






相关系数的概念
相对关系的度量是在统计学和数据分析中非常重要的一个概念。Pearson相关系数、Spearman相关系数和Kendall Tau相关系数是常用的统计量,用于衡量两个变量之间的相关性。本文将介绍这些相关系数的计算方法,并通过Python代码进行演示。
Pearson相关系数
Pearson相关系数是用于度量两个变量之间线性关系的强度和方向。它的取值范围在-1到1之间,其中1表示完全正相关,-1表示完全负相关,0表示无线性相关。
Pearson相关系数的计算公式如下:
Pearson公式:
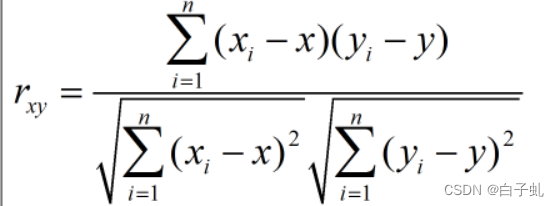
其中,公式和公式分别表示变量x和变量y的均值,n表示样本的大小,公式和公式分别表示第i个样本的变量x和变量y的取值。
下面是使用Python计算Pearson相关系数的代码示例:
import pandas as pd
import numpy as np
from scipy.stats import pearsonr
`
data = pd.read_excel('1.xlsx')
pc = pearsonr(data["文盲率"], data["人均gdp"]) #计算x与y的perrson的相关系数
print("皮尔逊相关系数即p值:", pc)
输出结果(示例):
皮尔逊相关系数即p值: (-0.44877343009977744, 0.012864435437715876)
Spearman相关系数
Spearman相关系数是一种非参数方法,用于度量两个变量之间的单调关系,无论是线性还是非线性。它通过将原始数据转换为秩次数据来计算相关性。
Spearman相关系数的计算公式如下:
Spearman公式:
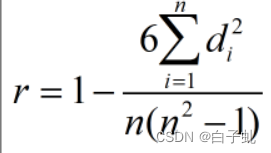
其中,n表示样本的大小,公式d表示变量x和变量y的秩次之差。
以下是使用Python计算Spearman相关系数的示例代码:
import pandas as pd
import numpy as np
from scipy.stats import spearmanr
data = pd.read_excel('1.xlsx')
spc,spc_p = spearmanr(data["x"], data["y"])
tj = spc*np.sqrt(len(data[x]))
print("spearmanr相关系数和p值:",spc,"统计量:",tj)
输出结果(实例):
spearmanr相关系数和p值: -0.6309934403268539 统计量: -3.398003668380899
Kendall Tau相关系数
Kendall Tau相关系数是用于度量两个变量之间的排序一致性的统计量。它适用于非线性和非单调的关系。
Kendall Tau相关系数的计算公式如下:
KendallTau公式:
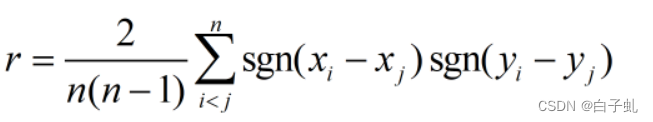
其中,n表示样本的大小,sgn公式和公式表示第i个样本的变量x和变量y的取值,公式是符号函数,当参数大于0时返回1,小于0时返回-1,等于0时返回0。
以下是使用Python计算Kendall Tau相关系数的示例代码:
import pandas as pd
import numpy as np
from scipy.stats import kendalltau
data = pd.read_excel('1.xlsx')
kd = kendalltau(data["文盲率"], data["人均gdp"])
print("kendall检验的相关系数即p值",kd)
输出结果(示例):
kendall检验的相关系数即p值:(-0.46950548923053803, 0.012545646844556)
相关系数的比较
Pearson相关系数适用于线性关系的度量,而Spearman和Kendall Tau相关系数适用于非线性和非单调关系的度量。当数据近似线性时,Pearson相关系数通常是最合适的选择。当数据存在异常值或者非线性关系时,可以考虑使用Spearman相关系数或Kendall Tau相关系数。
需要注意的是,这些相关系数只能测量变量之间的单一关系,不能推断因果关系。
结论
本文介绍了Pearson相关系数、Spearman相关系数和Kendall Tau相关系数的计算方法,并提供了相应的Python代码示例。这些相关系数是在统计学和数据分析中常用的工具,能够帮助我们理解和描述变量之间的关系。在选择相关系数时,需要根据数据的特点和研究问题的要求进行选择。















 3527
3527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









