






第二周学习作业
- 1. 总结linux安全模型
- 2. 总结学过的权限,属性及ACL相关命令及选项,示例。
- 3. 结合vim几种模式,学会使用vim几个常见操作。
- 4. 总结学过的文本处理工具,文件查找工具,文本处理三剑客, 文本格式化命令(printf)的相关命令及选项,示例。
- 5. 总结文本处理的grep命令相关的基本正则和扩展正则表达式。
- 6. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
- 7. 通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?
- 8. 结合编程的for循环,条件测试,条件组合,完成批量创建100个用户,
- 9. 磁盘存储术语总结: head, track, sector, sylinder.
- 10. 总结MBR,GPT结构。
- 11. 总结学过的分区,文件系统管理,SWAP管理相关的命令及选项,示例fdisk, parted, mkfs, tune2fs, xfs_info, fsck, mount, umount, swapon, swapoff
- 12. 总结raid 0, 1, 5, 10, 01的工作原理。总结各自的利用率,冗余性,性能,至少几个硬盘实现。
- 13. 完成不影响业务对LVM磁盘扩容及缩容示例。
1. 总结linux安全模型
3A
- 资源分派:
- Authentication:认证,验证用户身份
- Authorization:授权,不同的用户设置不同权限
- Accouting|Audition:审计
当用户登录成功时,系统会自动分配令牌token,包括:用户标识和组成员等信息
- 用户
Linux中每个用户是通过User Id (UID)来唯一标识的
是一个纯数字,系统自动分配的,Linux中只靠UID来判断用户而不是用户名
- 管理员:root, 0
- 普通用户:1-60000 自动分配
- 系统用户:1-499 (CentOS 6以前), 1-999 (CentOS 7以后)对守护进程获取资源进行权限分配
- 登录用户:500+ (CentOS6以前), 1000+(CentOS7以后)给用户进行交互式登录使用
用id命令查看UID
- 用户组
Linux中可以将一个或多个用户加入用户组中,用户组是通过Group ID(GID) 来唯一标识的。
- 管理员组:root, 0
- 普通组:
- 系统组:1-499(CentOS 6以前), 1-999(CentOS7以后), 对守护进程获取资源进行权限分配
- 普通组:500+(CentOS 6以前), 1000+(CentOS7以后), 给用户使用
减少了非陪权限的复杂性,root组里的用户并不一定是超级管理员
在Linux里允许用户名和组名同名,Windows不允许用户名和组名同名
- 用户和组的关系
- 用户的主要组(primary group):用户必须属于一个且只有一个主组,
默认创建用户时会自动创建和用户名同名的组,做为用户的主要组,由于此组中只有一个用户,又称为- 私有组 - 用户的附加组(supplementary group): 一个用户可以属于零个或多个辅助组,附属组,附加组可有可无
- 安全上下文
能不能访问资源,是由执行命令者的身份决定的
Linux安全上下文Context:运行中的程序,即进程 (process),以进程发起者的身份运行,进程所能够访问资源的权限取决于进程的运行者的身份
比如:分别以root 和pang 的身份运行/bin/cat /etc/shadow ,得到的结果是不同的,资源能否能被访问,是由运行者的身份决定,非程序本身。
