的 "disabled" 属性被设置为 ""(空字符串,表示禁用状态)
disabled:这是一个布尔属性,当出现在HTML元素中时,等同于 disabled="disabled"。它表明按钮在HTML中被定义为不可用。
6.用xpath选择器来定位页面上的特定元素
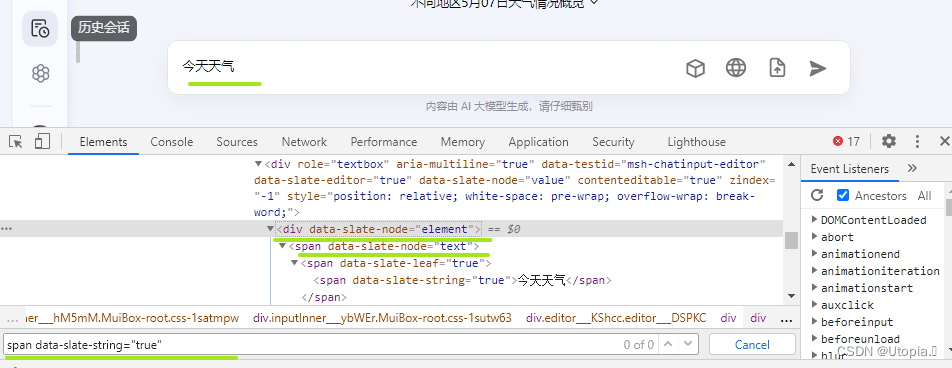
query_element = br.find_element_by_xpath('//div[@data-slate-node="element"]//span[@data-slate-string="true"]')这段代码的目的也就是找到输入框输入的内容所在标签,如下图“今天天气”
-
//:这表示从当前页面的根节点开始搜索,而不是仅在当前节点的子元素中搜索。 -
div[@data-slate-node="element"]:这部分定位了一个div元素,它的data-slate-node属性值为"element"。 -
//span[@data-slate-string="true"]:这部分定位了在前面找到的div元素内部的span元素,其data-slate-string属性值为"true"。 -
//div[@data-slate-node="element"]//span[@data-slate-string="true"]:整个表达式表示从页面的根节点开始,查找任意一个data-slate-node属性为"element"的div元素,然后在它的后代中查找任意一个data-slate-string属性为"true"的span元素。
7.获取定位元素文本内容 .text
if query_element.text!="1"如果元素文本内容不是1,内部代码继续运行
8.在原来基础上向输入框加入固定文本
element.text = f"联网查询,分析{df.iloc[i, 1]}目前用的学校名称,最后返回数据{'message':'学校名称'}".iloc是基于行和列的位置索引
df.iloc[i, 1] 访问DataFrame df 中索引为 i 的行,第二列(索引从0开始,所以索引1是第二列)的值。















 1721
1721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









