






目录
④creator_trx_id(创建当前Read View的事物的id):
第一步,事物B执行读取操作(select语句)的时候,会创建一个Read View
为什么在t4时刻,也就是第二次创建Read View的时候,读不到事物A还没有提交的数据呢?
一、什么是MySQL的事物?
事物,指的是在特定的业务场景当中,为了保证一组数据库操作,要么全部成功,要么全部失败。
举个例子:小明给小红转账500元,
执行两组sql语句:
update account set money=money-500 where name='小明';
update account set money=money+500 where name='小红';
如果这条SQL语句当中,执行完第一条数据,但是突然断网了,或者数据库服务器崩溃了,那么这个时候,就有可能导致,小明的钱财少了500元,但是这500元并没有打到小红的账户上面,也就是说,这500元不翼而飞了......如果真的断网了,或者数据库崩溃了,按道理来说,应当把小明扣回去的钱加回去,这样才不会导致钱财的损失。如果把这两条sql语句组合成一个事物,那么就不会发生钱财不翼而飞这种情况。
二、事物的四大特性:
①原子性:
指的是,每一个事物都是不可再分的最小单位,要么全部执行成功,要么全部失败回滚。不存在中间态。
②一致性:
指的是,事物执行前和事物执行之后,数据库必须处于一致性的状态,只要事物不提交,就不会改变此数据库的状态。
③持久性:
事物一旦执行成功,就无法回滚回去,对磁盘的数据更改是持久的状态。
④隔离性(重难点):
事物的执行过程,是与外界完全隔离的。
事物在提交之前,具体的细节不会被其他事物发现
自身所作出的更改,在事物提交之前,也不会被其他的事物捕获/修改到。
三、事物的隔离级别:(按照由低到高)
首先,了解一下事物在并发环境下面,会出现的3个问题:
脏读:一个事物当中,读到其他事务未提交的数据;
不可重复读:一个事物当中,执行两次相同的查询操作,前后读取的数据不一致;
幻读:一个事物当中,执行两次相同的查询操作,前后读取的记录数量不一致。
①读未提交:
