







CART(Classification and Regression Trees)是一种常用的决策树算法,既可以用于分类问题,也可以用于回归问题。CART分类树的主要思想是通过递归地将数据集划分为更小的子集,使得每个子集内的样本属于同一类别。与C4.5算法不同,CART分类树使用基尼系数作为属性选择的准则。
以下是CART分类树算法的主要步骤:
1.数据集划分:将原始数据集划分为训练集和测试集。
2.属性选择:计算每个属性的基尼系数,选择基尼系数最小的属性作为当前节点的划分标准,基尼系数越小表示划分后的纯度越高。
3.决策树构建:根据选择的属性将数据集划分为多个子集,每个子集对应一个分支。递归地对每个子集进行属性选择和决策树构建。
4.剪枝:若构建好的决策树分支过多,则可能需要对其进行剪枝操作,以减少过拟合的风险。
5.分类预测:使用构建好的决策树对新样本进行分类预测。
CART分类树的特点是生成的决策树是二叉树,每个内部节点都有两个分支。CART算法通过贪心的方式逐步最小化基尼系数,构建出具有较好分类性能的决策树模型。
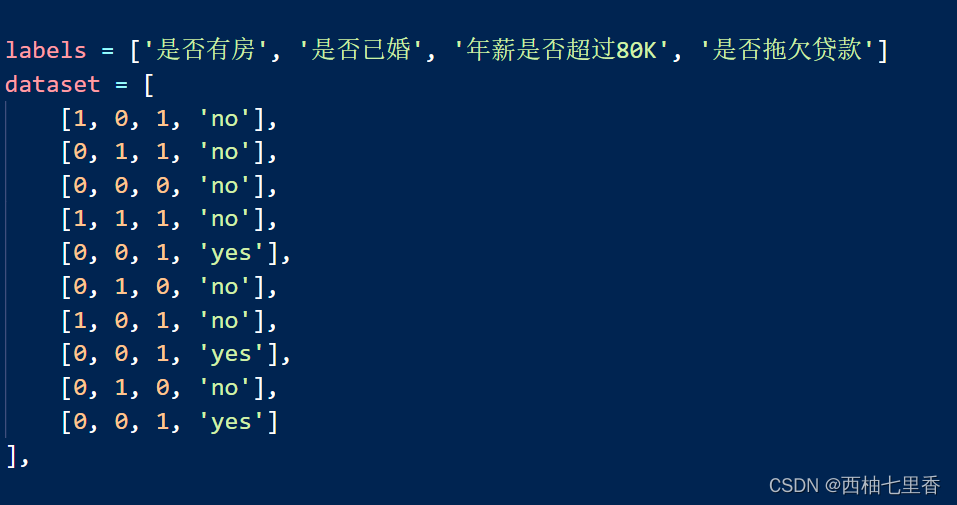
本次代码中的数据集我选用是否拖欠贷款的数据,每条数据的属性均包含是否有房、是否已婚、年薪是否超过80K和是否拖欠贷款,其中属性值为1表示是,属性值为0表示否。
具体的python代码如下:
def CreateTree(dataset, labels): # 递归构建分类决策树,用Python中的字典来存储树的结构
n = len(dataset) # 求出数据集中有多少条数据
ginis = [] # 用列表ginis计算每个属性的基尼系数
yes = 0 # 记录拖欠贷款的人数
no = 0 # 记录没有拖欠贷款的人数
for i in range(0, n):
if dataset[i][len(dataset[0])-1] == 'yes':
yes += 1
else:
no += 1
if yes == n: # 递归边界,即剩余数据中全为拖欠贷款的情况
Leaf = {}
Leaf['result'] = 'yes' # 结果为拖欠贷款
Leaf['IsLeaf'] = True # 标记此节点为叶子节点
return Leaf
if no == n: # 递归边界,即剩余数据中全为不拖欠贷款的情况
Leaf = {}
Leaf['result'] = 'no' # 结果为不拖欠贷款
Leaf['IsLeaf'] = True # 标记此节点为叶子节点
return Leaf
if len(dataset) == 1: # 递归边界,即只剩1条数据时的情况
yes = 0
no = 0
for i in range(0, len(dataset)):
if dataset[i][len(dataset[0]) - 1] == 'yes':
yes += 1
else:
no += 1
Leaf = {}
if yes > no:
Leaf['result'] = 'yes'
Leaf['IsLeaf'] = True
else:
Leaf['result'] = 'no'
Leaf['IsLeaf'] = True
return Leaf
for j in range(0, len(dataset[0])-1):
yes = 0 # 记录属性值 = 1 的人数
no = 0 # 记录属性值 = 1 的人数
yes1 = 0 # 记录当属性值 = 1 时拖欠贷款的人数
no1 = 0 # 记录当属性值 = 1 时不拖欠贷款的人数
yes2 = 0 # 记录当属性值 = 0 时拖欠贷款的人数
no2 = 0 # 记录当属性值 = 0 时不拖欠贷款的人数
for i in range(0, n):
if dataset[i][j] == 1:
yes += 1
if dataset[i][len(dataset[0]) - 1] == 'yes':
yes1 += 1
else:
no1 += 1
else:
no += 1
