







文章目录

论文题目:通过阅读实体描述实现零样本实体链接
论文链接:https://arxiv.org/abs/1906.07348
arXiv:1906.07348v1 [cs.CL] 18 Jun 2019
摘要
我们提出了 "零镜头实体链接 "任务,即必须在没有域内标注数据的情况下将提及链接到未知实体。该任务的目标是将实体稳健地转移到高度专业化的领域,因此不假定有元数据或别名表。在这种情况下,实体只能通过文本描述来识别,模型必须严格依赖语言理解来解析新实体。首先,我们证明了在大量未标记数据上预先训练的强大阅读理解模型可用于泛化未见实体。其次,我们提出了一种简单有效的自适应预训练策略(我们称之为领域自适应预训练(DAP)),以解决与在新领域中链接未见实体相关的领域转移问题。我们介绍了在我们为这项任务构建的新数据集上进行的实验,结果表明 DAP 比包括 BERT 在内的强大预训练基线更有优势。数据和代码可在 https://github.com/lajanugen/zeshel。
1 介绍
当目标实体词典中存在大量可用于训练的实体消歧提及时,实体链接系统就会取得很高的性能。这类系统通常使用强大的资源,如高覆盖率的别名表、结构化数据和链接频率统计。例如,Milne 和 Witten(2008 年)的研究表明,仅使用从维基百科训练文章的超链接统计中收集到的先验概率,就能使维基百科测试文章中链接预测任务的准确率达到 90%。
虽然之前的大多数工作都集中在与一般实体数据库的链接上,但人们往往希望与专业实体词典进行链接,例如法律案例、公司项目描述、小说中的人物集或术语词汇表。遗憾的是,这些专业实体词典的标注数据并不容易获得,而且获取成本往往很高。因此,我们需要开发能够泛化到未见过的专门实体的实体链接系统。如果没有频率统计和元数据,这项任务就会变得更具挑战性。之前的一些研究已经指出了构建可泛化到未见实体集的实体链接系统的重要性(Sil 等人,2012 年;Wang 等人,2015 年),但采用了一套额外的假设。
在这项工作中,我们提出了一种新的零镜头实体链接任务,并为此构建了一个新的数据集。目标字典被简单地定义为一组实体,每个实体都有文字描述(例如,来自实体规范页面)。与之前的一些工作不同,我们并不限制提及的实体必须是已命名的实体,因为这将导致大量候选实体的出现,从而增加任务的难度。在我们的数据集中,有多个实体词典可用于训练,而任务性能则是在一组没有标注数据的测试实体词典上测量的。图 1 展示了任务设置。我们使用 Wikia 中的多个子域构建数据集,并使用超链接自动提取有标签的提及内容。
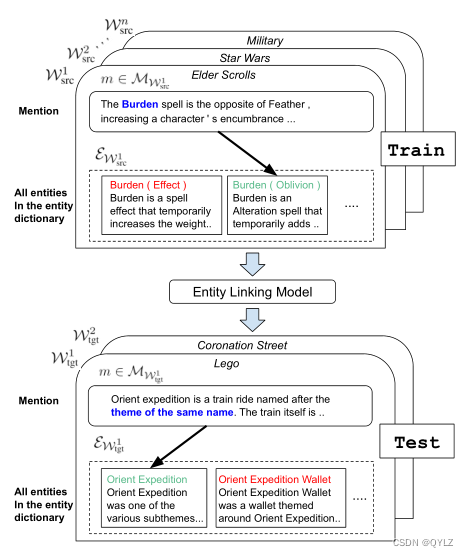
图 1:零镜头实体链接。图中显示了多个训练域和测试域(世界)。该任务有两个关键特性:(1) 它是零镜头任务,因为在训练过程中没有观察到任何测试世界实体被提及。(2) 只有文本(非结构化)信息可用。
零镜头实体链接对实体链接模型提出了两个挑战。首先,在没有强大的别名表或频率先验的情况下,模型必须阅读实体描述,并推理与上下文中提及内容的对应关系。我们的研究表明,一个强大的阅读理解模型至关重要。其次,由于没有测试实体的标注提及,模型必须适应新的提及上下文和实体描述。我们将重点关注这两个挑战。
本文的贡献如下:
