






一、研究背景:
根据加拿大省级宏观数据,进行简单的数据分析。
二、原始数据:
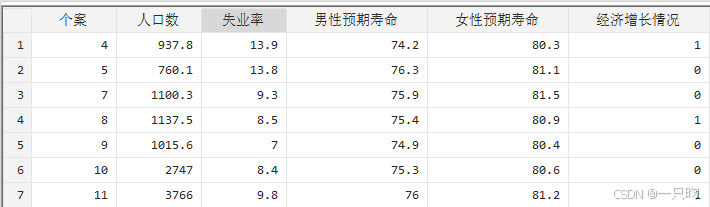
三、问题及代码
1、数据导入
录入数据并命名为“课堂作业1”
方法一:导入-选择文件
方法二:代码导入Excel文件
import excel "课堂作业1.xlsx", firstrow clear2、变量命名
将变量abcde分别命名为人口数、失业率、男性预期寿命、女性预期寿命、经济增长情况。
rename 变量a 人口数
rename 变量b 失业率
rename 变量c 男性预期寿命
rename 变量d 女性预期寿命
rename 变量e 经济增长情况3、变量分布情况
查看变量e的分布情况,请问有经济增长的省份(赋值=1)所占比例为多少?
如果需要查看变量e中赋值为1的比例,而不是单独查看e等于1的频数,你可以使用tabulate命令并结合row选项来获取每个类别的频数和所占的百分比。
tabulate (可缩写为tab) 经济增长情况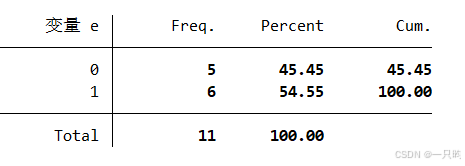
典型错误
tab 经济增长情况 if 经济增长情况 == 1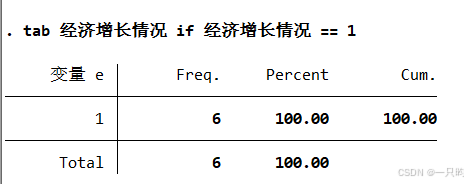
如果你想要计算并显示有经济增长(即变量e赋值为1)的省份所占的比例,你可以使用tabulate命令并结合generate选项来创建一个新变量,该变量包含每个类别的频数,然后使用summarize命令来计算百分比。以下是相应的Stata命令:
tab 经济增长情况, generate(ep)
summarize ep1ep是新生成的变量,它包含变量e每个类别的频数。ep1是赋值为1的类别的频数。
使用summarize命令可以查看ep1的总和,即赋值为1的观测值的数量。
然后用这个总和除以变量e的总观测值数量来得到比例。

方法三:
gen count = 1:生成一个新变量count,其值恒为1。
tabulate 经济增长情况 if 经济增长情况 == 1, generate(freq):对经济增长情况变量中赋值为1的观测值进行频数统计,并将结果存储在freq变量中。
sum freq1:计算freq1变量的总和,这里freq1是经济增长情况赋值为1的频数。
scalar prop_growth = freq1 / r(N):计算有经济增长的省份所占的比例,其中freq1是有经济增长的省份的频数,r(N)是总观测值数量。
display "有经济增长的省份所占比例为:" prop_growth:显示有经济增长的省份所占的比例。
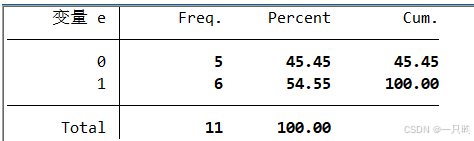

