







搜索和排序
搜索
搜索从元素中找到某个特定元素的算法过程,通常返回True或False分别表示元素是否存在,有时可以修改搜索过程,使其返回目标元素的位置。
顺序搜索
存储与列表等结合中数据项彼此存在线性或顺序的关系,每个数据项的位置与其他数据项相关。
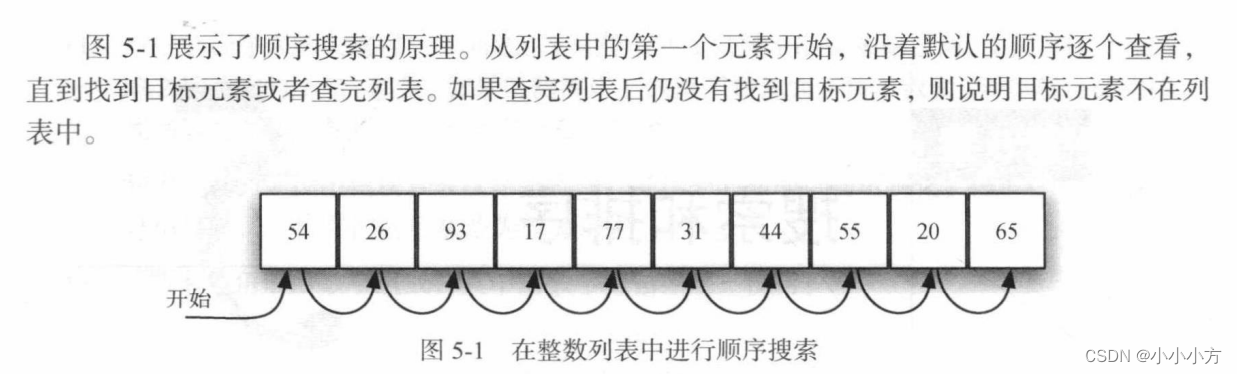

# 无序列表的顺序搜索
def sequentialSearch(alist,item):
pos = 0
found = False
while pos < len(alist) and not found:
if alist[pos] == item:
found = True
else:
pos = pos + 1
return found


# 有序列表的顺序删除
def orderedSequentialSearch(alist,item):
pos = 0
found = False
stop = False
while pos < len(alist) and not found and not stop:
if alist[pos] == item:
found = True
else:
if alist[pos]>item:
stop = True
else:
pos = pos +1
return found
二分搜索
二分搜索不是从第一个元素开始搜索泪飙,而是从中间的元素着手。如果这个元素是目标元素就立即停止搜索,如果不是就可以利用列表有序的属性,排除一半的元素,针对另一半重复二分过程。
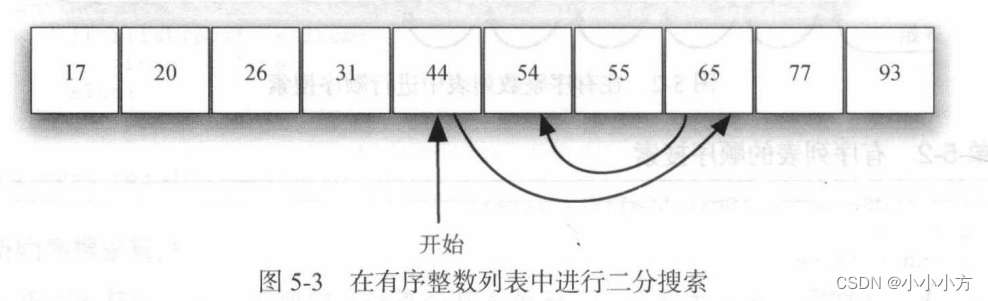
# 有序列表的二分搜索
def binarySearch(alist,item):
first = 0
last = len(alist) -1
found = False
while first <= last and not found:
midpoint = (first + last)//2
if midpoint == item:
found = True
else:
if item < alist[midpoint]:
last = midpoint-1
else:
first =midpoint +1
return found
# 二分搜索的递归版本
def binarySearch(alist,item):
if len(alist) == 0:
return False
else:
midpoint = len(alist) //2
if alist[midpoint] == item:
return True
else:
if item < alist[midpoint]:
return binarySearch(alist[:midpoint],item)
else:
return binarySearch(alist[midpoint+1:],item)