- 我们提出了一项新的零镜头实体链接任务,旨在以最少的假设挑战实体链接系统的泛化能力。我们为这项任务构建了一个数据集,该数据集将公开发布。
- 我们利用最先进的阅读理解模型建立了一个强大的基线。我们的研究表明,对上下文中的提及和实体描述之间的关注对于这项任务至关重要,而在之前的实体链接工作中并未使用过这种关注。
- 我们提出了一种简单而新颖的适应策略,称为领域适应性预训练(DAP),并证明它能进一步提高实体链接性能。
2 零点实体链接
我们首先回顾了标准实体链接任务定义,并讨论了先前系统的假设。然后,我们定义了零镜头实体链接任务,并讨论了它与之前工作的关系。
2.1 审查: 实体链接
实体链接(Entity linking,EL)是通过将实体提及与给定的实体数据库或字典中的条目链接起来,从而实现实体提及的基础化。从形式上看,给定一个提及 m 及其上下文,实体链接系统会将 m 链接到实体集 E = {ei}i=1,…,K 中的相应实体,其中 K 是实体的数量。EL 的标准定义(Bunescu 和 Pasca,2006;Roth 等人,2014;Sil 等人,2018)假定提及边界由用户或提及检测系统提供。实体集 E 可能包含数万甚至数百万个实体,因此这是一项具有挑战性的任务。实际上,许多实体链接系统都依赖于以下资源或假设:
单一实体集 假定在训练和测试示例中共享一个单一的实体集 E。
别名表 别名表包含给定提及字符串的候选实体,并将可能性限制在相对较小的范围内。这种表通常是根据标注的训练集和特定领域的启发式方法编制而成的。
频率统计 许多系统使用从大型标注语料库中获得的频率统计来估算实体的流行度以及某个提及字符串与某个实体建立链接的概率。这些统计数据在可用时非常强大。
结构化数据 有些系统假定可以访问结构化数据,如关系元组(如(巴拉克-奥巴马、配偶、米歇尔-奥巴马))或类型层次结构,以帮助消歧。
2.2 任务定义
这项任务的主要动机是扩大实体链接系统的范围,并使其具有泛化能力,适用于未见过的实体集。因此,我们放弃了上述假设,只做一个弱假设:存在一个实体字典E = {(ei, di)}i=1,…,K,其中di是实体ei的文本描述。
我们的目标是构建能够泛化到新领域和实体字典(我们称之为世界)的实体链接系统。我们定义一个世界为W =(MW,UW,EW),其中MW和UW分别是来自该世界的提及和文档的概率分布,而EW是与W关联的实体字典。来自MW的提及m被定义为来自UW的文档中的提及跨度。我们假设可以从一个或多个源世界Wsrc1…Wsrcn中获得标记的提及实体对进行训练。在测试时,我们需要能够为一个新的世界Wtgt中的提及打标签。请注意,实体集EWsrc1,…,EWsrcn,EWtgt是不相交的。图1给出了几个训练和测试世界的示例。
我们还假设可以从目标分布UWtgt和实体描述EWtgt中获取样本用于训练。这些样本可以用于无监督的适应目标世界。在训练过程中,Wtgt中的提及边界不可用。在测试时,将提及边界作为输入提供。
2.3 与其他 EL 任务的关系
我们总结了新引入的零次实体链接任务与之前EL任务定义之间的关系,并将其汇总在表1中。