4、变量分组
将失业率进行分成三组(10以下,10到15,15以上),并生成新变量(unemp)
recode 变量名 (旧值1=新值1) (旧值2=新值2) ..., generate(newvar)
1.将数据转为数值格式,force 表示强力,若遇到无法转化的替换为空值
destring 失业率, replace forcerecode 失业率 (min/10=1) (10.01/15=2) (15.01/max=3), generate(unemp)
recode 失业率 (min/10=1) (10<15=2) (15/max=3),generate(unemp)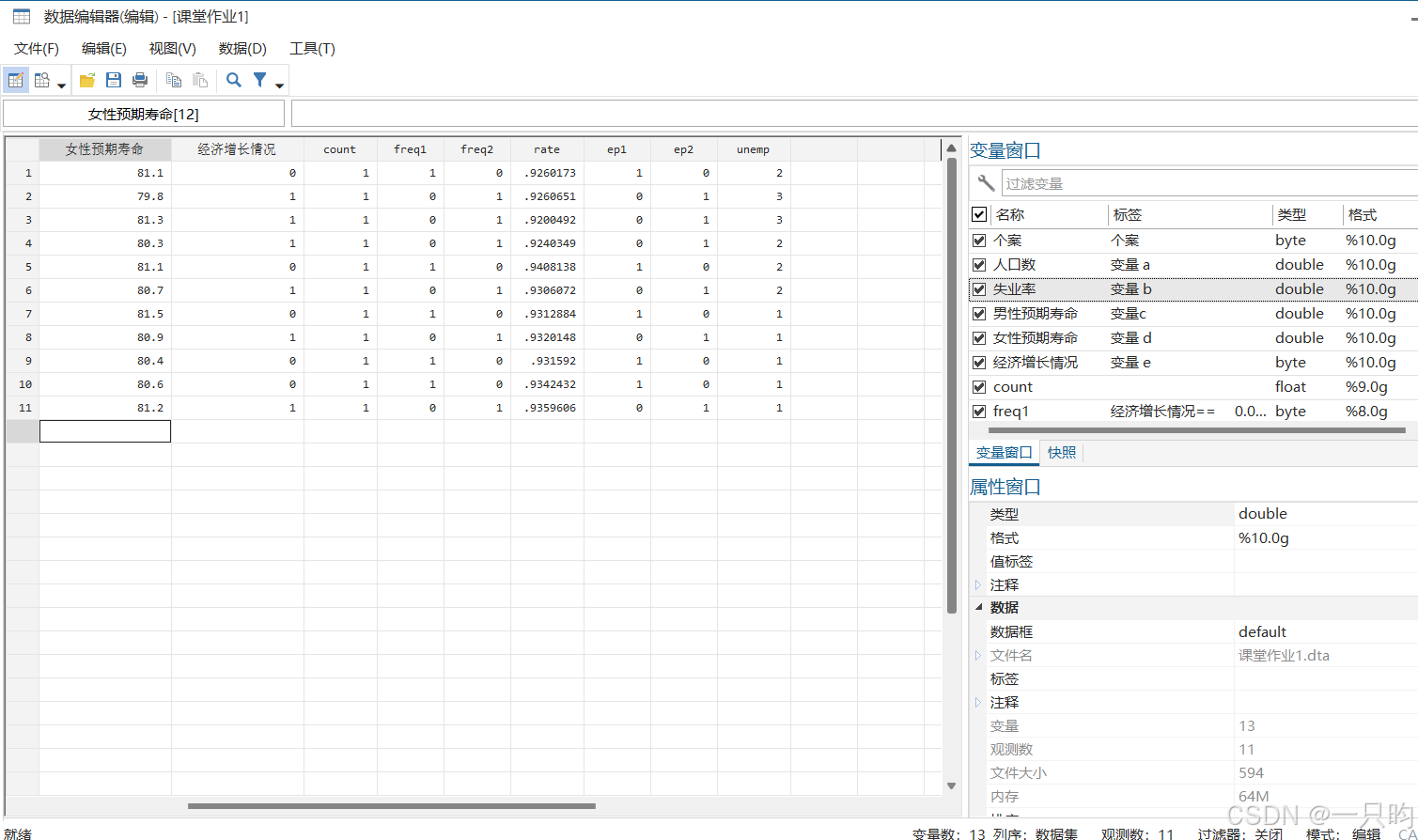
5、计算某变量的比例
计算出每个省份的男性与女性的预期寿命比,并生成新变量(rate)
gen rate = 男性预期寿命 / 女性预期寿命如果女性预期寿命中有可能为0的情况,直接进行除法运算将导致除以零的错误。为了处理这种情况,你可以在进行除法之前先检查分母是否为0,并为这些情况设置缺失值:
gen rate = .
replace rate = 男性预期寿命 / 女性预期寿命 if 女性预期寿命 != 0
6、去掉特定数值
将人口数最多和最低的省份去掉,并计算出有经济增长与无经济增长的省份比例 。
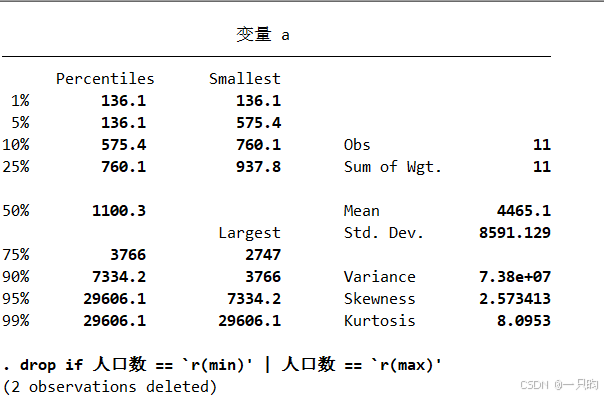
sum 人口数, detail*这将给出人口数的最大值和最小值。
drop if 人口数 == `r(min)' | 人口数 == `r(max)'请注意,反引号 ` 和单引号 ' 是必要的,它们告诉Stata r(min) 和 r(max) 是之前命令的返回结果。
反引号 `:用于引用命令的返回结果(return code)。在Stata中,当你执行一个命令后,Stata会存储一些特定的返回值,例如最近一次命令的输出结果、统计量等。这些返回值可以通过 r() 函数来访问,而反引号 ` 用于包围 r() 函数中的返回值名称。
例如,如果你运行了 summarize 命令,Stata会返回一些统计量,如最小值 r(min)、最大值 r(max)、
scalar total = r(N)
scalar with_growth = sum(经济增长情况 == 1)
scalar prop_growth = with_growth / total
display "有经济增长的省份所占比例为:" prop_growth
scalar是一个命令,用于创建和操作标量值。标量是单个数值,不是数组或矩阵中的元素。使用scalar命令,你可以定义新的标量,给标量赋值,以及执行一些基本的数学运算
7、保存及输出
方法一:将以上命令保存,生成新的do.file文件,命名为“课堂作业1”
log close这会创建一个名为 课堂作业1.txt 的文本文件,其中包含了你的分析过程和结果。
保存并输出为Excel文件:
方法二:Stata也支持直接将数据集导出为Excel文件:
export excel using 课堂作业1.xlsx, replace
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









