






随机森林中的每棵决策树都是通过对一部分特征进行随机采样来构建的。特征重要性指标可以通过计算每个特征在所有决策树中用于划分样本时的平均减少不纯度(如Gini指数或信息增益)来衡量。在Scikit-learn等库中,你可以通过feature_importances_属性来获取特征重要性。
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
rf = RandomForestClassifier()
# 拟合模型
rf.fit(X_train, y_train)
# 获取特征重要性
importances = rf.feature_importances_
可视化单棵决策树
Scikit-learn提供了plot_tree函数来绘制单棵决策树。plot_tree()函数可以绘画随机森林的树树结构
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
#绘制随机森林的第一棵树
plt.figure(figsize=(20, 10))
plot_tree(rf.estimators_[0], feature_names=feature_names, filled=True)
plt.show()得出结果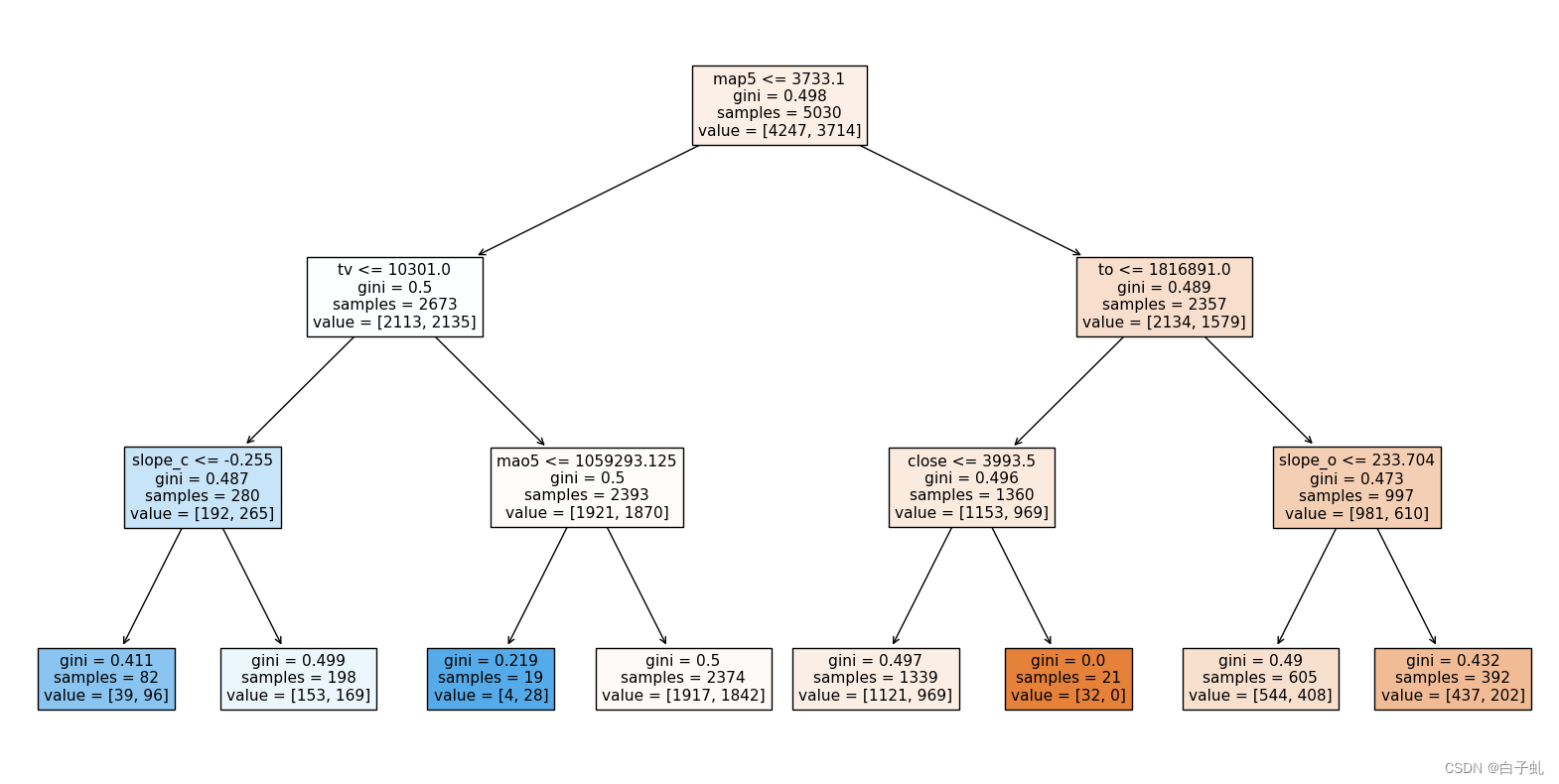 :
:















 2283
2283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