表格1:实体链接任务定义的假设和资源。我们将任务定义分类基于以下几点: (i) 系统是否在训练领域内的提及上进行测试(In-Domain), (ii) 在训练过程中是否看到与目标实体集链接的提及(Seen Entity Set), (iii) 是否可以使用别名表或严格的标记重叠约束来得出一个小型高覆盖率候选集(Small Candidate Set), 以及(iv) 频率统计信息、(v) 结构化数据和(vi) 文本描述(实体词典)的可用性。
标准实体链接 在不同的数据集之间存在许多差异(Bunescu和Pasca,2006;Ling等,2015),但大多数都关注一个标准设置,即在训练过程中可以看到来自全面测试实体字典(通常是维基百科)的提及,而且可以利用丰富的统计信息和元数据(Roth等,2014)。还假定有标记的领域内文档和包含提及的文档也是可用的。
跨领域实体链接 最近的工作也已经推广到跨领域的设置,将不同类型的文本中的实体提及(如博客文章和新闻文章)与维基百科知识库进行链接,同时只使用维基百科中的标注实体进行训练(例如,Gupta等人(2017年);Le和Titov(2018年),等等)。
链接到任何数据库 Sil等人(2012)提出了一个与我们非常相似的任务设置,后来的工作(Wang等人,2015)也遵循了类似的设定。零次元实体链接(zero-shot EL)与这些工作之间的主要区别在于,他们假设要么有一个高覆盖率的别名表,要么有高精度的标记重叠启发式算法来减少实体候选集的大小(即,在Sil等人(2012)中少于四个),并依赖于结构化数据来帮助消歧义。通过编译和发布一个专注于从文本信息中学习的多世界数据集,我们希望能够推动在更广泛的应用程序中链接实体的进步。
基于词典词汇定义的工作与词语歧义消解相关(Chaplot和Salakhutdinov,2018),但这个任务表现出较低的歧义性,现有的表述并未关注领域泛化。
3 数据集构建
我们构建了一个新的数据集,以研究使用来自Wikia的文档的零次实体链接问题。Wikia是社区编写的百科全书,每个Wikia都专门关注一个特定的主题或主题,如一本书或电影系列中的虚构宇宙。Wikia具有许多适合我们任务的有趣特性。 标注的提及可以根据超链接自动提取。提及和实体具有丰富的文档上下文,可以被阅读理解方法利用。每个维基百科都有大量与特定主题相关的独特实体,使其成为一个有用的基准,用于评估实体链接系统的领域泛化能力。
我们使用来自16个维基的数据,并使用其中的8个进行训练,4个用于验证,4个用于测试。为了构建训练和评估数据,我们首先从维基中提取大量提及。许多这些提及可以通过字符串匹配在提及字符串和实体文档标题之间轻松链接。这些提及在数据集构建过程中被降低采样,并占据最终数据集的小部分(5%)。虽然这种方法并不完全代表实体提及的自然分布,但这种数据构建方法遵循了最近的研究工作,这些研究工作的重点是评估在实体链接问题中具有挑战性的方面(例如,Gupta等人(2017)选择了具有多个可能实体候选者的提及来评估领域内未见过的实体性能)。每个维基亚文件对应一个实体,由文件的标题和内容表示。这些实体与它们的文本描述配对,构成了实体字典。
由于任务已经相当具有挑战性,我们假设目标实体存在于实体字典中,并将NIL识别或聚类(NIL提及/实体指的是知识库中不存在的实体)留给了未来的任务和数据集版本。
我们根据提及与相应实体标题之间的标记重叠对提及进行分类。高重叠:标题与提及文本相同,多个类别:标题是提及文本后跟一个消歧短语(例如,提及字符串:“蝙蝠侠”,标题:“蝙蝠侠(乐高)”),模糊子串:提及是标题的子串(例如,提及字符串:“特工”,标题:“特工”)。所有其他提及的内容被归类为低重叠。这些提及分别占据了数据集中大约5%,28%,8%和59%的提及量。