要想访问资源先检查权限,没权限先赋权!
pang用户可以查看passwd但是无法查看shadow文件
2. 总结学过的权限,属性及ACL相关命令及选项,示例。
权限
- 文件的权限主要针对三类对象进行定义
owner 属主,u
group 属组,g
other 其他,o
注意:
用户的最终权限,是从左向右进行顺序匹配的,即“所有者”、“所属组”、“其他人”,一旦匹配权限立即生效,不再向右查看其权限
r和w权限对root用户无效
只要所有者,所属组或other三者之一有x权限,root就可以执行
- 每个文件针对每类访问者都定义了三种常用权限
- 每个文件针对每类访问者都定义了三种权限
r Readable 4
w Writable 2
x Excutable 1
- 对文件的权限:
r 可使用文件查看类工具,比如:cat,可以获取其内容
w 可修改其内容,文件的是否内删除和文件的权限无关
x 可以把此文件提请内核启动为一个进程,即可以执行(运行)此文件(此文件的内容必须是可执行)
文件权限常见组合
--- 0 r 4 r-x 5 rw 6 rwx 7
- 对目录的权限:
r 可以使用ls查看此目录中文件名列表,但是无法查看到文件的属性meta信息,包括inode号,不能查看文件的内容
w 可以在此目录中创建文件,也可以删除此目录中的文件,而和此被删除的文件的权限无关
x 可以cd进入此目录,可以使用ls -l file或者stat file 查看此目录中指定文件的元数据,当预先知道文件名称时,也可以查看文件的内容,属于目录的可访问的最小权限
X 分配给目录或者有部分x权限的文件的x权限,对无任意x权限的文件则不会分配x权限
- 不能访问目录
r-x 只读目录
rwx 可读可写目录
acl访问控制列表相关命令
ACL:Access Contorl List,实现灵活的权限管理。除了文件的所有者,所属组和其他人,可以对更多的用户设置权限
acl生效顺序
所有者,自定义用户,所属组|自定义组,其他人
acl相关命令
setfacl的用途
setfacl命令可以用来细分linux下的文件权限。
chmod命令可以把文件权限分为u,g,o三个组,而setfacl可以对每一个文件或目录设置更精确的文件权限。
换句话说,setfacl可以更精确的控制权限的分配。
比如:让某一个用户对某一个文件具有某种权限。这种独立于传统的u,g,o的rwx权限之外的具体权限设置叫ACL(Access Control List)
ACL可以针对单一用户、单一文件或目录来进行r,w,x的权限控制,对于需要特殊权限的使用状况有一定帮助。
如,某一个文件,不让单一的某个用户访问。setfacl的用法 --- 用法: setfacl [-bkndRLP] { -m|-M|-x|-X ... } file ... -m, --modify-acl 更改文件的访问控制列表 -M, --modify-file=file 从文件读取访问控制列表条目更改 -x, --remove=acl 根据文件中访问控制列表移除条目 -X, --remove-file=file 从文件读取访问控制列表条目并删除 -b, --remove-all 删除所有扩展访问控制列表条目 -k, --remove-default 移除默认访问控制列表 --set=acl 设定替换当前的文件访问控制列表 --set-file=file 从文件中读取访问控制列表条目设定 --mask 重新计算有效权限掩码 -n, --no-mask 不重新计算有效权限掩码 -d, --default 应用到默认访问控制列表的操作 -R, --recursive 递归操作子目录 -L, --logical 依照系统逻辑,跟随符号链接 -P, --physical 依照自然逻辑,不跟随符号链接 --restore=file 恢复访问控制列表,和“getfacl -R”作用相反 --test 测试模式,并不真正修改访问控制列表属性 -v, --version 显示版本并退出 -h, --help 显示本帮助信息