if dataset[i][len(dataset[0]) - 1] == 'yes':
yes2 += 1
else:
no2 += 1
p1 = yes1 / yes
p2 = no1 / yes
# 计算属性值 = 1 时的基尼系数
gini1 = 1 - (p1 * p1 + p2 * p2)
p1 = yes2 / no
p2 = no2 / no
# 计算属性值 = 0 时的基尼系数
gini2 = 1 - (p1 * p1 + p2 * p2)
# 计算加权基尼系数
gini = (yes / n) * gini1 + (no / n) * gini2
ginis.append(gini)
min = 0
for i in range(0, len(ginis)):
if ginis[i] < ginis[min]:
min = i # 求出哪个属性的加权基尼系数最小
dataset2 = []
for i in range(n - 1, -1, -1): # 根据属性值为0或1将数据划分为两部分,再分别对这两部分数据递归地构建子树
if dataset[i][min] == 1:
dataset2.append(dataset[i])
dataset.pop(i)
for i in range(0, len(dataset2)): # 将已作为根节点的属性从原有属性集中剔除掉
dataset2[i].pop(min)
for i in range(0, len(dataset)):
dataset[i].pop(min)
# 构建节点
Node = {}
# 该节点为分支节点
Node['feature'] = labels[min]
Node['IsLeaf'] = False
labels.pop(min)
# 递归地划分左右子树
Node['left'] = CreateTree(dataset2, labels)
Node['right'] = CreateTree(dataset, labels)
return Node
# 根据已构建的子树来预测数据
def TestTree(Tree, Node):
if Tree['IsLeaf'] == True:
if Tree['result'] == 'yes':
print('会拖欠贷款')
else:
print('不会拖欠贷款')
else:
if Node[Tree['feature']] == 1:
TestTree(Tree['left'], Node)
if Node[Tree['feature']] == 0:
TestTree(Tree['right'], Node)
labels = ['是否有房', '是否已婚', '年薪是否超过80K', '是否拖欠贷款']
dataset = [
[1, 0, 1, 'no'],
[0, 1, 1, 'no'],
[0, 0, 0, 'no'],
[1, 1, 1, 'no'],
[0, 0, 1, 'yes'],
[0, 1, 0, 'no'],
[1, 0, 1, 'no'],
[0, 0, 1, 'yes'],
[0, 1, 0, 'no'],
[0, 0, 1, 'yes']
],
if __name__ == '__main__':
Tree = {}
# 构建决策树
Tree = CreateTree(dataset[0], labels)
# 打印决策树
print(Tree)
# 输入测试数据
test = {}
test['是否有房'] = int(input("是否有房: "))
test['是否已婚'] = int(input("是否已婚: "))
test['年薪是否超过80K'] = int(input("年薪是否超过80K: "))
# 利用已构建的决策树来进行预测
TestTree(Tree, test)
代码运行结果如下 :
















 1614
1614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