表2显示了数据集的一些统计信息。每个领域都有大量实体,范围从1万到10万不等。训练集有49,275个标注的提及。为了检查在域内推广性能,我们构建了两个存储备份集,分别是“seen”和“unseen”,每个集都有5,000个提及,分别包含链接到仅在训练过程中见过或未见过的实体。验证集和测试集各有10,000个提及(都是未见过的)。
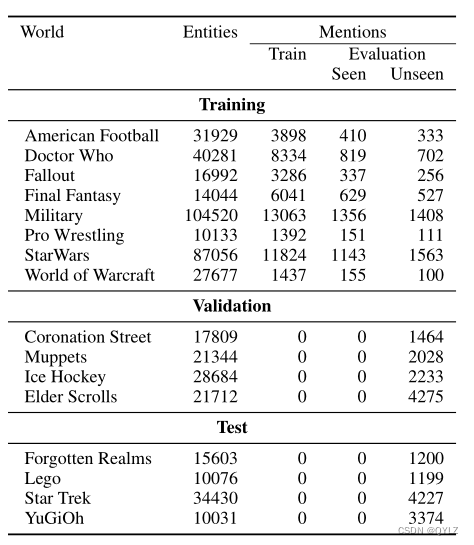
表格2:基于Wikia的零次实体链接数据集。
表3展示了数据集中的实体和提及示例。在不同领域中,用于提及和实体描述的词汇和语言差异很大。除了获取特定领域的知识外,理解实体描述和进行推理也是解决提及所必需的。

表3:来自《加冕街》和《星球大战》的例子,展示了不同的语言使用导致了实体和提及候选者之间的差异。注意,不同世界之间的语言使用差别很大。
4 实体链接模型
我们采用了一个由快速候选生成阶段和更昂贵但更强大的候选排名阶段组成的两阶段流程。
4.1 生成候选
在没有别名表进行标准实体链接的情况下,一个自然的替代方法是使用IR方法进行候选生成。我们使用BM25,这是一种TF-IDF的变体,用于测量提及字符串和候选文档之间的相似性。通过Lucene的BM25评分检索到的top-k实体用于训练和评估。在我们的实验中,k设置为64。前64个候选者的覆盖率平均不足77%,这表明任务的难度较大,并且在候选者生成阶段仍有很大的改进空间。
4.2 候选排序
由于比较两种文本(上下文中的提及和候选实体描述)的任务类似于阅读理解与自然语言推理任务,我们采用了一个基于深度Transformer(Vaswani等人,2017)的架构,该架构在这些任务上取得了最先进的性能(Radford等人,2018;Devlin等人,2019)。
正如BERT(Devlin等人,2019)中所述,上下文中的提及m和候选实体描述e,每个由128个词片组成,被连接在一起,并作为序列对输入到模型中,同时加上特殊的开始和分隔符:([CLS] m [SEP] e [SEP])。提及的单词通过一个特殊的嵌入向量添加到提及单词的嵌入中。转换器编码器产生一个向量表示hm,e,它是输入对的最后一个隐藏层输出,特殊池化标记为[CLS]。给定候选集中的实体以w⊤hm,e的形式进行评分,其中w是一个学习到的参数向量,模型使用softmax损失进行训练。在我们的实验中,使用了一个具有12层、隐藏维度大小为768和12个注意力头的架构。我们将这种模型称为全Transformer。通过使用Transformer同时编码实体描述和上下文中的提及,它们可以在每一层中相互关注。
请注意,之前用于实体链接的神经方法并没有探索这种带有深度交叉注意力的架构。为了评估这一方法与之前工作的不同之处的价值,我们实现了以下两个变体:(i) 池化式转换器:这是一种类似于双子网络的结构,它使用两个深度变换器分别从上下文中提取提及内容的单向量表示hm和候选实体的单向量表示he;它们的输入分别是上下文中的提及内容和实体描述,以及特殊标记来指示文本的边界:([CLS] m [SEP]) 和 ([CLS] e [SEP]),输出是在特殊开始标记处的最后一个隐藏层编码。评分函数是hm⊤he。在许多以前的工作中,例如Gupta等人(2017年),已经使用了两个组件的单个向量表示。(ii) Cand-Pool-Transformer:一种变体,它使用单个实体向量表示,但可以像Ganea和Hofmann(2017)那样关注提及的个体标记及其上下文。 这种架构还使用了两个Transformer编码器,但引入了一个额外的注意力模块,使得它可以关注提及在上下文中的个体标记表示。