二分搜索通常优于顺序搜索,但当n较小时,排序引起的额外开销可能并不划算,具体问题视情况而定。
散列
使用散列构建一个时间复杂度为O(1)的数据结构。如果每个元素都在它该在的位置上,那么搜说算法只需要比较一次。散列表是元素集合,其中的元素以一种便于查找的方式存储。散列表中的每个我i欸之被称为槽,其中可以存储一个元素。槽用一个从0开始的整数标记。初始情况下,散列表中没有元素,每个槽都是空的,可以用列表来实现散列表,并将每个元素都初始化为None。
散列函数i将散列表中的元素与其位置对应起来,对散列表中的任一元素,散列函数返回介于0和m-1之间的整数。
第一个散列函数也称为取余函数。计算出散列值后,将每个元素插入到相应的位置,槽的咱用来被称为载荷因子。
因为计算散列值并找到相应位置所需的时间是固定的,所以搜索操作的时间复杂度是O(1)。
散列函数会将两个元素都放入一个槽,称为冲突。
散列函数
给定一个元素集合,将每个元素映射到不同的槽,称为完美散列函数。目标是创建一个冲突数最少的散列函数。
折叠法
将元素切成等长的部分,然后将这些部分相加,得到散列值。

平方取中法:先将元素取平方,然后提取中间几位数。

# 为字符串构建简单的散列函数
def hash(astring,tablesize):
sum = 0
for pos in range(len(astring)):
sum = sum + ord(astring[pos])
return sum%tablesize

针对异序词,散列函数总是得到相同的散列值,可以使用字符位置作为权重因子。
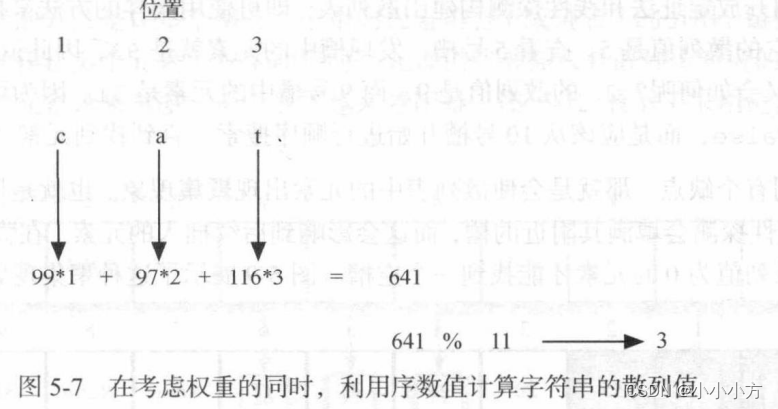
处理冲突
当两个元素被分到一个槽中时,必须通过一种系统化的方法在散列表中安置第二个元素,这个过程被称为处理冲突。
一种方法是在散列表中找到另一个空槽,用于放置引起冲突的元素,简单的做法是从起初的散列值开始,顺序的遍历散列表,直到找到一个空槽。为了遍历散列表,可能需要往回检查第一个槽,这个过程被称为开放定址法,舱室在散列表中需按照下一个空槽或地址,逐个的访问槽,称为线性探测。
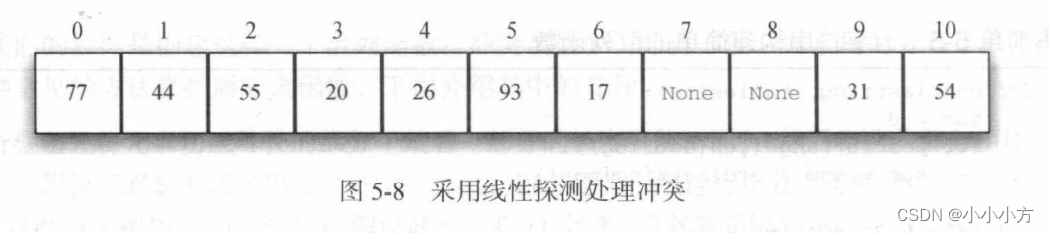
线性探测有个缺点,会使散列表中的元素出现聚集现象,一个槽发生太多冲突,线性探测会填满附近的槽,这会影响后续插入的元素。
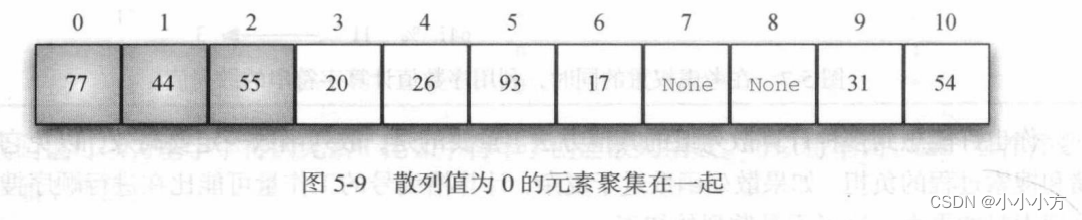
要避免元素聚集,一种方法是扩展线性探测,不再一次顺序查找空槽,而是跳过一些槽,这样的做法能使引起冲突的元素分布更加均匀。
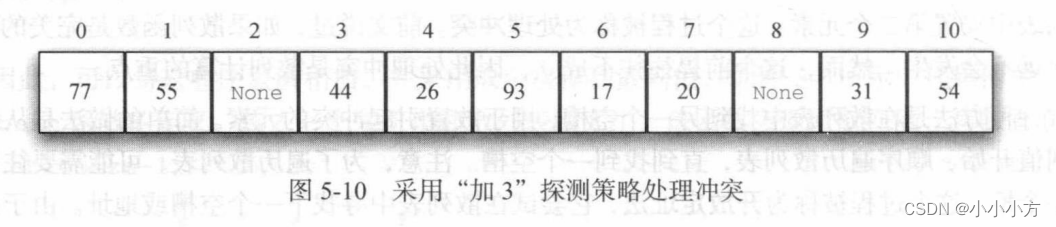
在散列是值在发生冲突后寻找另一个槽的过程。将散列哈桑农户定义为rehash(pos)=(pos+skip)%sizeoftable。跨步的大小时能保证表中所有的槽都能被访问到,否则就会浪费资源,要保证这一点,常常建议散列表的大小为素数。
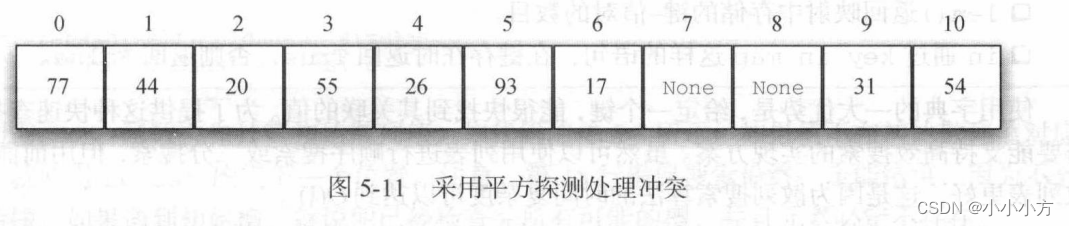
