






思维导图

一、编译过程
了解C语言先从了解C语言编译过程开始
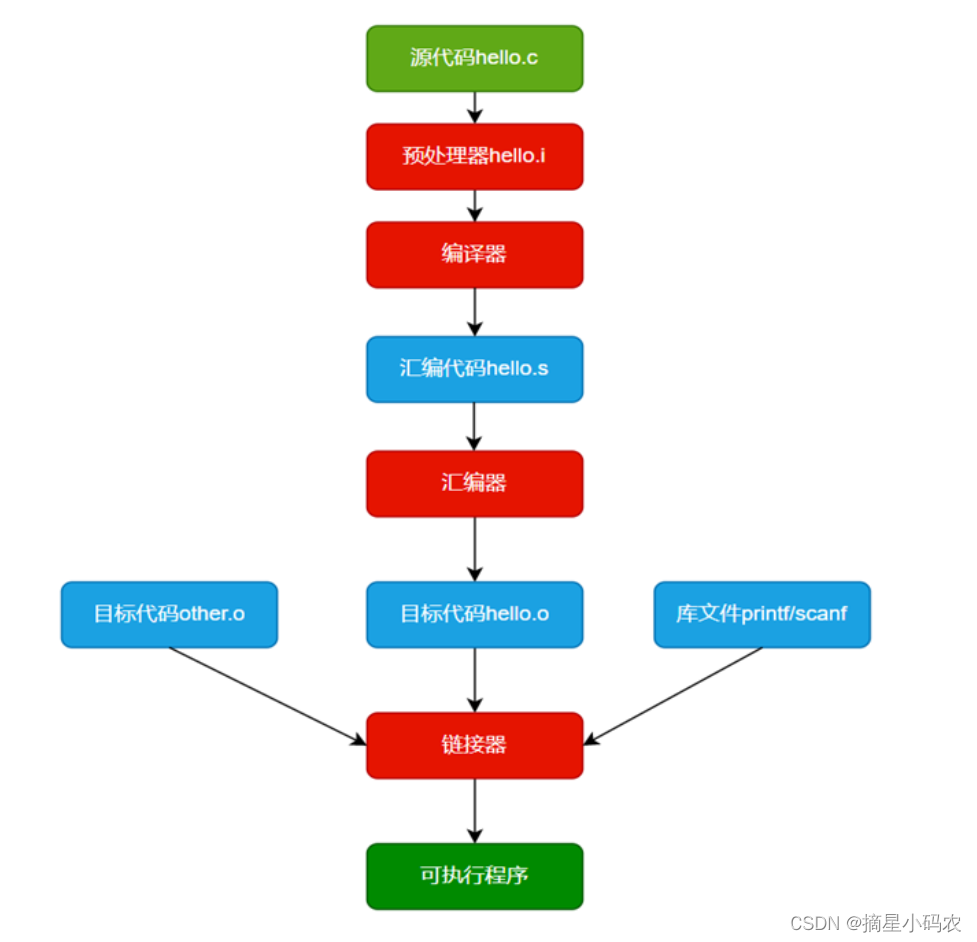
1.1 预处理
gcc -E main.c -o main.i
(1)展开头文件
(2)宏替换
(3)删除注释,或者注释变空行
(4)处理条件编译的逻辑
1.2 编译
gcc -S main.i -o main.s
(1)将源代码编译成汇编语言
(2)逐行检查语法错误(耗时的原因)
1.3 汇编
gcc -c main.s -o main.o
将汇编语言变成机器语言(二进制文件)
1.4 链接
gcc main.o -o main.exe
(1)链接静态库文件
(2)链接其他目标文件
(3)生成符号表
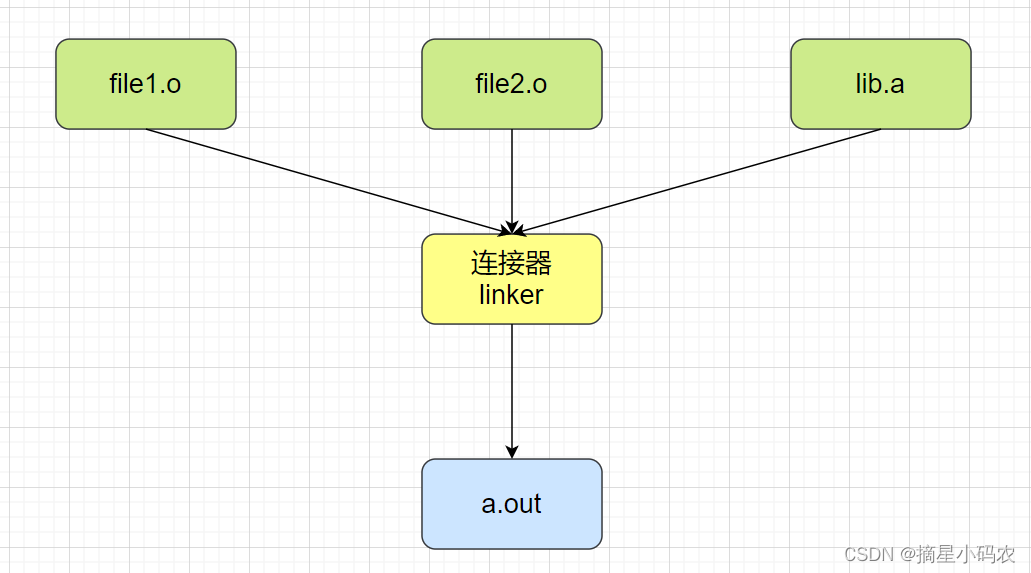
1.4.1 静态链接
静态链接是指在编译阶段直接把静态库加入到可执行文件中去(.o文件与链接库.a文件拼接在一起),这样可执行文件会比较大,比较占内存空间。如果可执行程序被并发运行多次,就会重复调用.a链接库文件进入内存,这样会造成很大的空间资源浪费,即静态链接是以空间换时间。
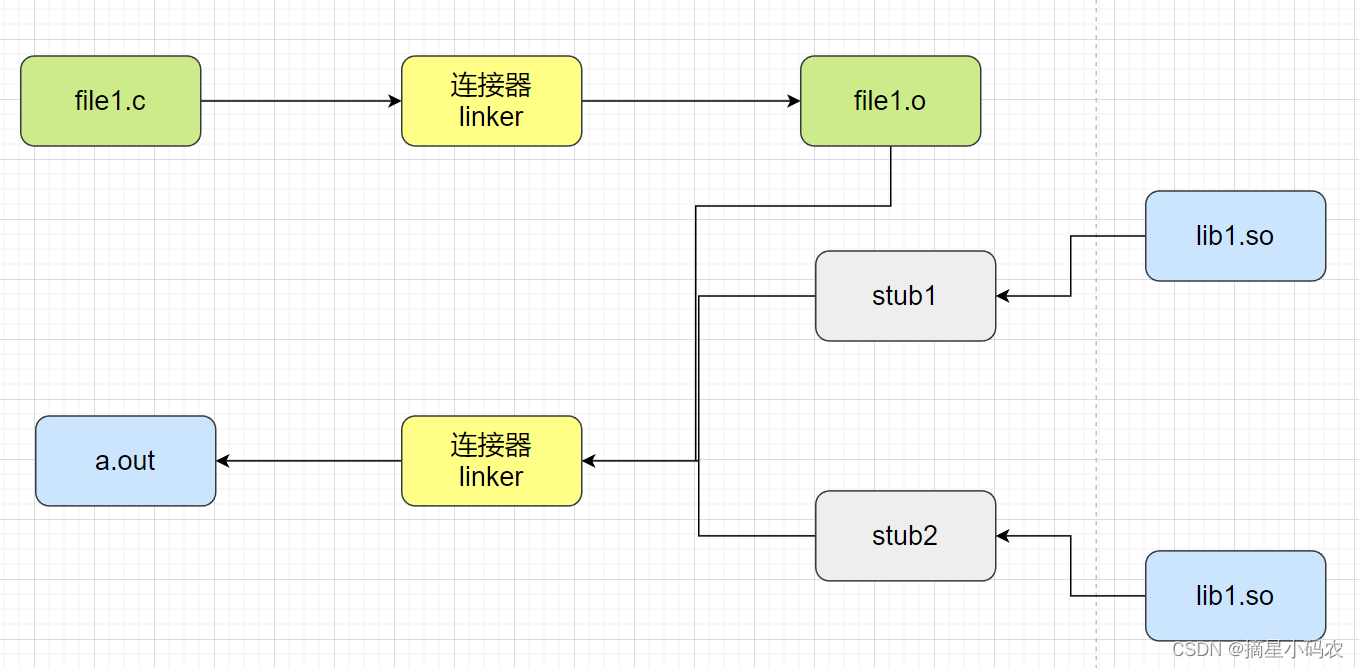
1.4.2 动态链接库
动态链接则是指链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
二、基本语法
2.1 进制转换
| 二进制 | 八进制 | 十进制 | 十六进制 |
| 1111010 | 172 | 122 | 7A |
| 100101100 | 454 | 300 | 12C |
2.2 常量
2.3 宏
(1)有参宏和无参宏:
有参宏也称之为函数式宏,但不是函数
无参宏就是普通的宏
(2)编写风格:
宏的位置可以任意位置,一般我们定义到文件开头文件【头文件下面】
编写宏是要采用全部大写,如果有多个单词,使用下划线,尽量不要使用__开头
编写有参宏要给每一个参数都带上括号,整个宏也把括号带上;
同时如果定义的是负数的宏,也建议加上括号
(3)面试中的宏:
#define MAX_VALUE(x, y) ((x) > (y) ? (x) : (y))
#define ADD(x, y) ((x) + (y))
#define ERROR_CODE (-1)
2.4 数据类型
(1)基本数据类型:
整型:short; int; long; long long; 加unsigned修饰的整型数
浮点型:float; double; long double
字符型: char布尔类型:_Bool
(2) 基本数据类型范围
| 数据类型 | MIN | MAX |
| char(有符号) | -128 | 127 |
| unsigned char(无符号) | 0 | 255 |
| short | -32768 | 32767 |
| unsigned short | 0 | 65535 |
| int/long | -21亿 | 21亿 |
| unsigned int | 0 | 42亿 |
| long long | -2e63 | 2e63 |
| unsigned long long | 0 | 2e64 |
| float | ||
| double | ||
| long doublie |
(3)数组:
占用的总字节数:sizeof(数组名)
(4)指针类型:
任意指针类型占用的字节数:32位编译器是4,64位编译器为8
2.5 变量
2.6 表达式
2.7 标准输入和标准输出
默认的整型数是int类型
默认的浮点数是double类型