- 相关示例
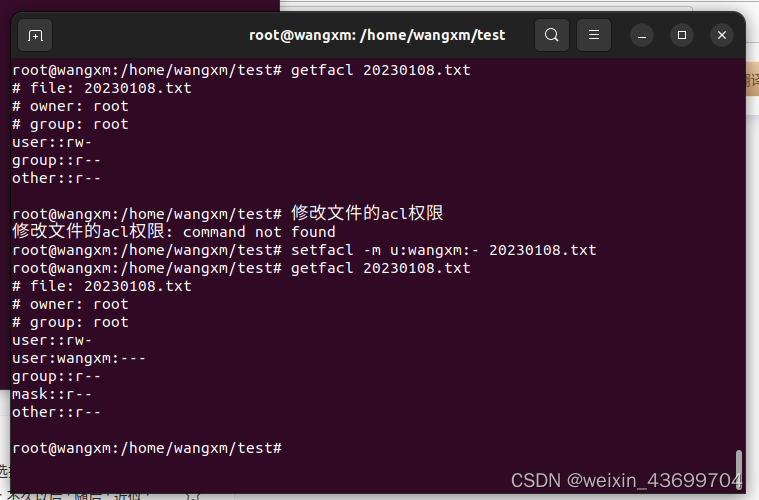
3. 结合vim几种模式,学会使用vim几个常见操作。
- 1)如何打开文件。并在打开文件(命令模式)之后如何退出文件。
vim [filename]或vim [path] [filename]再或者直接先进入相关路径后使用vim [filename]
- 2)打开文件(命令模式)之后,进入插入模式。并在插入模式中如何回到打开文件的状态(命令模式),并在命令模式之后如何退出文件。
- 进入到vim编辑器后按"i"即可进入插入模式,如果需要退出插入模式则只需要按"esc"键就可以了。在退出插入模式后如果想要退出则需要根据实际情况使用"!q"、“wq”、“q”
!q 不保存并强制退出 wq 保存后退出 q 在未修改任何信息的情况下使用,可以直接退出。
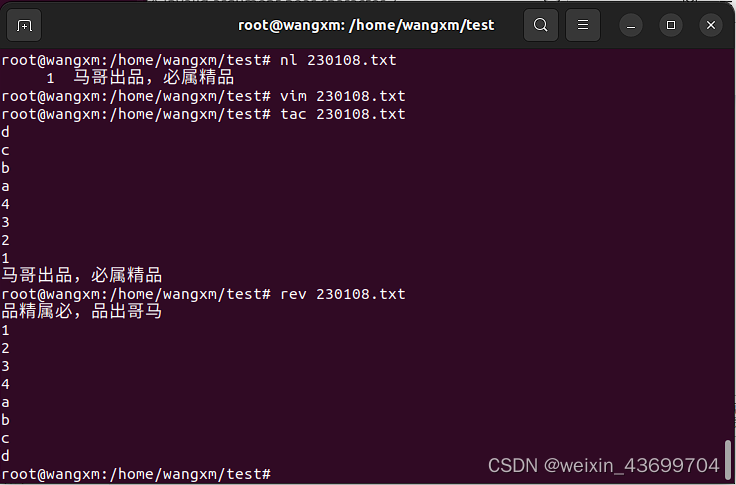
- 3)打开文件(命令模式)之后,进入插入模式,编写一段话,“马哥出品,必属精品”, 之后从插入模式中如何回到打开文件的状态(命令模式),并在命令模式之后如何退出文件。
- 新建并打开文件,(已在相关路径下)
vim 230108.txt
- 按"i"进入插入模式,输入"马哥出品,必属精品"后按"ESC"键退出插入模式到命令模式。
- 随后按照需要选择"!q"、“wq”、"q"退出即可
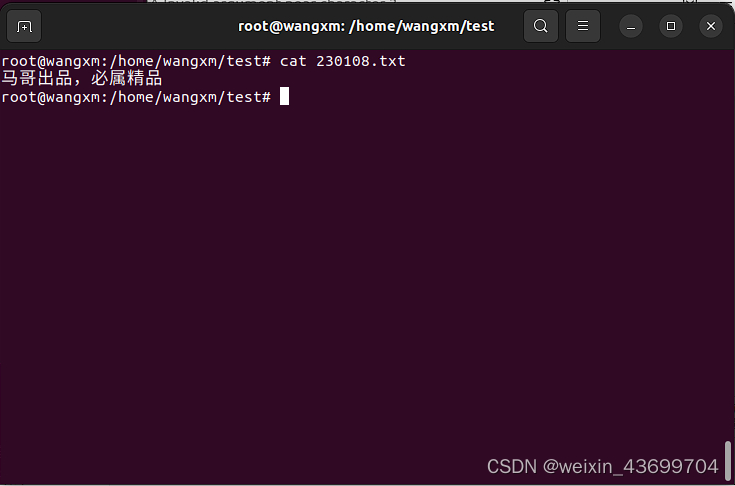
- 4)使用cat命令验证文件内容,是刚刚自己写的内容。
- 退出vim编辑器后,在相关目录下使用"cat 230108.txt"查看相关文件内的内容信息
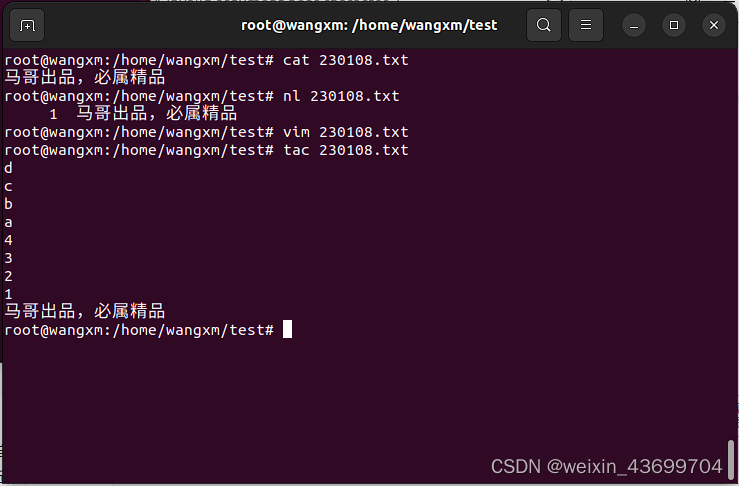
- 5)(可选),命令模式下,光标在单词,句子上进行前后,上下跳转。行复制粘贴。行删除。
4. 总结学过的文本处理工具,文件查找工具,文本处理三剑客, 文本格式化命令(printf)的相关命令及选项,示例。
查看文本文件内容
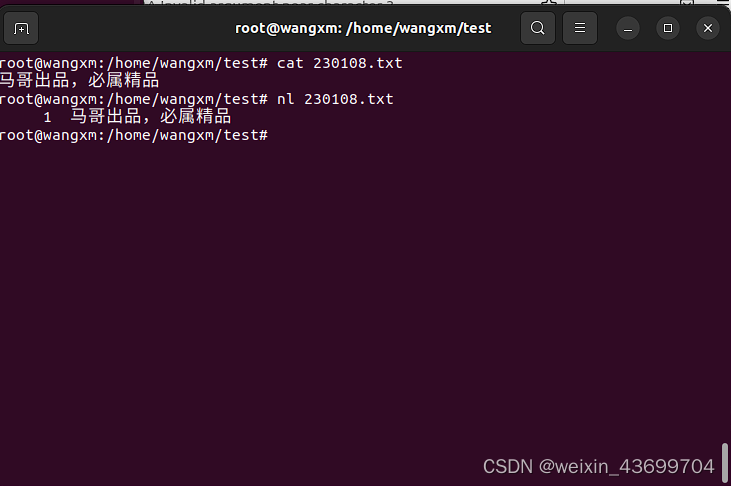
- cat可以查看文件内容
格式: cat [option]. . .[filename]. . . 常用选项: -E 显示行结束符$ -A 显示所有控制符 -n 对显示出的每一行进行编号 -b 非空行编号 -s 压缩连续的空行成一行
-
示例:
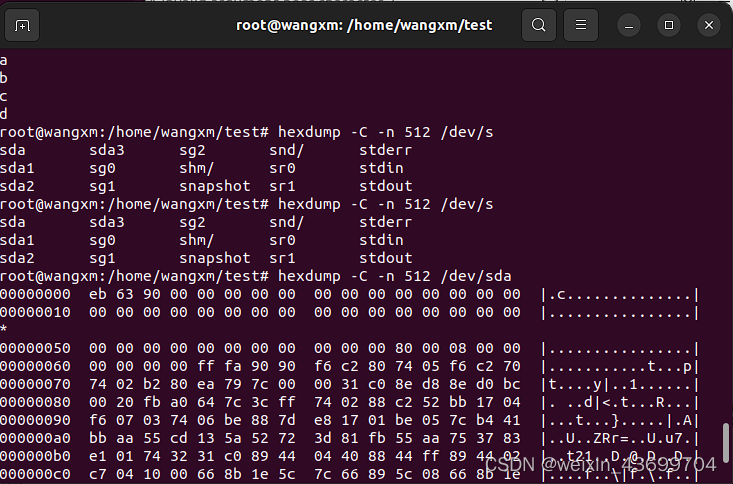
查看非文本文件内容
分页查看文件内容
- #### more
- 可以实现分页查看文件,可以配合管道实现输出信息的分页
-
格式:
more [option] [filename]
选项:
-d 显示翻页及退出提示
文本处理三剑客
grep [option] [pattern] [file]
-
常见选项
--color=auto 对匹配到文本进行着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,即取反
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q silent mode,不输出任何信息
-A # after,后#行
-B # before,前#行
-C # context,前后个#行
