






一、产品经理能力要求
1.业务场景,how扩展
2.场景对话,人机交互,回答是否符合用户预期(反复、多轮)
3.用户&商业价值(to B ,人工替代,用户价值)
4.技术边界(NIP,行业技术,突破,同行创新。)
(二)理解数据
- 数据70%、算力20%、算法10%
- 注意数据的收集、处理
分三步:

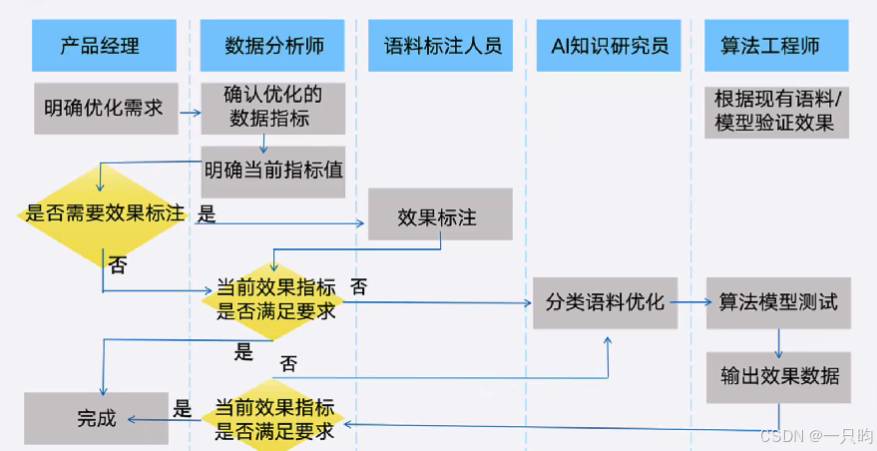
第一步:拆解业务需求
一、策略类需求分析
(一)判断是否需要AI,提出算法需求
- 是否能用规则描述
- 算法:机器、深度学习历史数据

(二)拆解算法需求
- 有明确的需求,根据需求的颗粒度,确认算法输入、输出,指标/ 预期
- 区分算法和工程需求
-
算法的目标:
算法的目标是高效、准确地解决问题。它通常关注的是时间复杂度(运行效率)、空间复杂度(资源占用)和准确性(结果的正确性)。例如,一个高效的排序算法可能需要在最坏情况下也能快速完成排序任务。 -
工程需求的目标:
工程需求的目标是满足用户或业务的实际需求,确保系统在实际环境中能够稳定、可靠地运行。它不仅关注功能的实现,还关注系统的可维护性、可扩展性、性能和安全性。 -
算法的关注点:
-
效率:算法通常需要在有限的时间和资源内完成任务,因此优化时间复杂度和空间复杂度是关键。
-
正确性:算法的结果必须是准确的,不能出现逻辑错误。
-
通用性:好的算法通常具有一定的通用性,可以应用于多种场景。
-
-
工程需求的关注点:
-
功能完整性:系统是否满足用户的所有功能需求。
-
性能:系统在实际运行中的响应速度、吞吐量等是否符合预期。
-
可扩展性:系统是否能够方便地扩展以适应未来的变化。
-
安全性:系统是否能够防止数据泄露、恶意攻击等安全问题。
-
可维护性:系统是否容易维护和升级。
-
-
算法示例:
假设我们需要对一组数据进行排序,可以选择快速排序算法。快速排序的核心思想是通过分治法将数据分成两部分,递归地对这两部分进行排序。它的重点是算法的逻辑和效率。 -
工程需求示例:
假设我们需要开发一个电商系统,工程需求可能包括:-
用户能够注册和登录(功能需求)。
-
系统能够处理每秒 1000 次的并发请求(性能需求)。
-
系统支持多种支付方式(功能需求)。
-
系统能够防止SQL注入攻击(安全需求)。
-
系统的代码结构清晰,方便后续维护(可维护性需求)。
-

(三)实现算法需求

第二步:跟进算法效果
情绪识别多用分类算法:将每个问题定位到一个情绪分类中

(一)持续效果跟踪
1.实现方式
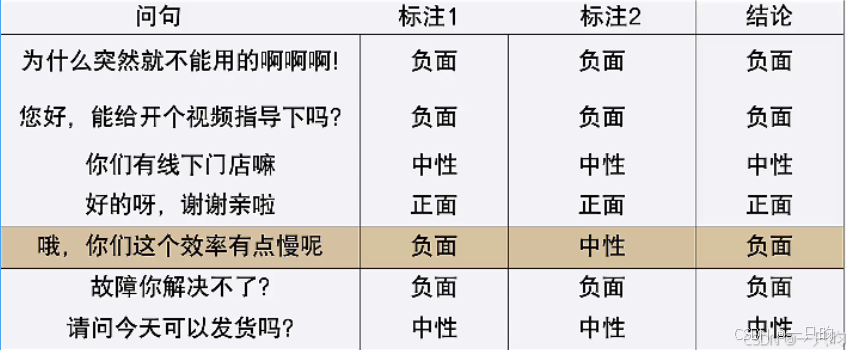
2.提供标注数据
- 学习标注的数据,两人标注取交集
- 标识数据的准确率是算法效果的上限
3.效果跟踪
80%的数据训练,20%的数据测试

