







部署完了接下来尝试微调的工作
一.准备训练的语料数据
BelleGroup 是一个由中国深圳大学(SZU)的研究团队发起的开源项目,里面有不少中文的语料数据集,这次选用的就是其中一个有50w条中文数据的数据集
数据集的结构
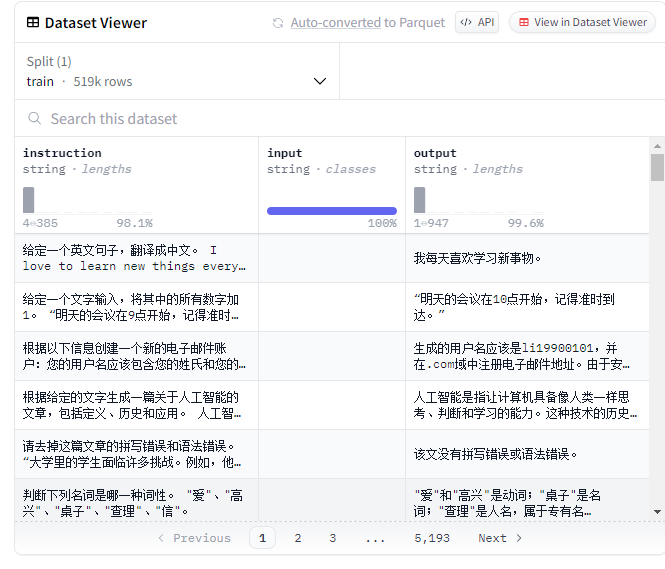
1.下载
用wget下载这个json文件,记得cd到你需要保存的目录下面,或者在命令行里加上你的目标路径
wget https://huggingface.co/datasets/BelleGroup/train_0.5M_CN/main/Belle_open_source_0.5M.json2.拆分测试集
新建一个文件:split_json.py,然后把下面的代码粘贴进去
import random,json
def write_txt(file_path,datas):
with open(file_path,"w",encoding="utf8") as f:
for d in datas:
f.write(json.dumps(d,ensure_ascii=False)+"\n")
f.close()
with open("Belle_open_source_0.5M.json","r",encoding="utf8") as f:
lines=f.readlines()
#拼接数据
changed_data=[]
for l in lines:
l=json.loads(l)
changed_data.append({"text":"### Human: "+l["instruction"]+" ### Assistant: "+l["output"]})
#从拼好后的数据中,随机选出1000条,作为训练数据
#为了演示使用,我们只用1000条,生产环境至少要使用全部50w条
r_changed_data=random.sample(changed_data, 1000)
#写到json中
write_txt("Belle_open_source_0.5M_changed_test.json",r_changed_data)我这里直接把数据和split_json.py存放在同一个目录下了,记得修改自己的路径
然后运行这个文件,生成Belle_open_source_0.5M_changed_test.json
二.进行微调训练
1.在服务器上创建jupyter notebook
这一步如果是租的服务器应该挺简单,可以直接用提供的接口
如果是像我这样用实验室服务器的小穷鬼
先在远程服务器启动jupyter notebook,没装的先install一下
这里很幽默的一点是实验室的服务器直接运行jupyter notebook是无法运行的,必须要从python -m notebook的jupyter notebook接口进入才可以
原因是我的虚拟环境里有,但是整个账户的环境变量里没设定好,多人多个不同的虚拟环境,比较混乱吧。尝试想修改一下虚拟环境,但是进去一片屎山,算了~
启动以后会显示jupyter notebook的前端端口号,比如我这里是8890
然后启动ssh隧道
ssh -L notebook的端口:localhost:notebook的端口 用户名@服务器ip -p 服务器端口接下来打开网址
又遇到问题了
不知道谁给服务器的notebook设定了password,且没有token
参考了csdn上很多解决的办法都不太能成功
包括修改密码、取消密码登录、删除token等
最后用重新生成config的办法简单粗暴的完成了。。。。
好了现在终于进入服务器的notebook了
接下来把我的虚拟环境加入到ipykernel里面
python -m ipykernel install --user --name=xx --display-name="Python (xx)"能在右上角看见自己的虚拟环境就是kernel搞成功了
2.微调的代码
这里的代码参考了其他大佬的csdn
①装库
!pip install -q huggingface_hub
!pip install -q -U trl transformers accelerate peft
!pip install -q -U datasets bitsandbytes einops wandb②登陆hugging face的notebook
from huggingface_hub import notebook_login
notebook_login()把https://huggingface.co/settings/tokens的token加进入
(需要服务器能上hugging face)
然后我们实验室的就不能上哈哈。。
方法一,可以尝试启动学术加速
参考博客:学术资源加速-CSDN博客
*账户没有管理员权限,写不了etc下的内容,pass
方法二,在本地重新创一个进行训练部分
*配了半天环境,本地配的乱七八糟,pass
方法三,回到第一行,租一个云服务器,
*舍不得花钱,pass
眼看我要彻底失败了,
然后我就在想,为什么要连huggingface,这段代码的作用是什么
wandb的作用是实时可视化记录loss数据
huggingface呢?查看源码好像也没用到这部分的东西
这个可能主要是方便访问huggingface hub上的私有模型或者其他受保护的一些资源
但是我这个模型,就在本地啊?数据也在本地,包括transformers accelerate peft,这些我都install上了
理论上来说我并不需要这个login吧?
于是我就头贴直接往下运行了
事实证明,确实能继续训练昂。
继续,
③配置wandb
注册,并在Weights & Biases复制出自己的key
import wandb
wandb.init()输入进去
④导入相关包和数据集