在实验部分,我们还比较了重新实现的Gupta等人(2017)和Ganea和Hofmann(2017),它们与Pool-Transformer和Cand-Pool-Transformer类似,但具有不同的神经网络架构用于编码。
5 适应目标世界
我们关注使用无监督预训练来确保下游模型对目标领域数据具有鲁棒性。预训练存在两种通用策略:(1)任务自适应预训练,和(2)开放语料库预训练。我们在下面描述这两种策略,并提出一种新的策略:领域自适应预训练(DAP),它与现有的两种方法相辅相成。
任务自适应预训练 Glorot 等人(2011年);陈等人(2012年);杨和艾森斯坦(2015年),等等,对源域和目标域的无标签数据进行联合预训练,目的是发现能够泛化到不同域的特征。在预训练之后,模型将在源域的标注数据上进行微调。
开放语料库预训练 这种方法不是显式地适应目标领域,而是简单地在大量语料库上进行无监督的预训练,然后在源域标签数据上进行微调。这种做法的例子包括 ELMo(Peters 等人,2018年)、OpenAI GPT(Radford 等人,2018年)和 BERT(Devlin 等人,2019年)。直观地说,如果开放语料库足够大且多样化,那么目标领域分布很可能会通过预训练来捕捉到一部分。确实,开放语料库预训练已被证明对离域性能的提升远大于在域性能(He等,2018)。
领域自适应预训练 除了其他方法的预训练阶段外,我们提出在中间插入一个领域的自适应预训练(DAP)阶段,其中模型仅在目标域数据上进行预训练。与往常一样,DAP之后是一个最终的源域标签数据上的微调阶段。DAP的直觉是,表征能力是有限的,因此模型应该优先考虑目标域表示的质量。
我们引入符号来描述预训练阶段的各种组合方式。
• Usrc 表示来自源世界文档分布的文本段的并集,UWsrc1 … UWsrcn。
•Utgt 表示目标世界 Wtgt 的文档分布中的文本段。
•Usrc+tgt表示从 Usrc 和 Utgt 中随机交错的文本段。
•UWB 表示开放语料库中的文本段,在我们的实验中是用于 BERT 的 Wikipedia 和 BookCorpus 数据集。
我们可以将一系列预训练阶段串联起来。例如,UWB → Usrc+tgt → Utgt 表示模型首先在开放语料库上进行预训练,然后在源域和目标域的组合上进行预训练,接着在仅目标域上进行预训练,最后在源域标注数据上进行微调。我们发现,将不同的预训练策略串联起来可以提供累积的增益。
6 实验
预训练 在所有实验中,我们使用BERT-Base模型架构。用于无监督预训练的Masked LM目标(Devlin等人,2019)。对于多阶段预训练的语言模型和实体链接任务的微调,我们遵循Devlin等人(2019)的建议,使用较小的学习率2e-5。对于从头开始训练的模型,我们使用学习率1e-4。