平方探测是线性探测的一个变体,它不采用固定的跨步大小,而是通过再散列函数递增散列值。如果第一个散列值是h,后续的散列值就是h+1,h+4,h+9,h+16等。平方探测的跨步大小是一系列的完全平方数。
链接法是让每个槽由一个指向元素集合的引用,允许散列表中同一个位置上存在多个元素。
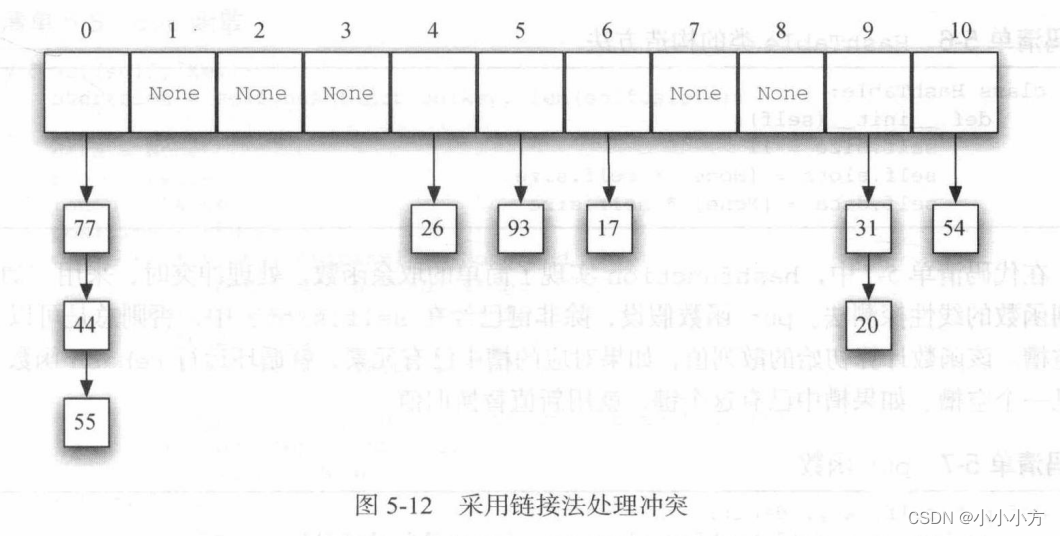
搜索目标元素时,用散列函数算出它对应的槽编号,由于每个槽都有一个元素集合,因此需要再搜索一次才能直到目标元素是否存在。
抽象数据类型
Map()创建一个空的映射,返回一个空的映射集合。
put(key,val)往映射中加入一个新的键-值对。如果键已经存在就用新值替换旧值。
get(key)返回key对应的值,如果key不存在就返回None。
del map[key]从映射中删除键值对
len()返回映射中存储的键值对的数目
# hashTable类的构造方法
class HashTable:
def __init__(self):
self.size = 11
self.slots = [None] * self.size
self.data = [None] * self.size
# put哈函数
def put(self, key, data):
# 得到哈希值
hashvalue = self.hashfunction(key, len(self.slots))
# 位置为None,则直接赋值
if self.slots[hashvalue] == None:
self.slots[hashvalue] = key
self.data[hashvalue] = data
# 如果不为None
else:
# 如果键相等用新值替换旧值
if self.slots[hashvalue] == key:
self.data[hashvalue] = data
# 不相等则重新查找位置
else:
nextslot = self.rehash(hashvalue, len(self.slots))
# 直到找到一个空位置为止
while self.slots[nextslot] != None and self.slots[nextslot] != key:
nextslot = self.rehash(nextslot, len(self.slots))
# 如果是空位置则直接赋值
if self.slots[nextslot] == None:
self.slots[nextslot] = key
self.data[nextslot] = data
# 如果是相同键值则直接替换
else:
self.data[nextslot] = data
# 取余的哈希函数
def hashfunction(self, key, size):
return key % size
# 重新定位函数
def rehash(self, oldhash, size):
return (oldhash + 1) % size