from datasets import load_dataset
import torch,einops
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer, TrainingArguments
from peft import LoraConfig
from trl import SFTTrainer
dataset = load_dataset("json",data_files="Belle_open_source_0.5M_changed_test.json",split="train")⑤配置模型
base_model_name ="/model/FlagAlpha_Llama2-Chinese-7b-Chat"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,#在4bit上,进行量化
bnb_4bit_use_double_quant=True,# 嵌套量化,每个参数可以多节省0.4位
bnb_4bit_quant_type="nf4",#NF4(normalized float)
bnb_4bit_compute_dtype=torch.float16,
)⑥配置GPU
device_map = {"": 0}
#有多个gpu时,为:device_map = {"": [0,1,2,3……]}⑦加载模型
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,#本地模型名称
quantization_config=bnb_config,#上面本地模型的配置
device_map=device_map,#使用GPU的编号
trust_remote_code=True,
use_auth_token=True
)
base_model.config.use_cache = False
base_model.config.pretraining_tp = 1⑧配置QLoRA
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)⑨token分词器
tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token⑩配置训练参数
output_dir = "./results"
training_args = TrainingArguments(
report_to="wandb",
output_dir=output_dir,#训练后输出目录
per_device_train_batch_size=4,#每个GPU的批处理数据量
gradient_accumulation_steps=4,#在执行反向传播/更新过程之前,要累积其梯度的更新步骤数
learning_rate=2e-4,#超参、初始学习率。太大模型不稳定,太小则模型不能收敛
logging_steps=10,#两个日志记录之间的更新步骤数
max_steps=100#要执行的训练步骤总数
)
max_seq_length = 512
#TrainingArguments 的参数详解:https://blog.csdn.net/qq_33293040/article/details/117376382
trainer = SFTTrainer(
model=base_model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_args,
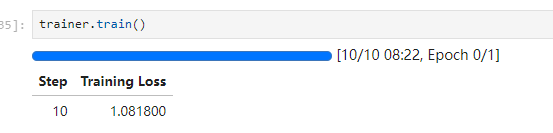
)11、开始训练
trainer.train()顺利的话,可以用wandb看见训练的loss,前面的max_step是训练的总论次,logging_step是能看见的loss的间隔
不顺利的话。。
你就会像我一样,获得两种错误
错误一:OutOfMemory
这个报错很好理解,GPU部署在0上,内存不够,因为服务器还有其他同学在用。
遇到这个问题,可以等别人不做实验了再尝试,或者调整一下LoRA的参数,batch和反馈深度等
具体参数的含义,后面再学吧。
尝试参数修改,还是内存不够,又不想等别人,怎么办呢,我有另一个想法
查看nvidia-smi,GPU2、3、4其实没什么人用,我想部署到2上
device_map = {"": 2}于是我尝试修改⑥,
但是这样我以为是在GPU:2上部署,但是并不是呢,是部署在0,1,2上的意思
一时之间我居然想不到怎么单独部署在GPU2上
ps,注释的这种写多个GPU的方式语法错误
接着我遇到了错误二:ValueError: You can't train a model that has been loaded in 8-bit precision on multiple devices.
尝试部署多GPU居然也会报错
我把这段报错搜索栏一下发现,仓库里也有人提交了这个问题:
https://github.com/huggingface/accelerate/issues/1515
peft遇到在最新版本的 transformers 库中,无法将以 8-bit 精度加载的模型在多 GPU 上分布
开发者 younesbelkada 回应,他解释称原生管道并行(Naive Pipeline Parallelism, NPP)不应该在分布式设置下使用,因为 NPP 本质上是顺序的,理应仅通过单一 Python 进程运行
接着我又用我蹩脚的英文一直看几个人的对话
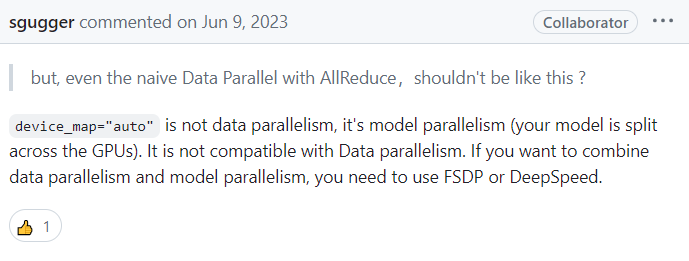
诶给我找到一个,device_map="auto".这个好啊,自动帮我找剩余内存最大的GPU
重启尝试了一下,果然可以运行
*作者的回复里应该是有更好的用多GPU的办法的,有看懂的小伙伴可以分享一下