评估 我们将归一化的实体链接性能定义为在测试实例子集上的性能评估,其中黄金实体是在候选生成期间检索的前k个候选人之一。未归一化的性能是在整个测试集上计算的。我们的基于信息检索的候选生成在验证集和测试集上的准确率分别为76%和68%,排名前64位的召回率分别为76%和68%。未归一化的性能因此受到这些数字的上限限制。加强候选生成阶段可以提高未归一化性能,但这超出了我们工作的范围。在一组世界中的平均性能是通过宏观平均来计算的。性能被定义为单个最佳识别实体(前1名准确率)的准确性。
6.1 基线
我们首先在表4中查看零次实体链接的一些基线。我们包括一些简单的基线,如Levenshtein编辑距离和TF-IDF,它们分别比较提及字符串与候选实体标题和完整文档描述之间的相似性,以对候选实体进行排名。
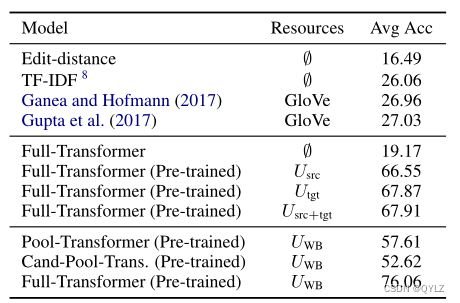
表4:零次实体链接的基线结果。在所有验证域上,平均归一化的实体链接准确率。Usrc+tgt表示在训练和验证世界的未标记数据上进行的语言模型预训练。
我们重新实现了最近为实体链接设计的神经模型(Ganea和Hofmann,2017;Gupta等人,2017),但并不期望它们表现良好,因为原始系统是为那些有目标实体标注提及或元数据可用的设置而设计的。这些模型的糟糕表现证明了在零样本实体链接任务中使用强大的阅读理解模型的必要性。
在使用全Transformer模型时,为了获得合理的性能,预训练是必要的。我们展示了在任务语料库的不同子集(Usrc、Utgt、Usrc+tgt)上进行预训练的模型结果,以及在外部大型语料库(UWB)上进行预训练的结果。
在表4中,我们还比较了Pool-Transformer、Candidate-Pool-Transformer和Full-Transformer。Full-Transformer与其他变体之间的显著差距表明,通过嵌入在Transformer中的交叉注意力机制允许两个输入之间进行细粒度比较的重要性。我们假设,以前的实体链接系统不需要如此强大的阅读理解模型,因为有很强的额外元信息可用。本文中剩余的实验在不另作说明的情况下都使用全变换器模型。
6.2 对未知实体和新世界
为了分析未见实体和领域迁移在零次实体链接中的影响,我们通过在训练世界中保留的提及上进行预测,评估在更标准的领域内实体链接设置下的性能。表5比较了针对不同实体分割的实体链接性能。不出所料,从训练世界中看到的实体最容易链接到。对于来自训练世界的未见实体,我们观察到性能下降了5个百分点。来自新世界的实体(根据定义是未被看到的,并在跨领域文本中提到)被证明是最困难的。由于语言分布和实体集的转变,我们观察到性能下降了11个百分点。这种巨大的泛化差距表明了适应新世界的重要性。

表格5:全变换器(UWB)模型在训练和验证世界中已知和未知实体上的性能评估。
6.3 领域自适应预训练的影响
我们的实验表明,DAP在三个最先进的预训练策略上有所改进:
• Usrc+tgt:任务自适应预训练,它结合源数据和目标数据进行预训练(Glorot等,2011)。
• UWB:开放语料库预训练,使用维基百科和BookCorpus进行预训练(我们使用预先训练好的BERT模型(Devlin等,2019))。
•UWB → Usrc+tgt:这两个策略连在一起。虽然没有先前的工作将这种方法应用于领域适应,但Howard和Ruder(2018)提出了一种类似的用于任务适应的方法。