-e 实现多个选项间的逻辑or关系,比如:grep -e 'cat' -e 230108.txt file
-w 匹配整个单词
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-P 支持perl格式的正则表达式
-f file 根据模式文件处理
-r 递归目录,但是不处理软链接
-R 递归目录,但是处理软链接
-
示例:
sed
-
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下一行,执行下一个循环。如果没有使用诸如“D”的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非使用重定向存储输出或-i。
-
功能:主要用来自动编辑一个或多个文件,简化对文件的反复操作。
awk
awk 是一个处理文本的编程语言工具,能用简短的程序处理标准输入或文件、数据排序、计算以及
生成报表等等。
awk 处理的工作方式与数据库类似,支持对记录和字段处理,这也是 grep 和 sed 不能实现的。
在 awk 中,缺省的情况下将文本文件中的一行视为一个记录,逐行放到内存中处理,而将一行中的
某一部分作为记录中的一个字段。用 1,2,3…数字的方式顺序的表示行(记录)中的不同字段。用
$后跟数字,引用对应的字段,以逗号分隔,0 表示整个行。
5. 总结文本处理的grep命令相关的基本正则和扩展正则表达式。
基本正则
| 字符 | 描述 |
|---|---|
| ^ | ^word:搜索以word开头的内容 |
| $ | word$:搜索以word结尾的内容 |
| ^$ | 表示空行,不是空格 |
| . | 代表且只能代表任意一个字符(不匹配空行) |
| \ | 转义字符,让有特殊含义的字符脱掉马甲,现出原形,如.只表示小数点 |
| * | 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配 |
| .* | 任意长度的任意字符,不包括0次 |
| ^.* | 以任意多个字符串开头,.*尽可能多,有多少算多少 |
| [^abc] | 匹配不包含^后的任意字符a或b或c,是对[abc]的取反 |
| a{n,m} | 重复前面a字符至少n次,至多m次(如使用egrep或sed -r可去掉斜线) |
扩展正则
| 字符 | 描述 |
|---|---|
| + | 重复前一个字符一次或多次 |
| ? | 重复前一个字符0次或1次(.是有且只有1个) |
| 竖线(markdown写的,打不出来) | 表示或,查找多个字符串 |
| () | 分组过滤被括起来的东西表示一个整体(一个字符) |
6. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
命名要求
- 区分大小写
- 不能使程序中的保留字和内置变量:如:if, for
- 只能使用数字、字母及下划线,且不能以数字开头,注意:不支持短横线 “ - ”,和主机名相反
命名习惯
- 见名知义,用英文单词命名,并体现出实际作用,不要用简写,如:ATM
- 变量名大写
- 局部变量小写
- 函数名小写
- 大驼峰StudentFirstName,由多个单词组成,且每个单词的首字母是大写,其它小写
- 小驼峰studentFirstName ,由多个单词组成,第一个单词的首字母小写,后续每个单词的首字母是
- 大写,其它小写
- 下划线: student_name
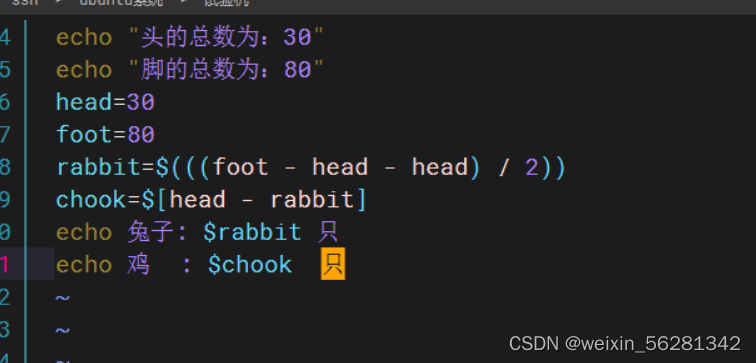
7. 通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?



