






1.目标
分组求TopN是大数据领域常见的需求,主要是根据数据的某一列进行分组,然后将分组后的每一组数据按照指定的列进行排序,最后取每一组的前N行数据。
2.准备工作
2.1启动集群的HDFS与Spark
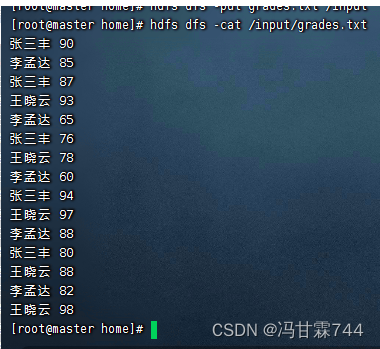
2.2编辑并上传grades.txt 到hdfs
3.新建Maven项目
创建项目
将java目录改成scala目录
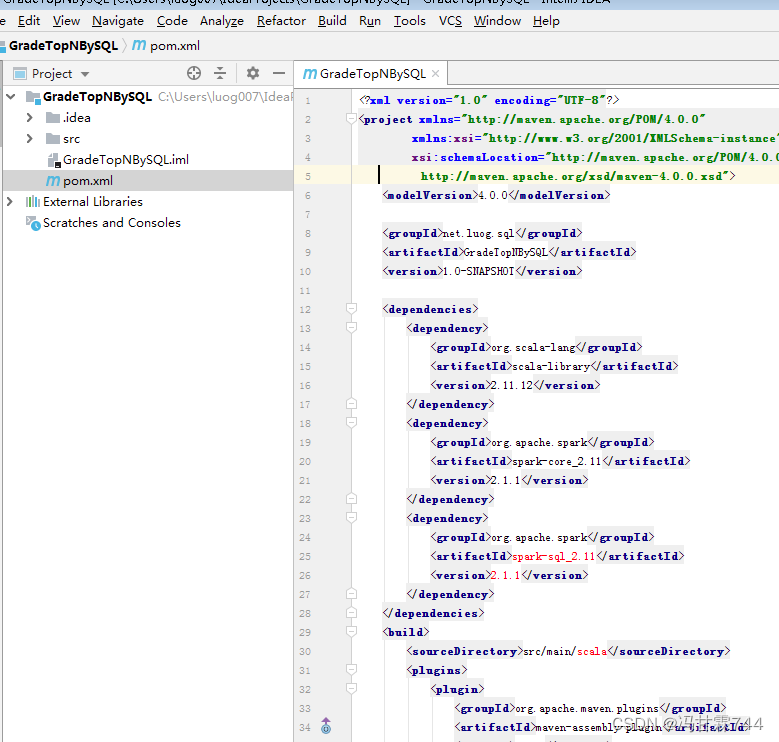
4.添加相关依赖和构建插件
5.创建日志属性文件
6.创建分组排行榜单例对象
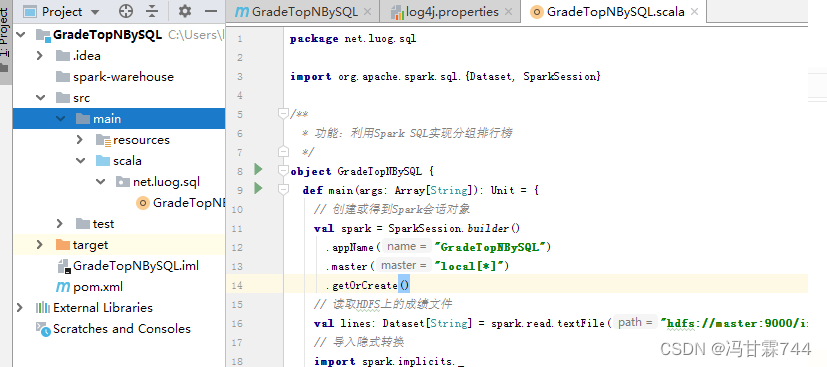
package net.luog.sql
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* 功能:利用Spark SQL实现分组排行
*/
object GradeTopNBySQL {
def main(args: Array[String]): Unit = {
// 创建或得到Spark会话对象
val spark = SparkSession.builder()
.appName("GradeTopNBySQL")
.master("local[*]")
.getOrCreate()
// 读取HDFS上的成绩文件
val lines: Dataset[String] = spark.read.textFile("hdfs://master:9000/input/grades.txt")
// 导入隐式转换
import spark.implicits._
// 创建成绩数据集
val gradeDS: Dataset[Grade] = lines.map(
line => { val fields = line.split(" ")
val name = fields(0)
val score = fields(1).toInt
Grade(name, score)
})
// 将数据集转换成数据帧
val df = gradeDS.toDF()
// 基于数据帧创建临时表
df.createOrReplaceTempView("t_grade")
// 查询临时表,实现分组排行榜
val top3 = spark.sql(
"""
|SELECT name, score FROM
| (SELECT name, score, row_number() OVER (PARTITION BY name ORDER BY score DESC) rank from t_grade) t
| WHERE t.rank <= 3
|""".stripMargin
)
// 显示分组排行榜结果
top3.show()
// 按指定格式输出分组排行榜
top3.foreach(row => println(row(0) + ": " + row(1)))
// 关闭Spark会话
spark.close()
}
// 定义成绩样例类
case class Grade(name: String, score: Int)
}
7.本地运行程序,查看结果
















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