Anyway,开始运行了
训练结束
(前面参数写的是step=100,在减少内存消耗的时候我把这里改成10了,效果肯定没100的好,但是我的目标只是把整个部署的流程顺一遍,所以这样做了
12、保存训练模型
import os
output_dir = os.path.join(output_dir, "final_checkpoint")
trainer.model.save_pretrained(output_dir)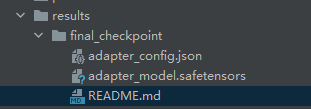
save完成
*safetensors 是一种新的张量存储格式,旨在安全、快速地存储和加载大规模的机器学习模型参数。与传统的 PyTorch .pt 或 .bin 文件格式相比,safetensors 提供了一些显著的优势:
主要特点
- 安全性:safetensors 格式通过设计避免了执行任意代码的风险,确保了文件的安全性。这对于共享和分发模型文件尤其重要。
- 速度:这种格式经过优化,可以快速地存储和加载张量数据。这对于大规模模型来说,加载时间的减少非常显著。
- 兼容性:safetensors 与现有的 PyTorch 等框架兼容,支持直接加载到这些框架中。
这个就是存储下来的最优模型
嗯,一开始以为没有存下来呢,之前的项目都是存xxx.pt的,时代果然在进化,学习永远在路上昂
三、模型合并
恭喜恭喜,很快就能over了
1、新建一个merge_model.py的文件,把下面的代码粘贴进去:
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import os
# 设置原来本地模型的地址
model_name_or_path = '/home/camp/wsqllm/model/Llama2-Chinese-7b-Chat'
# 设置微调获得模型的地址
adapter_name_or_path = '/home/camp/wsqllm/results/final_checkpoint'
# 设置合并后模型的导出地址
save_path = '/home/camp/wsqllm/model/newmodel'
# 确保保存路径存在
os.makedirs(save_path, exist_ok=True)
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map='auto'
)
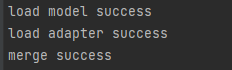
print("Load model success")
model = PeftModel.from_pretrained(model, adapter_name_or_path)
print("Load adapter success")
model = model.merge_and_unload()
print("Merge success")
# 更新生成配置
if model.generation_config.do_sample is False:
if hasattr(model.generation_config, 'temperature'):
model.generation_config.temperature = None
if hasattr(model.generation_config, 'top_p'):
model.generation_config.top_p = None
tokenizer.save_pretrained(save_path)
model.save_pretrained(save_path)
print(f"Model and tokenizer saved to {save_path}")
这个文件在把之前原始模型参数和微调后的参数进行合并
四、gradio可视化
和上一篇一样,打开gradio的可视化前端
python gradio_demo.py --base_model /home/camp/wsqllm/model/newmodel --tokenizer_path /home/camp/wsqllm/model/newmodel --gpus 4部署在几请根据自己的来,本人一开始默认复制了大佬的指令,gpu0喜提。。

建立ssh隧道,这里不再次重复了,看gradio的端口号是什么然后修改之前的那个就可以
当然,这里的微调,其实可视化的时候也看不太出来是不是真的是微调成功的,还是说原模型语料库里面可能就已经调教完成了,选了一个test里面的语句尝试了一下
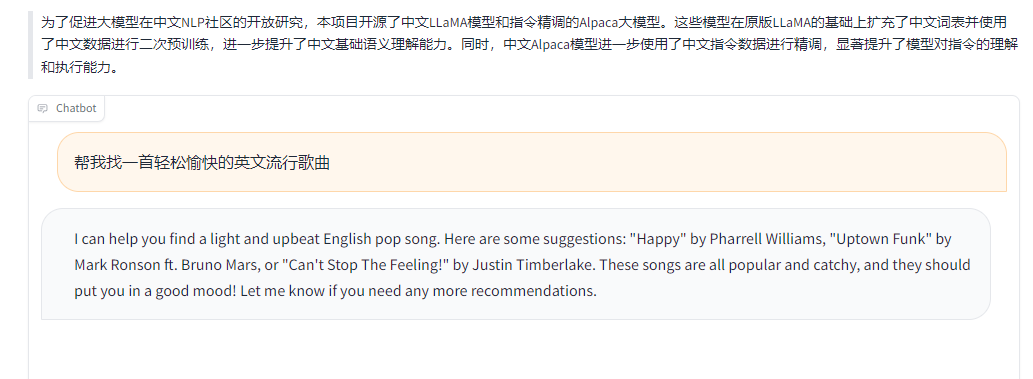

好消息,和测试集的语料回答的一样,坏消息,英文回答的
可能是因为prompt里面有英文二字吧
比较好能观察的方法是自己设定一个训练的语料库,比如写一些特定领域的数据集之类的,之后也可以在网上搜索一下有无此类的公开数据集
maybe
明天继续langchain
赶紧实操完然后看面经然后找实习啊啊啊















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