指的是,一个事物没有提交,就可以被其他的事物所捕获;这么说好像有点抽象hhh,那我再举个形象一点的例子:假设老师在办公室在办公室改卷子。他给小明打了90分(这是一个事物),这个时候,小明正好过来,他看到了自己的成绩并把自己的成绩报告给好朋友小华:我考了90分。(这是第二个事物)但是老师过了一会儿,又把小明的成绩改成95分,但是小华得到的信息仍然是小明考了90分,其中小华得到的消息是错误的,这个也就是脏数据。
如图所示:
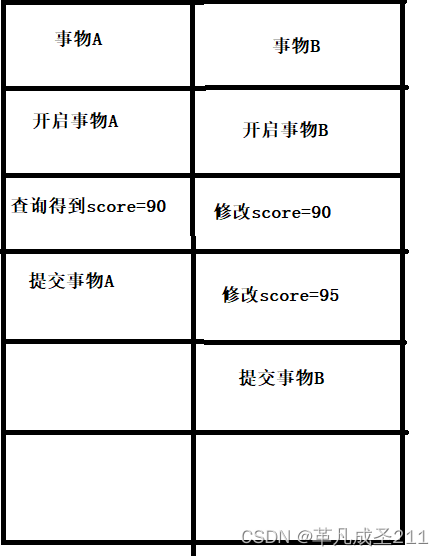
此时,事物A得到的score=90,然而最终事物B的修改为95,那么事物A的数据被称为脏数据,也成为脏读
(存在脏读,不可重复读,幻读的问题)
②读已提交:
还是回到刚刚那个场景,如果老师制定了一条规矩,那就是只有当我改完试卷之后,才会让学生知道成绩,那这样,小明就不可以在老师改卷的时候看到自己的成绩了。
因此,重新定义一下读已提交:
就是一个事务要等另一个事务提交后才能读取数据(解决脏读),但是存在不可重复读的问题,比如一个事务存在两次读取,中间存在其他事务的修改,导致读取数据不一致。
(存在不可重复读和幻读的问题)
如果一个事务只能读取到另一个已提交事务修改过的数据,并且其它事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值,那么这种隔离级别就称之为读提交。
该隔离级别满足了隔离的简单定义:一个事务从开始到提交前所做的任何改变都是不可见的,事务只能读取到已经提交的事务所做的改变。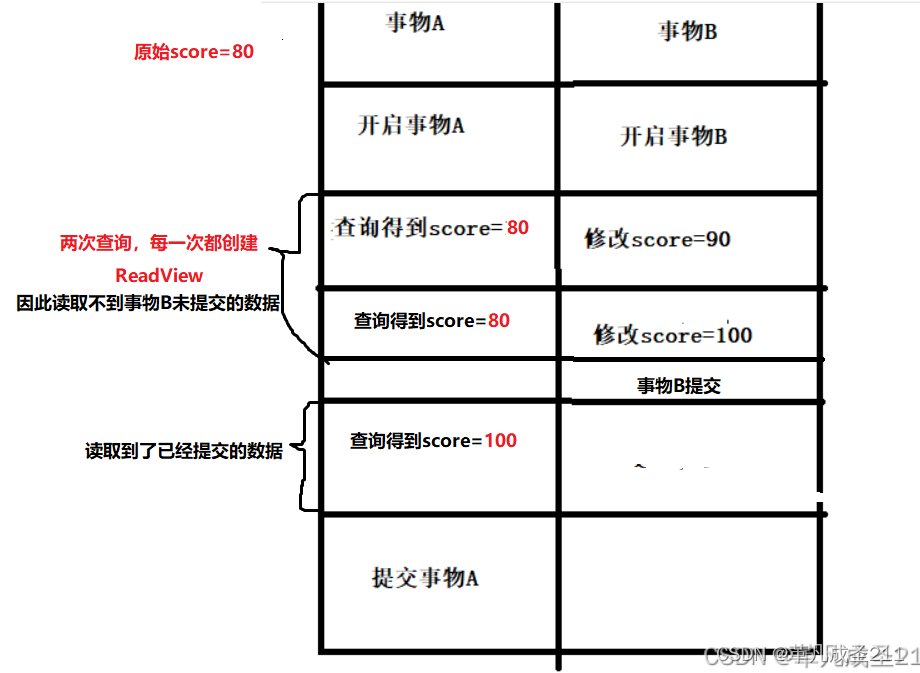
③可重复读:MYSQL默认的隔离级别。
再次回到刚才的场景,如果老师把成绩发布出去了,贴到班级的墙上,这个时候同学们蜂拥而至,一起来查看自己的成绩。但是突然,老师说有一部分同学的成绩出错了,需要改动。那么这个时候,就比较扫同学们的兴,因此,同学们提出了要求:无论成绩对错,也一定要等我们看完之后,老师才可以改,在我们查看自己成绩的时候,老师不要改动。因此,这样的操作也就是相当于给“读”的操作加了锁,只有读完了,才可以继续改动。
重复读,就是在开始读取数据(事务开启)时,其他事物的修改操作都无法被查看到。(解决了不可重复读的问题)
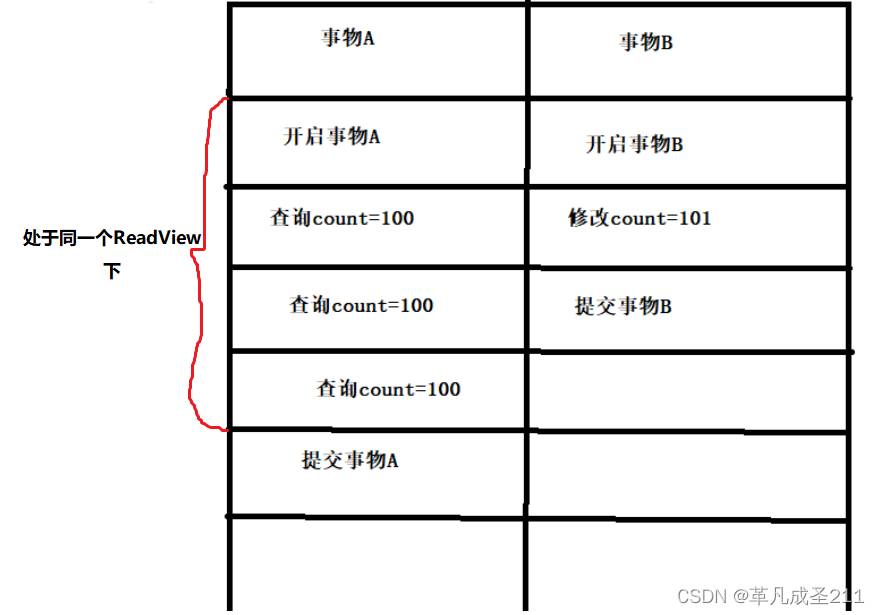
可重复读是怎样避免幻读现象发生的?