# get函数
def get(self, key):
# 得到第一次的键值
startslot = self.hashfunction(key, len(self.slots))
data = None
stop = False
found = False
# 起始位置
position = startslot
while self.slots[position] != None and not found and not stop:
# 如果连两个键值相等则找到
if self.slots[position] == key:
found = True
data = self.data[position]
# 如果不相等
else:
# 在起始位置查找下一个可能的位置
position = self.rehash(position, len(self.slots))
# 如果回到起始槽 则说明已经检查完了所有可能的槽,元素必定不存在
if position == startslot:
stop = True
return data
# 提供字典功能,可以使用索引运算符
def __getitem__(self, key):
return self.get(key)
def __setitem__(self, key, data):
self.put(key, data)
H = HashTable()
H[54] = "cat"
H[26] = "dog"
H[93] = "lion"
H[17] = "tiger"
H[77] = "bird"
H[31] = "cow"
H[44] = "goat"
H[55] = "pig"
H[20] = "chicken"
print(H.slots)
print(H.data)
print(H[20])
print(H[17])
H[20]='duck'
print(H[20])
print(H[99])
运行结果:
[77, 44, 55, 20, 26, 93, 17, None, None, 31, 54]
['bird', 'goat', 'pig', 'chicken', 'dog', 'lion', 'tiger', None, None, 'cow', 'cat']
chicken
tiger
duck
None
分析散列搜索算法
分析散列表的使用情况时,最重要的信息就是载荷因子,越小发生冲突的概率就很小,元素也就各就各位,很大就意味这列表很拥挤,发生冲突的概率也很大。
简单给出一些近似的比较次数

排序
排序是指将集合中的元素按某种顺序排列的过程。与搜索算法类似,排序算法的效率与待处理元素的数目相关。对于小型集合,采用复杂的排序算法可能得不偿失,对于大型集合,需要尽可能充分的利用各种改善措施。
冒泡排序
冒泡排序多次遍历。它比较相邻的元素,将不合顺序的交换。每一轮遍历都将下一个最大值放到正确位置上。本质上,每个元素通过“冒泡”找到自己所属的位置。如果列表中有n个元素,那么第一轮遍历要比较n-1对。最大元素会一直往前挪,直到遍历过程结束。