格式化输出占位符:%d %ld %lld int/long/long long
%u unsigned int
%f %lf %Lf float/double/long double
%.2f
%c char
%s 字符串/字符数组
%o %#o 八进制
%x %X %#x %#X 十六进制
2.8 运算符
sizeof和strlen区别:
(1)sizeof是运算符,strlen是函数 <string.h>
(2)sizeof测的变量、常量、表达式、类型在内存中实际占用的字节大小(单位就是字节)strlen测的字符串常量、字符指针、字符数组名中有效字符的长度(单位就是个)
(3)sizeof 遇到'\0'不会停止, 同时会统计'\0'占用的字节大小,strlen遇到'\0'会停止, 不会统计'\0'这个字符
2.9 位运算
2.9.1 左移运算和右移运算
左移运算符:<<
高位丢弃,低位补零
左移一位就是乘以2
右移运算符:>>
低位丢弃,高位补的是符号位(负号需要特别注意)
右移一位就是除以2
2.9.2 位与、位或、位非(按位取反)、位异或
位与
按位进行与运算,全1为1,有0则0
位或
按位进行或运算,有1为1,全0则0
位非(按位取反)
按位进行取反运算,1变0,0变1
位异或
按位进行异或运算,相同为0,不同为1
设置某一位上的值为1
val = val | (1 << n)
清空某一位上的值,即变为0
val = val & (~(1 << n))
获取某一位上的值val = (val >> n) & 1
val = val & (1 << n)
三、关键字
3.1 const
const 修饰普通变量
(伪常量,不能直接修改,可以间接修改)
const 修饰指针变量
常量指针 const char * / char const *
指针所指向的内存块的值不能被修改
指针常量 char * const
指针的指向不能被修改 ,指针本身不能被修改
常量指针常量 const char * const
3.2 static
可以修饰全局函数:静态全局函数 -> 代码区
表示该函数只能在本文件使用
可以修饰局部变量:静态局部变量 -> 全局静态区
表示该变量只能在本函数中使用,同时只初始化一次,同时他是编译时期就已经确定了值啦,函数多次调用不会重新初始化
可以修饰全局变量:静态全局变量 -> 全局静态区
表示该变量只能在本文件使用,只初始化一次,在编译时期就已经确定了值啦
3.3 extern
声明一个外部变量或者函数,尽量写在头文件中,避免在源文件中使用
声明一个外部变量时,不能省略
声明一个外部函数时,可以省略
3.4 volatile
volatile 关键字(keywords)是一种类型修饰符, volatile 的英文翻译过来是 “易变的”
用 volatile 声明类型变量的时候,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问
如果不使用 volatile 进行声明,则编译器将对所声明的语句进行优化
即 volatile 关键字影响编译器编译的结果,用 volatile 声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错
四、指针数组/函数
4.1 指针常量和常量指针
常量指针:指向常量的指针【强调的是指针指向的值不能修改】
格式:const char *p
char const *p;
指针常量:指针是个常量【强调的是指针的指向不能修改】
格式:char *const *p;
eg: 数组名就是个指针常量,不能用于任何的赋值运算符
常量指针常量:指针指向的值不能修改,指针的指向也不能修改