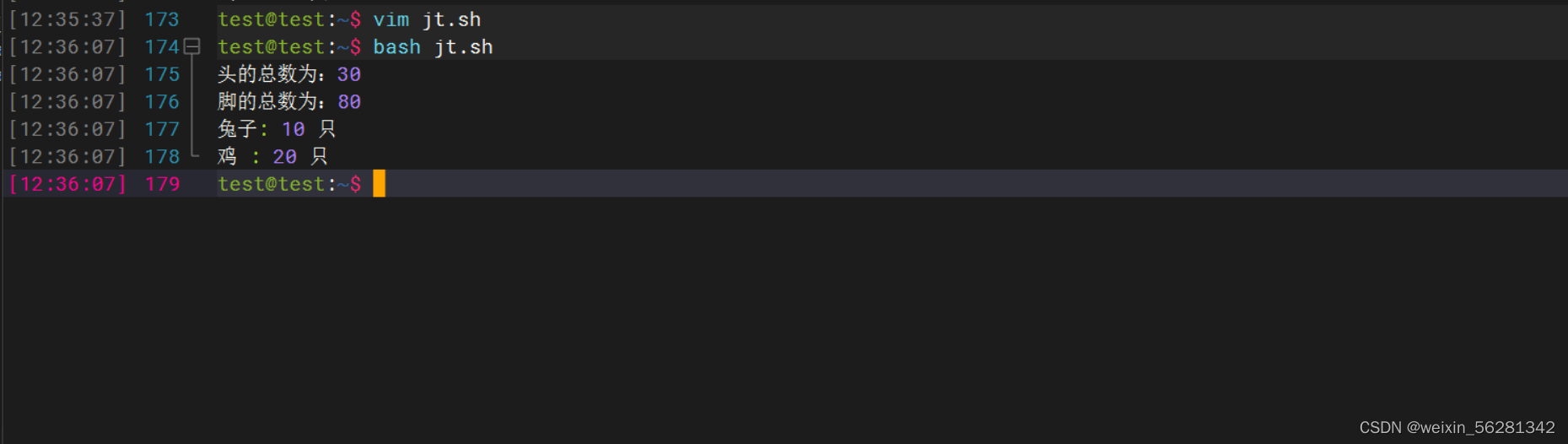
8. 结合编程的for循环,条件测试,条件组合,完成批量创建100个用户,
- 1)for遍历1…100
- 2)先id判断是否存在
- 3)用户存在则说明存在,用户不存在则添加用户并说明已添加。
9. 磁盘存储术语总结: head, track, sector, sylinder.