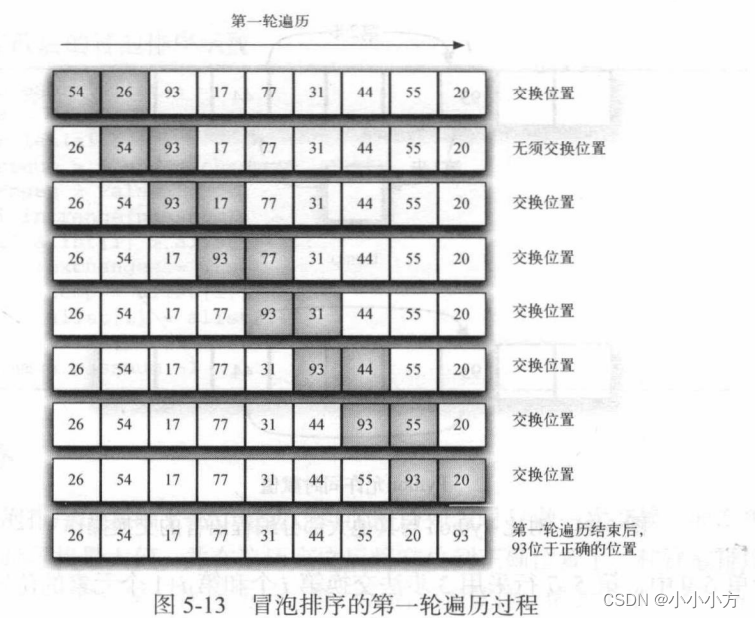
# 冒泡排序算法
def bubbleSort(alist):
for passnum in range(len(alist)-1,0,-1):
for i in range(passnum):
if alist[i] > alist[i+1]:
temp = alist
alist[i] = alist[i+1]
alist[i+1] = temp
Python中的交换操作和其他大部分编程语言不同,在交换两个元素的位置时,通常设置一个临时存储位置,但是Python允许同时赋值。
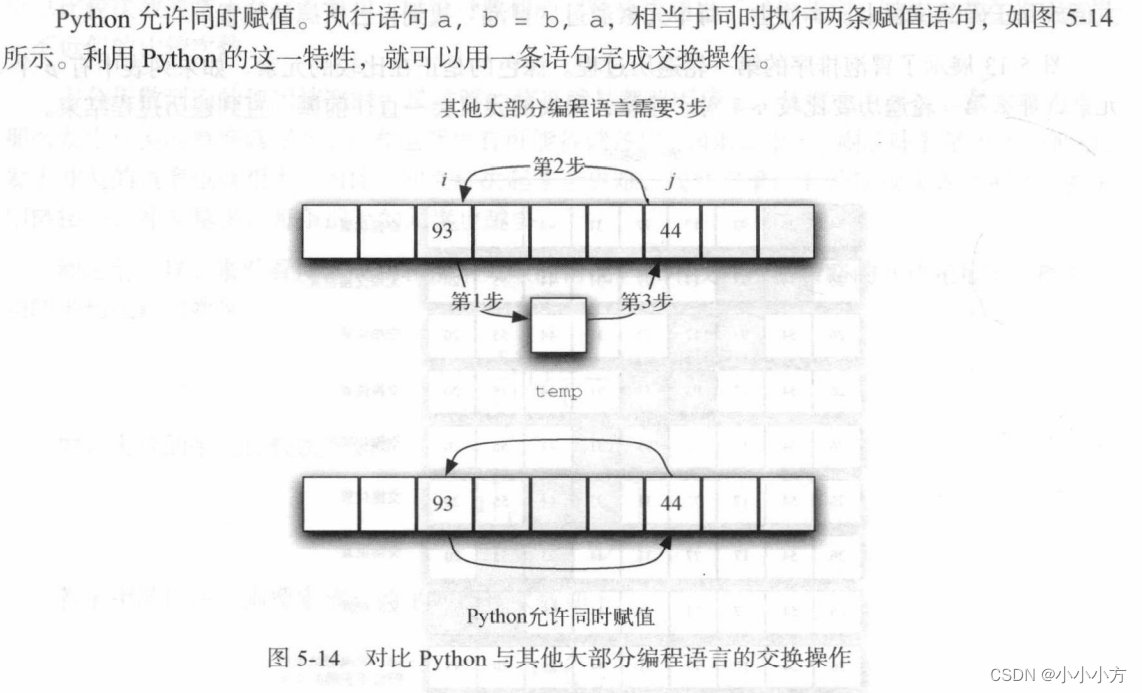
该算法的时间复杂度为O(n*n)。冒泡排序被认为是效率最低的排序算法,因为在确定最终位置前必须交换元素,但是它可以判断有序列表并提前终止排序过程。
# 修改后的冒泡排序
def shortBubbleSort(alist):
exchanges = True
passnum = len(alist-1)
while passnum >0 and exchanges:
exchanges = False
for i in range(passnum):
if alist[i]>alist[i+1]:
exchanges = True
temp = alist[i]
alist[i] = alist[i+1]
alist[i+1]= temp
passnum = passnum -1
选择排序
在冒泡的基础上做了改进,每次遍历列表时只做一次交换。选择排序在每次遍历时寻找最大值,并在遍历完之后将他放到正确位置上。第一次遍历之后,最大元素就位,第二次遍历后,第二大元素就位,以此类推。若给n个元素排序,需要遍历n-1轮。
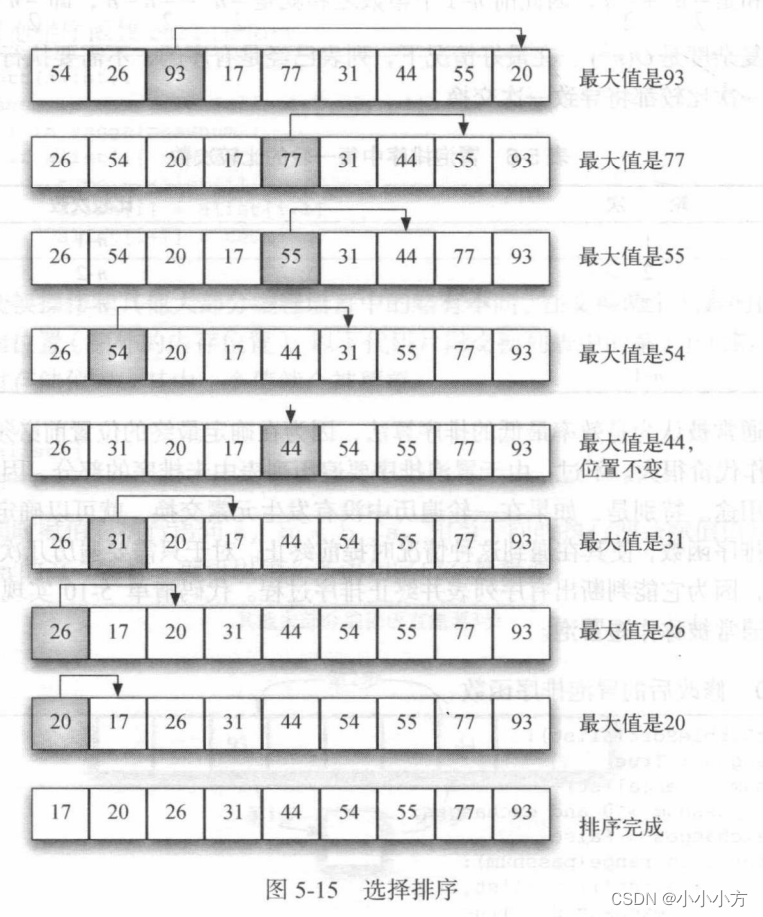
# 选择排序
def selectionSort(alist):
for fillslot in range(len(alist)-1,0,-1):
positionMax = 0
# 找到最大位置
for loctaion in range(1,fillslot+1):
if alist[loctaion]>alist[positionMax]:
positionMax = loctaion
# 交换
temp = alist[fillslot]
alist[fillslot]= alist[positionMax]
alist[positionMax]= temp
该算法时间复杂度为O(n*n)
插入排序
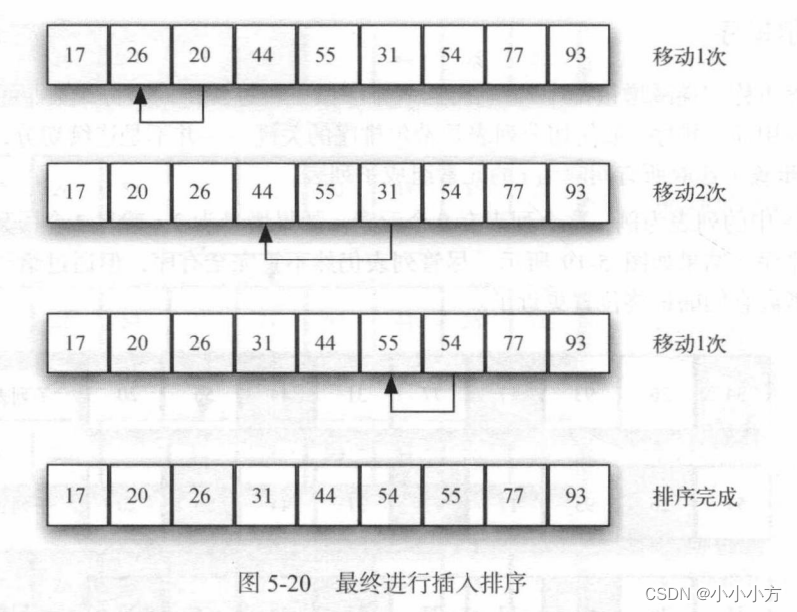
虽然时间复杂度为O(n*n),但这个原理不同。他在列表较低的一端维护一个有序的子列表,并逐个将每个新元素插入这个子列表。
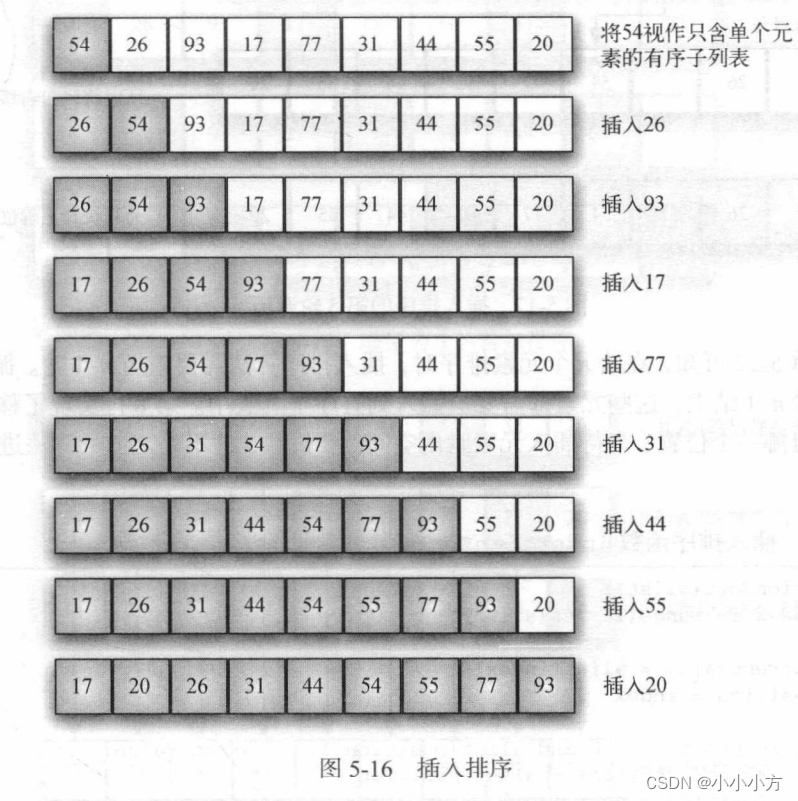