格式:const char * const p;
4.2 指针数组和数组指针
指针数组: 数组中元素的类型是指针【强调的是数组】
void test01()
{
int arr[] = {2, 3, 4};
int *p[] = {&arr[0], &arr[1], &arr[2]};
int len = sizeof(p) / sizeof(int *);
for (int i = 0; i < len; ++i)
{
printf("%d ", *(p[i]));
}
printf("\n");
}数组指针: 指向数组的指针【强调的是指针】
void test01()
{
int arr[] = {2, 3, 4};
printf("%p\n", arr);
printf("%p\n", arr + 1);
int (*p)[3] = &arr; // p指向了一个长度为3的数组
printf("%p\n", p);
int (*q)[3] = p + 1; // p + 1实际上是跳过了整个数组,即sizeof(arr)个字节
printf("%p\n", q);
int len = sizeof(arr) / sizeof(int);
for (int i = 0; i < len; ++i)
{
printf("%d ", (*p)[i]); // 需要先解引用得到数组名, 才能通过数组名进行下标访问数组元素
}
printf("\n");
}4.3 指针函数和函数指针
函数的返回值是指针【重点强调的是函数】
如:strcpy、strcat、strlwr、strupr函数的返回值都是指针类型
注意: 函数内不能直接返回局部变量的地址, 函数调用结束后局部变量的内存会被自动回收
函数指针:指向函数的指针变量【重点强调的是指针】
int add(int a, int b)
{
return a + b;
}
// 形式一
typedef int (*FUNC_P1)(int, int);
// 形式二
typedef int (FUNC_P2)(int, int);
int main()
{
FUNC_P1 p1 = add;
printf("%d\n", p1(2, 3));
FUNC_P2* p2 = add;
printf("%d\n", p2(2, 3));
// 形式三
int (*p3)(int, int) = add;
printf("%d\n", p3(2, 3));
return 0;
}五、常见算法
5.1 链表的增删改查
typedef struct ListNode {
int val;
struct ListNode *next;
} ListNode;
void insertNodeByTail(ListNode *head, int val)
{
ListNode *newNode = (ListNode *) malloc(sizeof(ListNode));
newNode->val = val;
newNode->next = NULL;
// 第一次的
if (head->next == NULL)
{
head->next = newNode;
} else
{
// 第二次或者后面几次,你得找到这个链表的最后节点
ListNode *curr = head->next;
while (curr->next != NULL) {
curr = curr->next;
}
curr->next = newNode;
}
}
void printNode(ListNode *head)
{
ListNode *curr = head->next;
while (curr) {