- 硬盘存储术语 CHS
head:磁头 磁头数=盘面数
track:磁道 磁道=柱面数
sector:扇区,512bytes
cylinder:柱面 1柱面=512 * sector数/trackhead数=51263*255=7.84M
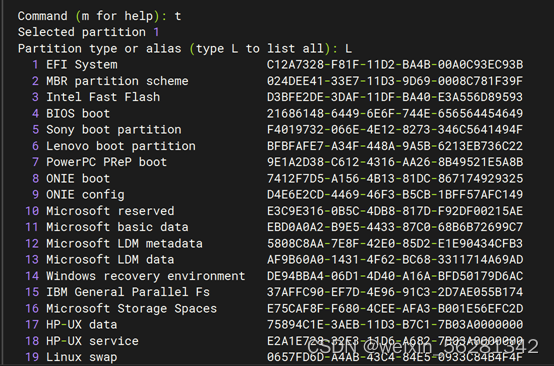
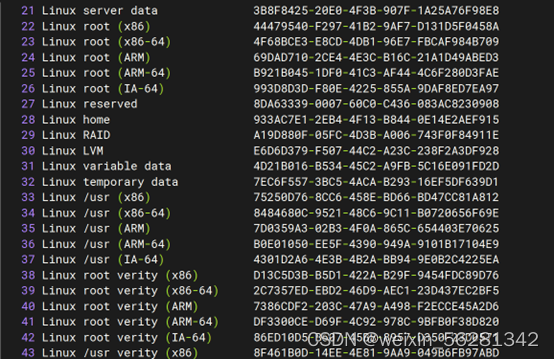
10. 总结MBR,GPT结构。
MBR
- MBR:Master Boot Record,1982年,使用32位表示扇区数,分区不超过2T
划分分区的单位:
CentOS 5 之前按整柱面划分
CentOS 6 版本后可以按Sector划分
0磁道0扇区:512bytes
446bytes: boot loader 启动相关
64bytes:分区表,其中每16bytes标识一个分区
2bytes: 55AA,标识位
MBR分区中一块硬盘最多有4个主分区,也可以3主分区+1扩展(N个逻辑分区)
MBR分区:主和扩展分区对应的1–4,/dev/sda3,逻辑分区从5开始,/dev/sda5
GPT分区
- GPT:GUID(Globals Unique Identifiers) partition table 支持128个分区,使用64位,支持8Z(
512Byte/block )64Z ( 4096Byte/block)
使用128位UUID(Universally Unique Identifier) 表示磁盘和分区 GPT分区表自动备份在头和尾两份,
并有CRC校验位
UEFI (Unified Extensible Firmware Interface 统一可扩展固件接口)硬件支持GPT,使得操作系统可以
启动
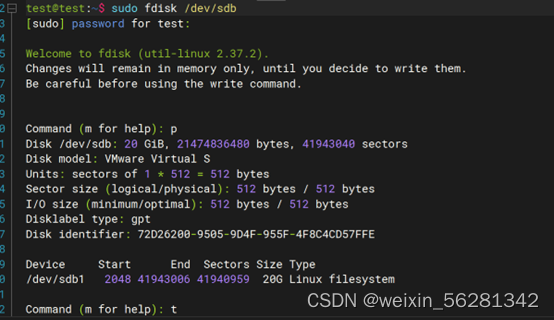
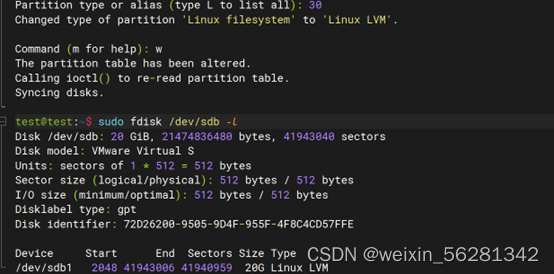
