






yolov5整体结构可以分成backbone(骨干网),neck(颈部),head(检测头)三个部分,其中在yolov5.yaml配置文件中neck和head写在了一个部分。
backbone:进行特征提取。常用的骨干网络有VGG,ResNet,DenseNet,MobileNet,EfficientNet,CSPDarknet 53,Swin Transformer等。(其中yolov5s采用CSPDarknet 53作为骨干网)应用到不同场景时,可以对模型进行微调,使其更适用于特定的场景。
neck:neck的设计是为了更好的利用backbone提取的特征,在不同阶段对backbone提取的特征图进行在加工和合理利用。常用的结构有FPN,PANet,NAS-FPN,BiFPN,ASFF,SFAM等。(其中yolov5采用PAN结构)共同点是反复使用各种上下采样,拼接,点和和点积来设计聚合策略。
Head:骨干网作为一个分类网络,无法完成定位任务,Head通过骨干网提取的特征图来检测目标的位置和类别。
再说PANet之前就得说到FPN,这应该也是看文献中反复会提到的一个词语---特征金字塔
(一)特征金字塔(Feature Pyramid Network, FPN)
总所周知,图像中存在不同尺寸的目标,不同的目标具有不用的特征。其中浅层特征更关注细节信息,对目标的定位十分关键。而深层特征更关注语义信息,对目标对象的分类十分重要。大多数通用检测器只采用末层输出进行检测,其中包含丰富的语义信息却忽略其他层的特征。(如SSD)
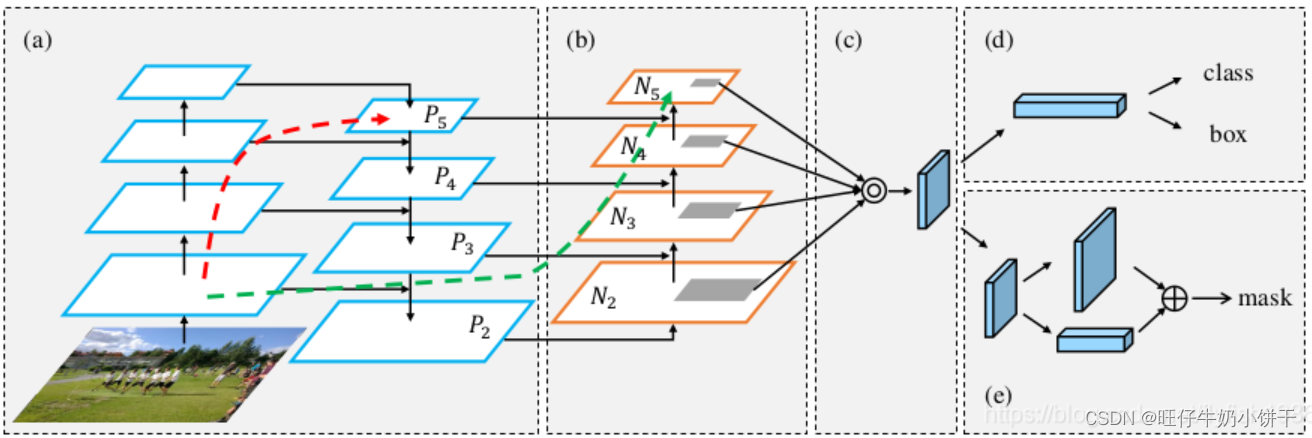
为了利用多层特征信息,有研究者提出图像金字塔,在图像金字塔的每一层所提出的不同特征,分别进行相应的预测。尽管精度上有一定的提升,但计算量大,需要大量的内存,并且这个点经常会成为整个网络模型优化的瓶颈,所以一般不会采用这个方法。

为了改进图像金字塔,有研究者提出减少预测的特征图,同时利用高层和低层特征进行预测(在不同的层级上)。在一定程度上不同层级对应不同输出,加速了运算,但是!所获得的特征不具有鲁棒性,都是一些弱特征(毕竟没有经过那么多网络的“筛选”)。
为解决上述问题,特征金字塔能够在速度和准确率之间进行权衡,获得更加鲁棒的语义信息!