评估分类模型性能的常用指标:准确率(Precision)、召回率(Recall)和 F1 分数
-
准确率(Precision):
Precision=TP+FPTP
准确率是指模型预测为正的样本中,实际为正的比例。计算公式为:其中,TP 是真正例(True Positive),即模型正确预测为正的样本数;FP 是假正例(False Positive),即模型错误预测为正的样本数
-
召回率(Recall):
Recall=TP+FNTP
召回率是指实际为正的样本中,模型正确预测为正的比例。计算公式为:其中,FN 是假负例(False Negative),即模型错误预测为负的样本数。
-
F1 分数(F1 Score):
F1=2×Precision+RecallPrecision×Recall
F1 分数是准确率和召回率的调和平均值,用于综合评估模型性能。计算公式为:F1 分数的取值范围是 [0, 1],值越接近 1 表示模型性能越好。
4.多源数据验证
不同场景下,测试预料是否达到预期
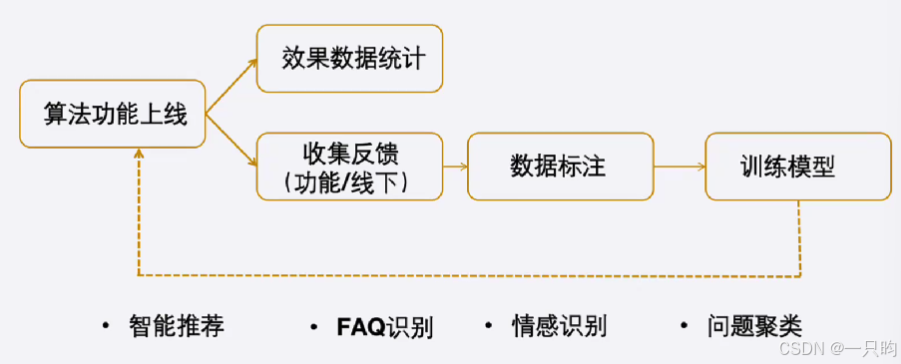
(二)效果优化
1.收集badcase,根据业务和时间变化,标注语料心得
2.配合算法工程师调参
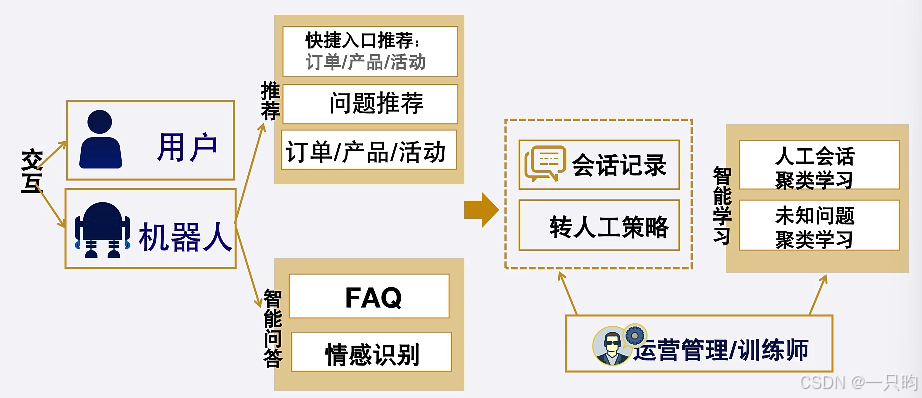
二、产品设计
(一)重视前端的交互设计
- 反思:产品价值的实现?
- 交互界面:从访客来源推荐问题
- 聊天、智能问答、后端管理

VUI(Voice User Interface)即语音用户界面,是一种通过语音输入和输出实现人机交互的技术。它允许用户通过语音命令与设备或系统进行交互,而无需依赖传统的图形界面或手动输入。
VUI 的常见应用场景包括智能音箱、智能车载系统、语音助手等
(二)保证算法模块功能闭环
SaaS(Software as a Service,软件即服务)
用户无需在本地安装和维护软件,而是通过订阅的方式按需使用云端软件。这种模式允许用户通过浏览器或其他客户端设备访问应用程序。
企业可以通过多种工具和平台实现在线数据收集和管理
两个典型的观察模型:
1.A/B 测试(A/B Testing):将用户随机分配到不同的实验组(A、B、C...),分别展示不同的模型或方案,然后比较各组的表现,选择效果最好的方案。
例子:如果有10个模型,可以将用户流量分成10份,每份分配10%的流量给一个模型。通过一段时间的实验,观察每个模型的性能指标(如点击率、转化率、用户留存等),最终选择表现最好的模型。
2.多臂老虎机算法(Multi-Armed Bandit,MAB):
动态优化策略,用于在多个选择(“臂”)中探索和利用最优解。它通过动态调整流量分配比例,优先分配更多流量给表现较好的模型,同时保留一定比例的流量用于探索其他模型。
例子:开始时,每个模型分配10%的流量。随着实验的进行,根据每个模型的表现动态调整流量分配比例。例如,表现好的模型可能分配到更多流量,而表现差的模型逐渐减少流量。
(三)弥补算法的不足
1.辅助算法识别
- 冷启动扩写标准语料,表达方式
- 添加正则表达式,关键词的强制召回
- 引导用户点选(输入内容的推荐、预测)
2.清洗数据,降低算法噪声
- ASR(语言转文字):维护转译词库(方言
- 专有词、同义词库(简称、符号代表)
- 过滤无意义词句(嗯,语气词),屏蔽词词库
核心指标:匹配的准确率