11. 总结学过的分区,文件系统管理,SWAP管理相关的命令及选项,示例fdisk, parted, mkfs, tune2fs, xfs_info, fsck, mount, umount, swapon, swapoff
12. 总结raid 0, 1, 5, 10, 01的工作原理。总结各自的利用率,冗余性,性能,至少几个硬盘实现。
RAID-0
- 以 chunk 单位,读写数据,因为读写时都可以并行处理,所以在所有的级别中,RAID 0的速度是最快的。
但是RAID 0既没有冗余功能,也不具备容错能力,如果一个磁盘(物理)损坏,所有数据都会丢失
读、写性能提升
可用空间:N*min(S1,S2,…)
无容错能力
最少磁盘数:1+
RAID-1
- 也称为镜像, 两组以上的N个磁盘相互作镜像,在一些多线程操作系统中能有很好的读取速度,理论上读
取速度等于硬盘数量的倍数,与RAID 0相同。另外写入速度有微小的降低。
读性能提升、写性能略有下降
可用空间:1*min(S1,S2,…)
磁盘利用率 50%
有冗余能力
最少磁盘数:2+
RAID-5
- RAID 5 是一种存储性能、数据安全和存储成本兼顾的存储解决方案。 RAID 5可以理解为是RAID 0和RAID 1的折中方案。RAID 5可以为系统提供数据安全保障,但保障程度要比Mirror低而磁盘空间利用率要比Mirror高。RAID 5具有和RAID 0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘空间利用率要比RAID 1高,存储成本相对较低,是运用较多的一种解决方案
读、写性能提升
可用空间:(N-1)*min(S1,S2,…)
有容错能力:允许最多1块磁盘损坏
最少磁盘数:3, 3+
Raid 10
- 是一个Raid 1与Raid0的组合体,它是利用奇偶校验实现条带集镜像,所以它继承了Raid0的快速和Raid1的安全。我们知道,RAID 1在这里就是一个冗余的备份阵列,而RAID 0则负责数据的读写阵列。其实,概述图只是一种RAID 10方式,更多的情况是从主通路分出两路,做Striping操作,即把数据分割,而这分出来的每一路则再分两路,做Mirroring操作,即互做镜像。