首先对输入图像进行深度卷积,然后对2上面的特征进行降维操作(即添加一个1*1的卷积层)然后对4上的特征进行上采样使得其具有相同的尺寸,然后对于处理好的2,4进行加法操作,将获得的结果输入到5中,以此获得更强的语义信息。(其中1-3为bottom-up,4-6为top-down)
FPN可以很好处理小目标的原因:
1.FPN可以利用经过top-down模块后的那些上下文信息(高层语义信息)。
2.对于小目标而言,FPN增加了特征映射的分辨率。(即在更大的Feature map上操作,可以获得更多关于小目标的信息)
(二)路径聚合网络(Path Aggregation Network,PANet)
相较于FPN的改进点如下:
1.提出一个自顶向下和自顶向上的双向融合骨干网络 2.在最底层和最高层之间添加了一条“short cut”用于缩短层之间的路径 3.为恢复每个建议区域和所有特征层级之间被破坏的关系,提出自适应特征池化(adaptive feature pooling ) 4.全连接融合层:使用一个小型FC层用于补充mask预测
在FPN中,依据候选框区域大小分配不同特征层次,小的分配到low-level,大的分配到high-level。所以提出池化来自所有层的特征,然后融合他们做预测。---自适应特征池化
(三)Bidirectional Feature Pyramid Network 加权双向(自顶向下 + 自低向上)特征金字塔网络
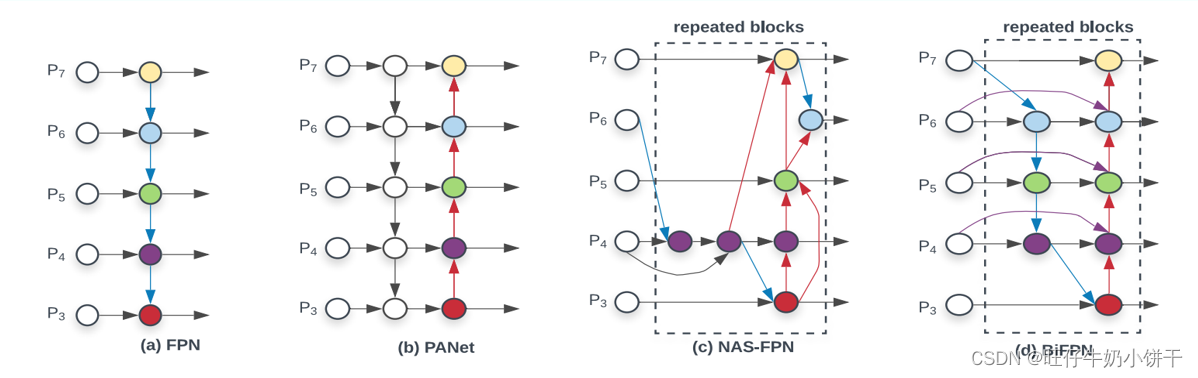
与PAN相比改进点:
增加残差链接:通过简单的残差操作,增强特征的表示能力(紫色路线)
移除单输入边的结点:因为但输入边的结点没有进行特征融合,故具有的信息比较少,对于最后的融合没有什么贡献度,相反,移除还能减少计算量。
权值融合:简单来说,就是针对融合的各个尺度特征增加一个权重,调节每个尺度的贡献度,其中,做个提出了Fast-softmax,提高检测速度。其实就是注意力机制与FPN的碰撞。
BiFPN = 加强版的PANet(重复双向跨尺度连接) + 带权重的特征融合机制
yolov5采用PAN作为颈部网络
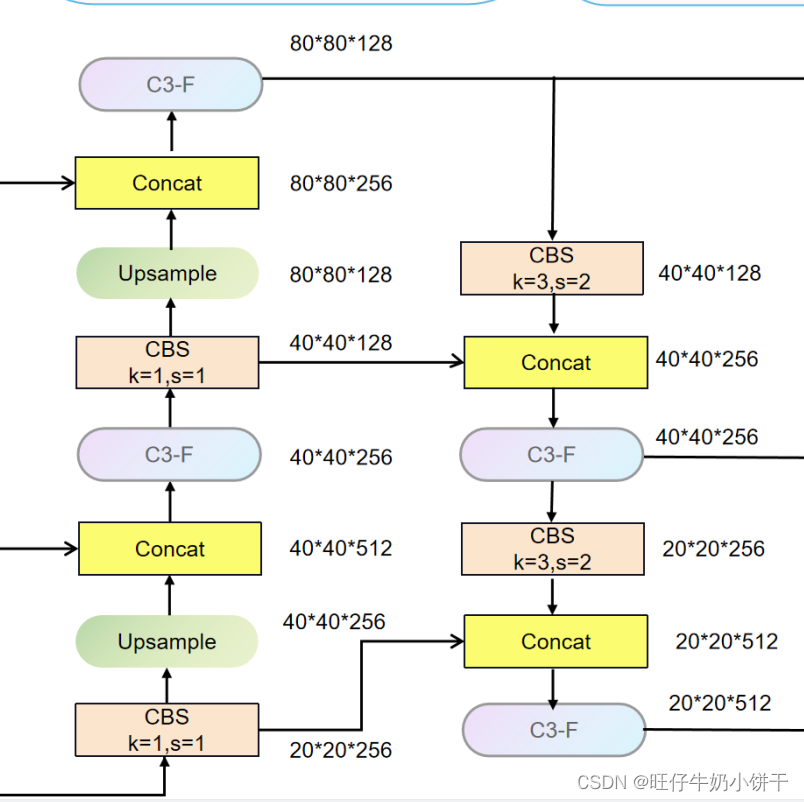
其中C3模块换成了不带有残差连接的模块,因为认为在neck部分不需要再一味的加深网络。通过上采样(upsample)来调整特征图的尺寸方便进行拼接操作。针对yolov5neck部分改进也有很多,比如替换PAN为BiFPN,ASFF等。不同应用场景效果不同!
总之还有好多好多要学习的....慢慢来吧!加油!
















 2996
2996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