结果如图2(a)所示。DAP通过在仅针对目标领域数据的额外预训练阶段来改进所有预训练策略。最佳设置UWB → Usrc+tgt → Utgt将所有现有策略串联起来。DAP在强预训练模型(Devlin等,2019)的基础上提高了2%的性能。
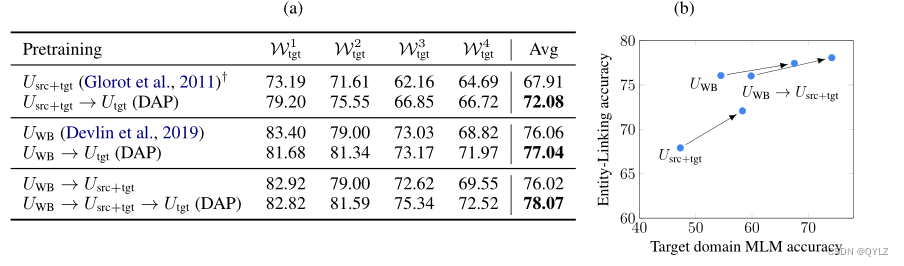
图2:左:(a)使用领域自适应预训练的影响。我们在预训练后在源标签数据上微调所有模型。右:(b)预训练模型的MLM(Masked LM)准确度与目标领域上微调模型的实体链接性能之间的关系。添加领域自适应预训练可以提高MLM准确度和实体链接性能。注释:src表示所有8个训练世界的联合体,我们一次适应一个目标世界。目标世界包括Wtgt1:加冕街,Wtgt2:木偶秀,Wtgt3:冰球,Wtgt4:上古卷轴。†我们参考Glorot等人(2011)的论文,了解在源数据和目标数据上训练去噪自编码器的想法,而不是实际的实现。有关更多详细信息,请参阅正文。
为了进一步分析DAP的结果,我们绘制了目标未标记数据上Masked语言模型(MLM准确度)与最终目标归一化准确度(在源标记数据上进行微调后)之间的关系图,如图2(b)所示。在目标未标记数据上增加一个额外的预训练阶段不出所料地提高了MLM的准确度。更有趣的是,我们发现MLM准确度的提高总是伴随着实体链接准确度的提高。直观地说,无监督目标的表现反映了学习到的表示的质量,并且与下游性能密切相关。我们在实验中证明了这种趋势对于多种预训练策略都成立。
6.4 测试结果和性能分析
表6显示了在测试世界上的归一化和未归一化的实体链接性能。我们最好的模型将所有预训练策略串联在一起,实现了归一化准确度为77.05%和未归一化准确度为56.58%。请注意,未归一化准确度对应于从数万个候选实体中识别出正确的实体。
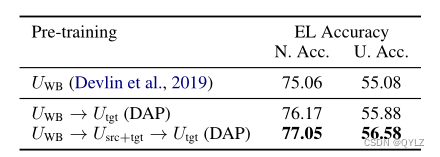
表6:在测试域上的性能,使用全Transformer。N. Acc表示归一化的准确率,U. Acc表示未归一化的准确率。未归一化准确率的上限为68%,这是候选生成阶段的前64名召回率。
为了分析模型犯的错误,我们在表7中比较了不同提及类别的实体链接(EL)准确率。候选生成(召回率@64)在低重叠类别中表现不佳。然而,对于这些提及,排名模型的表现与其他困难类别相当。因此,通过加强候选生成,可以显著提高整体实体链接准确率。
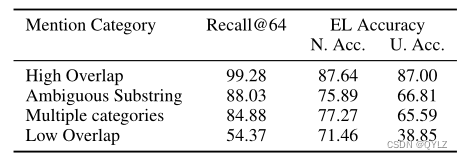
表7:根据提及类别对测试域的性能分类。Recall@64表示候选生成的前64名表现。N. Acc. 和 U. Acc. 分别是归一化和未归一化的准确率。
7 相关工作
我们在第2部分讨论了以前的实体链接任务定义,并将它们与我们的任务进行了比较。在这里,我们简要概述相关的实体链接模型和无监督领域适应方法。