读、写性能提升
可用空间:N*min(S1,S2,…)/2
有容错能力:每组镜像最多只能坏一块
最少磁盘数:4, 4+
RAID-0+1
-
RAID 0+1的特点使其特别适用于既有大量数据需要存取,同时又对数据安全性要求严格的领域,如银行、金融、商业超市、仓储库房、各种档案管理等。正如其名字一样RAID 0+1是RAID 0和RAID 1的组合形式,也称为RAID 01。
-
以四个磁盘组成的RAID 0+1为例,其数据存储方式如图所示:RAID 0+1是存储性能和数据安全兼顾的方案。它在提供与RAID 1一样的数据安全保障的同时,也提供了与RAID 0近似的存储性能。
由于RAID 0+1也通过数据的100%备份功能提供数据安全保障,因此RAID 0+1的磁盘空间利用率与RAID 1相同,存储成本高。
读、写性能提升
可用空间:N*min(S1,S2,…)/2
有容错能力:每组镜像最多只能坏一块
最少磁盘数:4, 4+
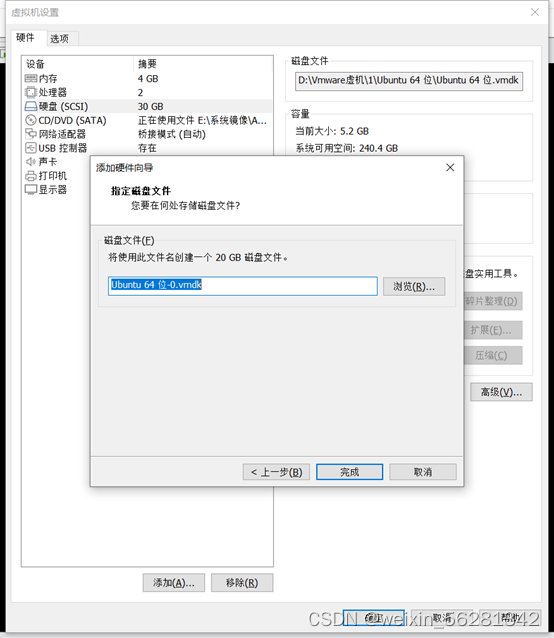
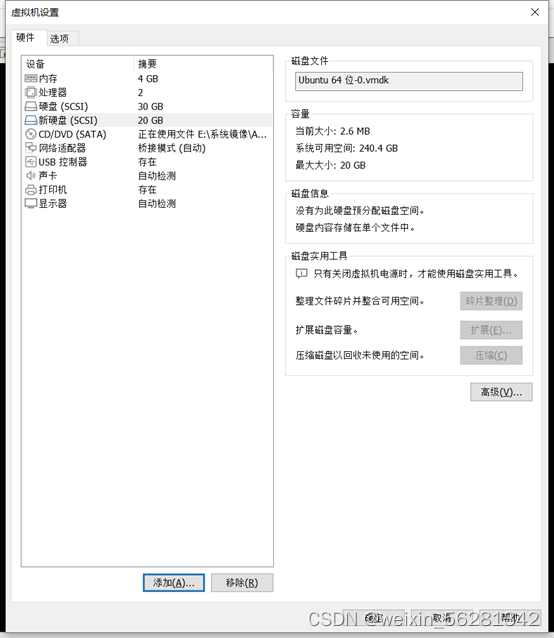
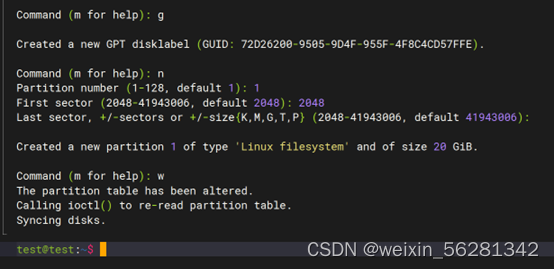
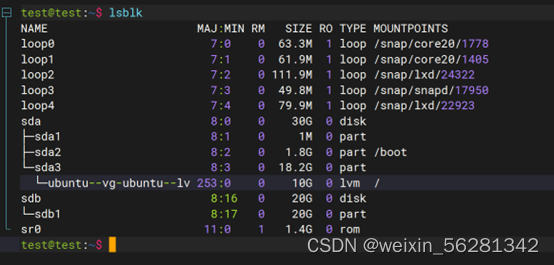
13. 完成不影响业务对LVM磁盘扩容及缩容示例。
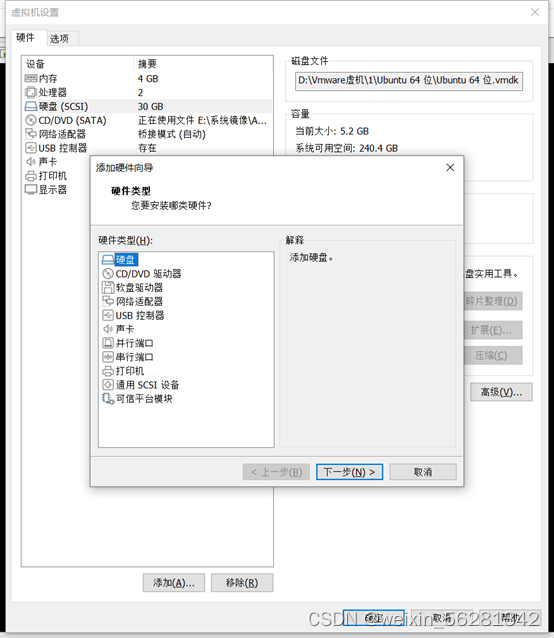
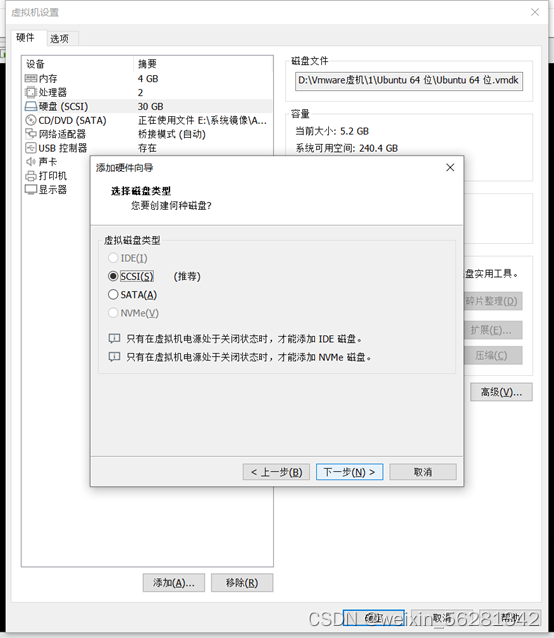
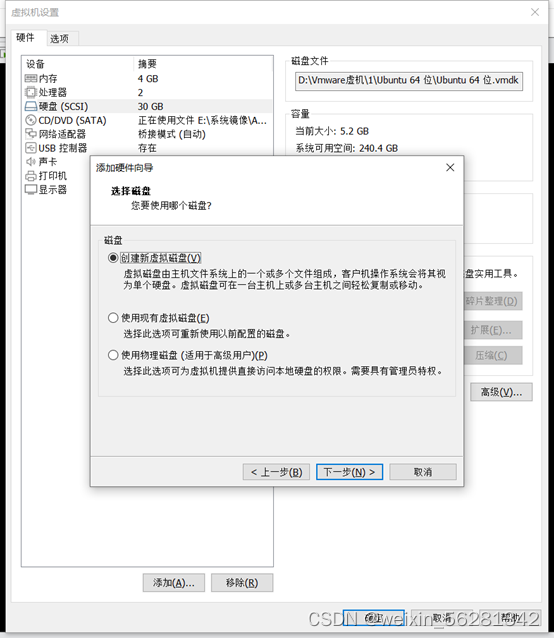
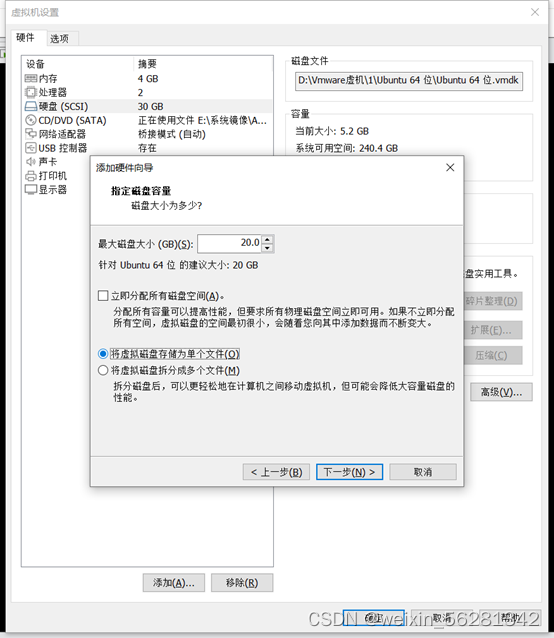















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