printf("%d ", curr->val);
curr = curr->next;
}
printf("\n");
}
// 头插法
void insertNodeByFirst(ListNode *head, int val)
{
ListNode *newNode = (ListNode *) malloc(sizeof(ListNode));
newNode->val = val;
newNode->next = NULL;
if (head->next == NULL)
{
head->next = newNode;
} else
{
// ListNode *node = head->next; // 首节点
// head->next = newNode; // 头节点的下一个是新节点
// newNode->next = node; // 新节点的下一个是首节点
newNode->next = head->next;
head->next = newNode;
}
}5.2 冒泡排序
(1) 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
(2) 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
(3) 针对所有的元素重复以上的步骤,除了最后一个元素;
(4) 重复步骤1~3,直到排序完成。
核心思想:
外层for控制比较的轮次
内层for控制每一轮的比较次数
//冒泡排序一维数组
void sort01(int *arr, int len)
{
for (int i = 0; i < len - 1; ++i) {
for (int j = 0; j < len - i - 1; ++j) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}5.3 二分法查找
规则:
1.数组必须有序,否则二分查找算法就会失效
2.定义两个指针,left和right, 注意while循环的条件是否包含left == right的情况【注意元素的个数为1的情况,还有一些其他的场景】
3.注意中间变量mid的算法,防止其出现溢出现象。int mid = (left + right) / 2 修改为 int mid= left +(right- left )/2
int binarySearch(const int *arr, int len, int target)
{
int start = 0;
int end = len - 1;
while (start <= end) {
int mid = start + (end - start) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] > target) {
end = mid - 1;
} else {
start = mid + 1;
}
}
return -1;
}
void test01()
{
int arr[] = {1, 2, 3, 4, 5};
int len = sizeof(arr) / sizeof(int);
int index = binarySearch(arr, len, 4);
if (index != -1) {
printf("index = %d\n", index);
} else {
printf("not find\n");
}
}















 4111
4111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