反问eg:你是否想问以下问题
解决方案:预测+引导

三、意图识别
(一)搭建意图体系
意图是指用户在交互过程中想要达成的目标或需求。它是用户行为背后的动机,是理解用户需求的关键。
意图是目的
根据满足动作,倒推意图
意图=目的+承接动作
根据满足动作,倒推意图
意图可以通过用户的行为和最终的行动来推断。通过分析用户完成某个动作的路径,可以反向推导出他们的意图。
意图 = 目的 + 承接动作
意图是一个组合概念,它不仅包括用户想要达成的目标(目的),还包括实现这个目标的具体行为(承接动作)。
例如,用户想要“查询订单状态”(目的),通过“输入订单号并点击查询”(承接动作)来实现。
上下文是指用户意图产生的环境和背景,包括但不限于:
历史兴趣:用户过去的行为和偏好。
当前场景:用户当前所处的环境或状态。
交互历史:用户与系统之前的交互记录。
1. 确定评估集
先优化占比较大的意图,意图占比
优先优化那些在用户交互中出现频率较高(占比大)的意图,因为这些意图对用户体验的影响最大。
(1)评估规模:
评估集的规模应足够大,以确保统计结果的可靠性。建议至少包含1000条样本数据。
(2)抽取时间:样本数据应涵盖不同时间段,以反映用户行为的多样性和变化性。
(3)抽取方式:采用随机抽样,确保样本的代表性。具体方式包括:
-
随机不去重:随机抽取样本,不进行去重处理,以保留真实用户行为的重复性。
-
地点:考虑样本的地理位置分布,确保覆盖不同区域。
-
订单:按用户行为的顺序抽取样本,以保留用户行为的连贯性。
-
3-5条:每个用户抽取3-5条行为记录,以分析用户的意图连贯性。
注意:随机取数的逻辑:采用真实随机算法,确保样本的随机性和无偏性。
2. 输出评估文档
评估文档应包含以下内容:
-
样本数据:抽取的样本数据及其来源。
-
意图标注:对每个样本数据标注其意图。
-
上下文信息:样本数据的上下文背景,包括历史兴趣、当前场景等。
-
评估标准:明确评估意图识别准确性的标准和方法。
3. 交叉评估
人 - 主观
交叉评估应包括不同角色的主观评估,以确保数据质量和意图标注的准确性。
-
2-3人参与:评估团队应包括算法工程师、业务专家和运营人员,分别从技术、业务和用户体验的角度进行评估。
-
一起开会评估:团队成员共同参与评估过程,通过讨论和协商确保数据标注的一致性
-
给出评估标准:明确评估意图识别准确性的标准,以帮助特例的判断,提高效率
(二)训练识别模型
-
数据准备:
-
收集并标注大量用户行为数据,确保数据的多样性和代表性。
-
对数据进行预处理,包括清洗、去噪和特征提取。
-
-
模型选择:
-
根据业务需求选择合适的机器学习或深度学习模型,如逻辑回归、支持向量机(SVM)、循环神经网络(RNN)或Transformer架构。
-
-
模型训练:
-
使用标注好的数据训练模型,调整模型参数以优化性能。
-
采用交叉验证等方法评估模型的泛化能力。
-
-
模型优化:
-
根据评估结果调整模型结构或参数,进一步提升模型性能。
-
(三)评估模型效果
-
准确率(Precision):评估模型预测为正的样本中实际为正的比例。
Precision=TP+FPTP -
召回率(Recall):评估模型正确预测为正的样本占所有真实正样本的比例。
Recall=TP+FNTP -
F1分数(F1 Score):综合考虑准确率和召回率的调和平均值。
F1=2×Precision+RecallPrecision×Recall -
混淆矩阵(Confusion Matrix):通过混淆矩阵直观展示模型的预测结果与真实标签的匹配情况。
(四)常见的优化思路
1.缺失意图的处理:
- 分析用户行为中未被识别的意图,补充意图体系。
- 收集更多相关数据,优化模型以覆盖缺失意图。
2.模糊意图的处理:
- 对模糊意图进行分类和细化,明确其可能的含义。
- 使用上下文信息辅助意图识别,减少模糊性。
3.实时意图识别:
- 优化模型的计算效率,确保实时响应用户需求。
- 引入流式数据处理技术,实时更新意图识别结果。
4.不同业务、行业的适配:
- 根据不同业务场景和行业特点,定制意图体系和模型。
- 收集行业特定的数据,优化模型以适应特定领域的用户行为。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