假设位置0处是只含单个元素的有序子列表,从元素1到元素n-1,每一轮都将当前元素与有序子列表中的元素进行比较。在有序子列表中,将比他打的元素右移,当遇到一个比他还小的元素或抵达子列表终点时,就可以插入当前元素。
# 插入排序
def insertionSort(alist):
for index in range(1,len(alist)):
currentvalue = alist[index]
position = index
# 假设位置0是有序子列表
while position >0 and alist[position-1]>currentvalue:
alist[position] = alist[position-1]
position = position-1
# 插入到正确位置
alist[position] = currentvalue
希尔排序
希尔排序也称为递减增量排序,对插入排序做了改进,将列表分成数个子列表,并对每个子列表应用插入排序。如何切分列表是希尔排序的关键,不是连续切分,是使用增量i选取所有间隔为i的元素组成子列表。
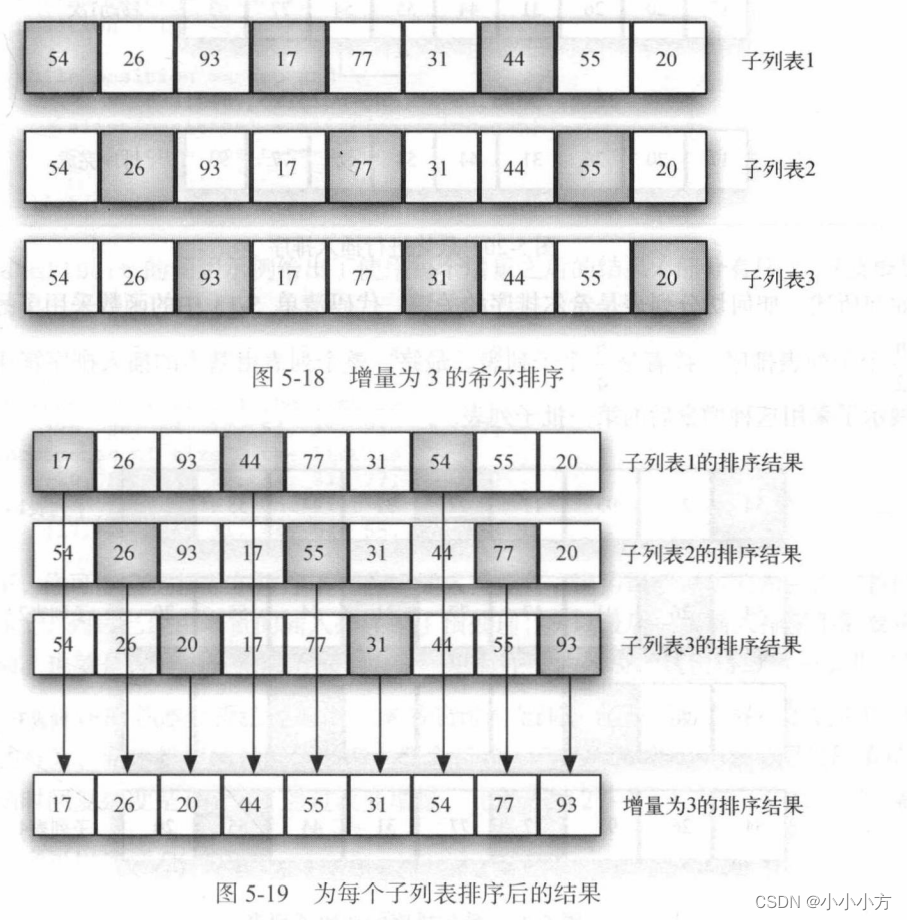
# 希尔排序
'''
先为n/2个子列表排序,接着是n/4个子列表
最终整个列表由基本的插入排序算法排好序
'''
def shellSort(alist):
# 增量
sublistcount = len(alist)//2
while sublistcount >0:
for startposition in range(sublistcount):
#调用插入排序函数
gapInsertionSort(alist,startposition,sublistcount)
print("After increments of size",sublistcount,"the list is",alist)
# 修改步长
sublistcount = sublistcount//2
# 插入排序但是步长为gap
def gapInsertionSort(alist,start,gap):
for i in range(start+gap,len(alist),gap):
currrentvalue = alist[i]
position = i
while position >= gap and alist[position-gap]>currrentvalue:
alist[position] = alist[position-gap]
position = position-gap
alist[position] = currrentvalue
alist = [54,26,93,17,77,31,44,55,20]
shellSort(alist)
运行结果:
After increments of size 4 the list is [20, 26, 44, 17, 54, 31, 93, 55, 77]