实体链接模型 在给定提及边界作为输入的实体链接中,可以将其分为候选生成和候选排名的任务。当频率信息或别名表不可用时,以前的工作使用提及字符串与实体名称之间的相似度度量来进行候选生成(Sil等,2012;Murty等,2018)。对于候选排名,最近的工作采用了上下文中提及的分布式表示和实体候选人的神经模型来评分它们的兼容性。上下文中的提及已经使用诸如卷积神经网络(Murty等,2018)、长短期记忆(Gupta等,2017)或词袋嵌入(Ganea和Hofmann,2017)等方法进行表示。实体描述已经使用类似架构进行表示。据我们所知,虽然有些模型允许在单向量实体嵌入和上下文提及的标记表示之间进行交叉注意力,但没有先前的工作在提及上下文和实体描述之间使用完全的交叉注意力。
以前与我们最相似的实体链接任务的工作主要是使用线性模型比较上下文中的提及和实体描述以及相关结构化数据(Sil等,2012)。Sil等人(2012)还提出了一种远程监督方法,该方法可以利用目标领域中提及的第一轮预测作为嘈杂的监督来重新训练领域内模型。我们相信这种方法与无监督表示学习相辅相成,并可能带来额外的好处。在另一个与我们类似的任务中,王等人(2015)使用集体推断和目标数据库关系,在没有特定于(领域,目标数据库)的标注训练数据的情况下取得了良好的性能。 集体推断是另一个有前途的方向,但在没有元数据的情况下可能取得有限的成功。
无监督领域适应 在无监督领域适应方面有很多研究方法,其中有一个已标注的源域训练集和目标域的未标注数据可用。在这个方向的大部分工作中,人们假定训练和测试样本由(x,y)对组成,其中y属于一个固定的共享标签集Y。这个假设适用于分类和序列标注,但不适用于零样本实体链接,因为源域和目标域的标签是不相交的。
大多数最先进的方法是通过降噪训练目标来学习源域和目标域实例的非线性共享表示(Eisenstein,2018)。在第5节中,我们概述了这类工作并提出了一种改进的领域自适应预训练方法。
对抗训练方法(Ganin等人,2016年),也适用于源域和目标域之间不共享空间Y的任务(Cohen等人,2018年),以及多源域适应方法(Zhao等人,2018年;Guo等人,2018年)与我们的工作互补,并可以提高性能。
8 结论
我们为零镜头实体链接引入了一项新任务,并为此构建了一个多世界数据集。该数据集可用作实体链接研究的共享基准,重点研究那些没有标签提及、仅通过描述来定义实体的专业领域。通过将强大的神经阅读理解能力与领域自适应预训练相结合,我们提出了一个强大的基准。
该任务的未来变体可以包含 NIL 识别和提及检测(而不是提供提及边界)。候选词生成阶段还有很大的改进空间。我们还希望联合解析文档中提及内容的模型能比单独解析这些内容的模型表现更好。
A 检验模型误差和预测
在表 8、9、10 和 11 中,我们展示了一些提及和模型预测的示例。对于每个实例,示例都显示了正确的黄金实体和模型的前 5 个预测结果。示例显示了以提及为中心的 32 个标记上下文和候选实体文档的前 32 个标记。
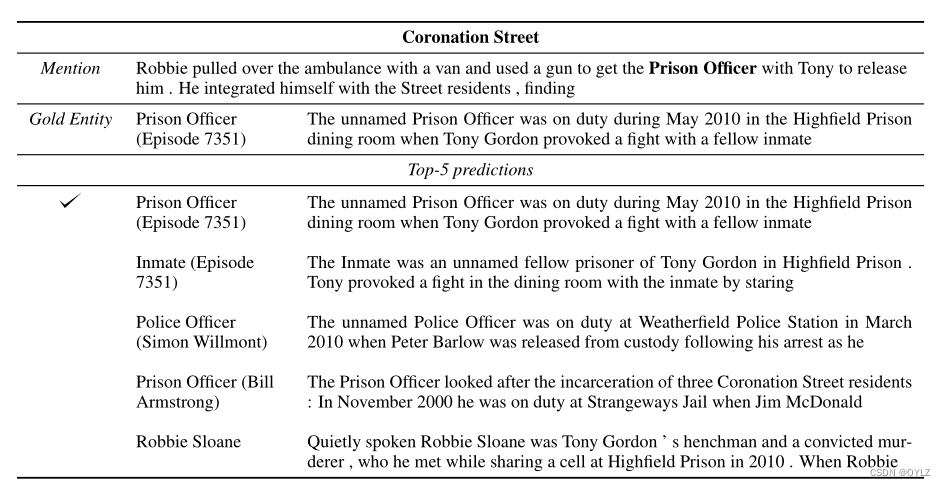
表 8:《加冕街》中的提及和候选实体。
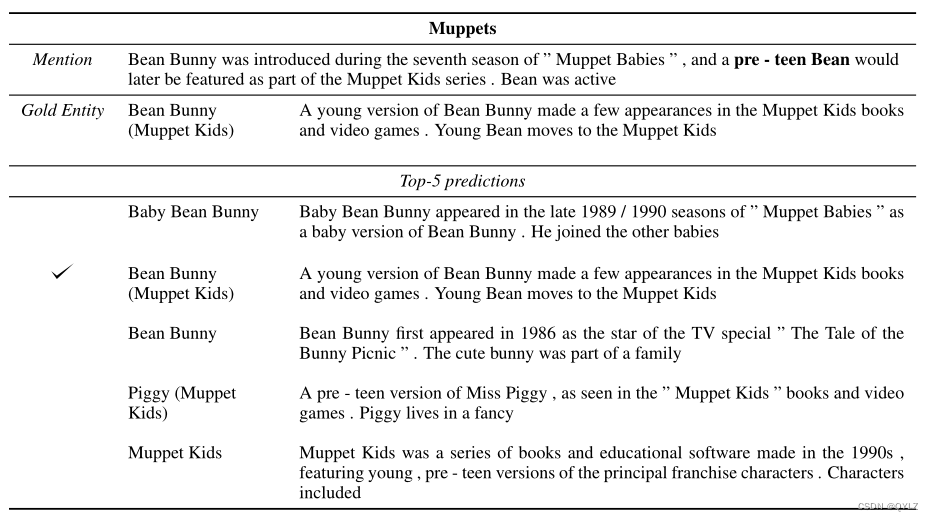
表 9:《布偶团》中的提及和候选实体。
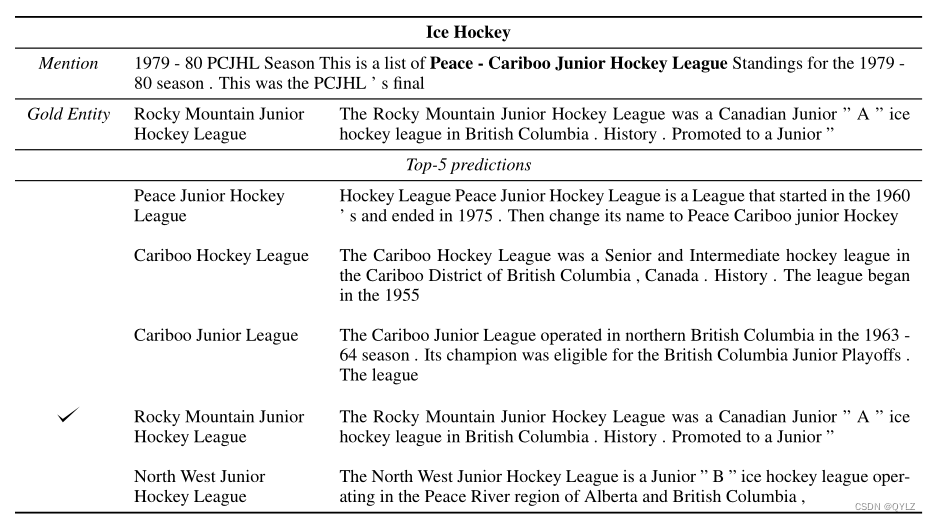
表 10:《冰上曲棍球》中的提及和候选实体。

表 11:《上古卷轴》中的提及和候选实体。














 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









