







文章目录

论文标题:HybridQA:一个用于表格和文本数据的多跳问题回答数据集
论文链接:https://arxiv.org/abs/2004.07347
arXiv:2004.07347v3 [cs.CL] 11 May 2021
摘要
现有问答数据集主要关注处理同质化信息,基于文本或者知识库/表格信息单独进行。然而,由于人类知识分布在不同形式中,仅使用同质化信息可能会导致严重的覆盖问题。为了填补这一空白,我们推出了HybridQA1,这是一个新的大规模问答数据集,需要对异质信息进行推理。每个问题都与一个维基百科表格和多个与表格中实体链接的自由格式文本文档相对应。这些问题旨在聚合表格信息和文本信息,即缺乏任何一种形式都会使问题无法回答。我们使用了三种不同的模型进行了测试:1) 只包含表格的模型。 2) 只包含文本的模型。 3) 一种混合模型,结合异构信息来找到答案。 实验结果表明,两个基线模型获得的EM分数低于20%,而混合模型能够达到40%以上的EM。这段差距表明在HybridQA中需要聚合异构信息。然而,混合模型的分数仍然远远落后于人类的表现。因此,HybridQA可以作为一个具有挑战性的基准来研究利用异构信息进行问题回答。
1 介绍
问答系统的目标是回答我们感兴趣的任何形式的问题,并提供由自由文本(如维基百科段落)(Rajpurkar等,2016;Chen等,2017;Yang等,2018)或结构化数据(如Freebase/WikiData)(Berant等,2013;Kwiatkowski等,2013;Yih等,2015;Weston等,2015)和WikiTables(Pasupat和Liang,2015)提供的证据。两种形式都有其优点,自由格式的语料库通常具有更好的覆盖范围,而结构化数据在处理复杂多跳问题时具有更好的组合性。由于不同表示形式的优势,人们喜欢在实际应用中将它们结合起来。因此,有时假设问题在一段文章中一定有答案是不理想的。本文旨在模拟一种更真实的环境,其中证据分布在异构数据中,模型需要从不同形式的信息中收集和整合信息以回答问题。已经有一些关于构建混合问答系统(Sun 等人,2019,2018;Xiong 等人,2019)的开创性工作。这些方法采用了仅包含知识库(KB)的数据集(Berant 等人,2013;Yih 等人,2015;Talmor 和 Berant,2018),通过随机遮盖知识库三元组并将其替换为文本语料库来模拟混合设置。实验结果证明了明显的改进,这为混合问答系统整合异构信息的潜力提供了启示。
尽管存在许多有价值的问答数据集(如表1中所列),但这些数据集最初是设计用于在注释过程中使用结构化或非结构化信息的。不能保证这些问题需要聚合异构信息来找到答案。因此,设计混合问答系统可能比非混合系统带来微小的好处,这大大阻碍了构建混合问答系统的研发进展。
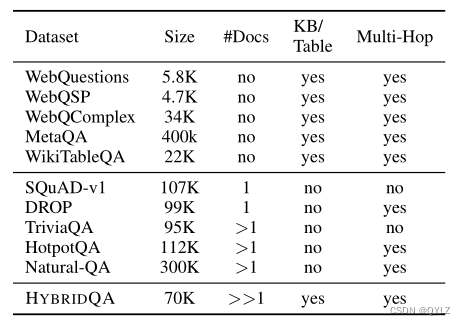
表1:现有数据集的比较,其中#docs表示针对特定问题提供的文档数量。1)基于知识库的数据集:WebQuestions(Berant等人,2013),WebQSP(Yih等人,2016),Web-Complex(Talmor和Berant,2018),MetaQA(Zhang等人,2018),WikiTableQuestion(Pasupat和Liang,2015)。2) 只包含文本的单一段落数据集:像 SQuAD(Rajpurkar 等人,2016 年),DROP(Dua 等人,2019 年)。3) 开放领域的纯文本数据集:TriviaQA(Joshi 等人,2017 年),HotpotQA(Yang 等人,2018 年),Natural Questions(Kwiatkowski 等人,2019 年)。
为了填补这一空白,我们构建了一个异构的问答数据集HYBRIDQA,该数据集是通过众包基于维基百科表格收集的。在注释过程中,每个众包工作者都会看到一个表格以及与其相关的超链接维基百科文章,以便提出需要整合这两种信息的问题。该数据集包含大约7万个问题回答对,与1.3万个维基百科表格相对应。正如Wikitables(Bhaga- vatula等人,2013年)是由高素质的专业人士策划的,以组织有关特定主题的一组信息,它的信息在文本中大多缺失。这种互补性使得WikiTables成为混合问答的理想环境。为了确保答案不能被单跳或同质模型破解,我们仔细采用不同的策略来校准注释过程。示例如图1所示。这张表格旨在描述不同奥运会上的缅甸旗手,其中第二列包含有关奥运会事件的超链接文章,第四列包含有关个人旗手传记的超链接文章。该数据集在以下意义上是多跳和混合的:1)问题需要多个跳转来找到答案,每个推理跳转可以使用表格或文本信息。2)答案可能来自表格或一段文字。
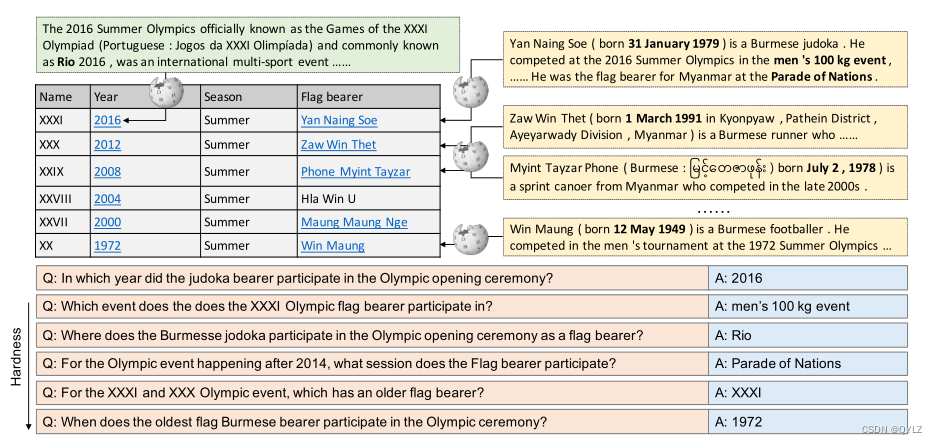
图1:来自维基百科页面的注释问答对示例。下划线实体具有超链接的段落,这些段落显示在方框中。下半部分展示了根据难度大致分类的人工标注的问题答案对。
在我们的实验中,我们实现了三种模型,即仅表格模型、仅段落模型和一个异质模型HYBRIDER,它结合了两种信息形式来执行多跳推理。我们的实验表明,两个同质模型的准确率仅为20%以下,而HYBRIDER可以实现40%以上的准确率,这说明在HYBRIDQA上进行多跳推理的必要性。由于HYBRIDER仍然远远落后于人类的表现,我们认为这将是社区面临的具有挑战性的下一个问题。
2 数据集
在本节中,我们将描述如何爬取高质量的表格及其关联段落,然后描述如何收集混合问题。HYBRIDQA的统计数据如表2所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