After increments of size 2 the list is [20, 17, 44, 26, 54, 31, 77, 55, 93]
After increments of size 1 the list is [17, 20, 26, 31, 44, 54, 55, 77, 93]
该算法的复杂度为O(n的3/2)
归并排序
使用分治策略改进排序算法。研究的第一个算法是归并排序,它是递归算法,每次将一个列表一分为二,如果列表为空或只有一个元素,从定义上来说就是有序的。如果列表不止一个元素,就将列表一分为二,并对两部分都递归调用归并排序。当这两部分都有序后,就进行归并这一基本操作。归并是指将两个较小的有序列表归并为一个有序列表的过程。
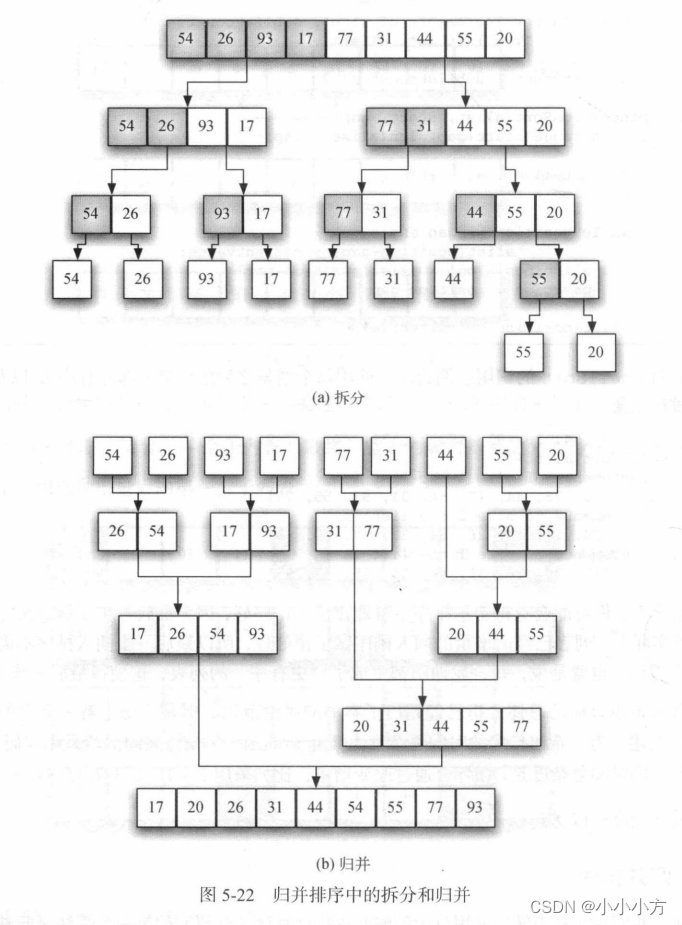
# 归并排序
def mergeSort(alist):
print("splitting",alist)
if len(alist)>1:
mid = len(alist)//2
lefthalf = alist[:mid]
righthalf = alist[mid:]
mergeSort(lefthalf)
mergeSort(righthalf)
i=0
j=0
k=0
while i<len(lefthalf) and j<len(righthalf):
if lefthalf[i] < righthalf[j]:
alist[k] = lefthalf[i]
i = i+1
else:
alist[k]= righthalf[j]
j = j+1
k= k+1
while i <len(lefthalf):
alist[k]= lefthalf[i]
i = i+1
k = k+1
while j <len(righthalf):
alist[k]= righthalf[j]
j= j+1
k = k+1
print("merge",alist)
b = [54,26,93,17,77,31,44,55,20]
mergeSort(b)
运行结果:
splitting [54, 26, 93, 17, 77, 31, 44, 55, 20]
splitting [54, 26, 93, 17]
splitting [54, 26]
splitting [54]
merge [54]
splitting [26]
merge [26]
merge [26, 54]
splitting [93, 17]
splitting [93]
merge [93]
splitting [17]
merge [17]
merge [17, 93]
merge [17, 26, 54, 93]
splitting [77, 31, 44, 55, 20]
splitting [77, 31]
splitting [77]
merge [77]
splitting [31]
merge [31]
merge [31, 77]
splitting [44, 55, 20]
splitting [44]
merge [44]
splitting [55, 20]
splitting [55]
merge [55]
splitting [20]
merge [20]
merge [20, 55]
merge [20, 44, 55]
merge [20, 31, 44, 55, 77]
merge [17, 20, 26, 31, 44, 54, 55, 77, 93]

mergeSort函数需要额外的空间来存储切片操作得到两半部分,当列表较大时,使用额外的空间可能会使排序出现问题。
快速排序
和归并排序一样,快速排序也采用分治策略,但不使用额外的存储空间。首先选取一个基准值,基准值的位置通常被称为分割点,算法在分割点切分列表,以进行快速排序的子调用。
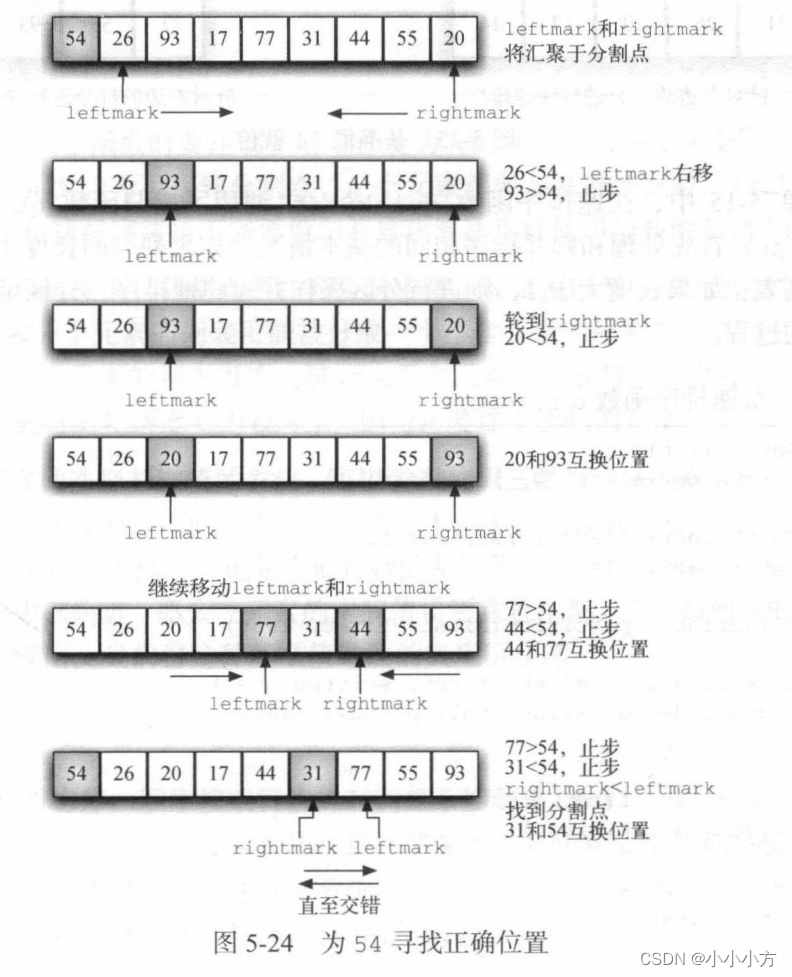
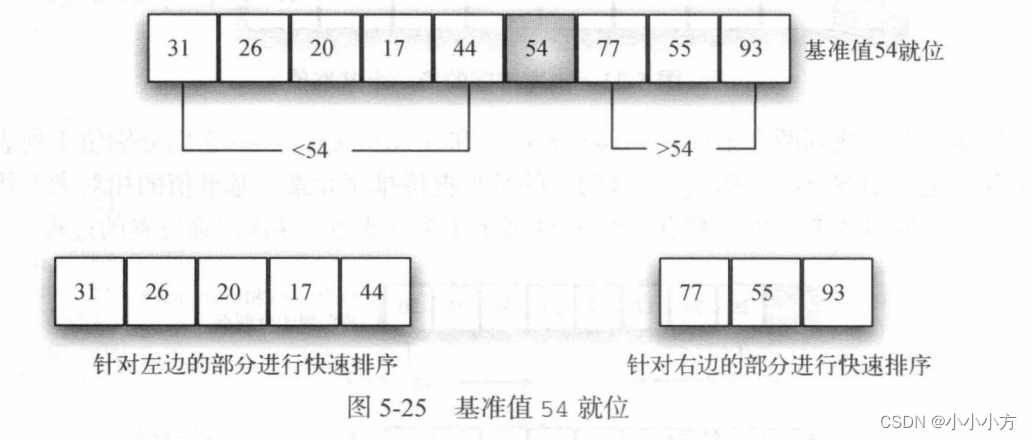
# 快速排序
def quickSort(alist):
quickSortHelper(alist,0,len(alist)-1)
# 分割列表
def quickSortHelper(alist,first,last):
if first < last:
splitpoint = partition(alist,first,last)
quickSortHelper(alist,first,splitpoint-1)
quickSortHelper(alist,splitpoint+1,last)
# 分割点
def partition(alist,first,last):
pivotvalue = alist[first]
leftmark = first +1
rightmark = last
done = False
while not done:
while leftmark <= rightmark and alist[leftmark] <= pivotvalue:
leftmark = leftmark +1
while alist[rightmark] >= pivotvalue and rightmark >= leftmark:
rightmark = rightmark -1
if rightmark < leftmark:
done = True
else:
temp = alist[leftmark]
alist[leftmark] = alist[rightmark]
alist[rightmark] = temp
# 最后一步交换
temp = alist[first]
alist[first] = alist[rightmark]
alist[rightmark] =temp
return rightmark
















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