可重复读,可以很大程度地避免幻读现象的发生,因此,mysql很少会采用串行化的方式来处理请求。
方案一:针对快照读(也就是普通的selec*from table where id=...)这样的语句,是通过MVCC的方式来解决幻读问题的,也就是产生一个Read View(后面会提到)
因为可重复读的隔离级别下面,即使中途有其他事物提交了这个数据,那么对于当前数据来说也是不可见的。
方案二:针对当前读(例如select ... for update)这样的语句,是通过加锁的方式来解决幻读问题的,加的是记录锁+间隙锁。
当执行select...for update语句的时候,会加上一个next-key lock。
如果其他事物想在这个范围内插入数据,那么插入的语句就会被阻塞。
对于当前读,它总可以读取到最新的数据。因为,select...for update会让快照失效
④串行化
也就是说,在读数据的时候,任何其他事物写的操作无法被当前事物查看。在写数据的时候,任何读的操作也不可以被执行,相当于对读和写都加了锁,彻底消除并发。
所有的事物,都是单线程执行,不存在同时执行多个事物的情况。
串行化,解决了幻读的问题:
幻读,就是某个事物两次查询同一个数据,但是由于有其他的数据新增,两次查询的结果的条数不一样。多出来的数据就好像”幻觉“一样。
事物隔离级别与对应级别下面会产生的问题:
| 事物隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交 | √ | √ | √ |
| 读已提交 | × | √ | √ |
| 可重复读 | × | × | √ |
| 串行化 | × | × | × |
四、事物的四大特性,是如何保证的?
①原子性:
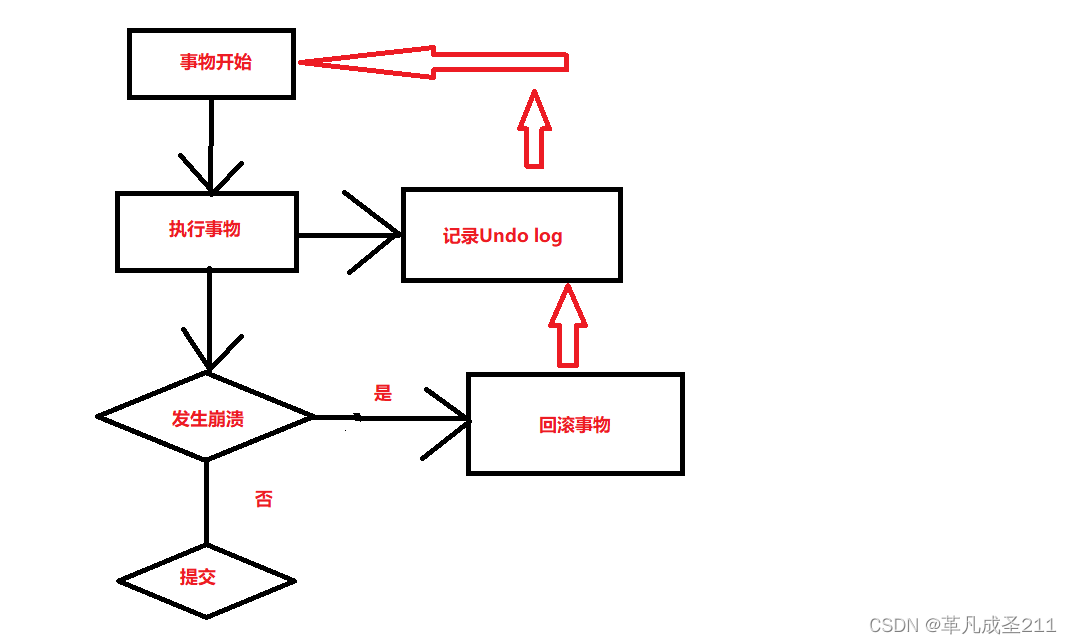
原子性,是通过undo log(回滚日志)来实现的。
undo log是一种用于撤销回退的日志。在事物还没有提交之前,MySQL会先记录更新前的数据到undo log日志当中。当事物执行到一部分,发生了异常情况,需要回滚的时候,就可以利用undo log来执行回滚操作。
图解:
②持久性
是通过redo log(重做日志)来实现的
保证事物在执行的过程当中,不会因为mysql宕机而产生事物的丢失。
③隔离性
通过MVCC(多版本并发控制)或者mysql当中的各种锁机制来保证的。
④一致性
通过持久性+原子性+一致性来保证的。
五、事物的隔离级别,是怎样实现的?
①读未提交
因为当前事物,可以读到事物没有提交的数据,因此无需加任何锁,也无需生成任何快照,就可以实现,但是存在脏读问题。
②串行化
对于串行化隔离级别是事物来说,是通过加读写锁的方式来避免并行访问的。
对于读写锁,它有以下三个特点:一般来说,读就是select语句,写就是insert/update/delete
读与读的sql语句,不会产生锁冲突,不会产生相互阻塞;
读与写的sql语句,会产生锁冲突,会相互阻塞;
写与写的sql语句,会产生锁冲突,会相互阻塞;
③读已提交&可重复读
这两种隔离级别,都是通过Read View来实现的。关于Read View,它其实就是一个数据快照,就好像照相机一样,对于一些场景进行瞬时地记录。
读已提交,可以认为:这个快照,是在每一条sql语句执行之前生成的,当执行完成之后,又会重新生成一个Read View。
而可重复读的隔离级别,是在事物开启的时候,生成一个Read View,然后后续事物的执行过程,都会以这个Read View的内容为基础。
六、认识ReadView
ReadView有4个重要的字段:
下图来源于《小林coding》
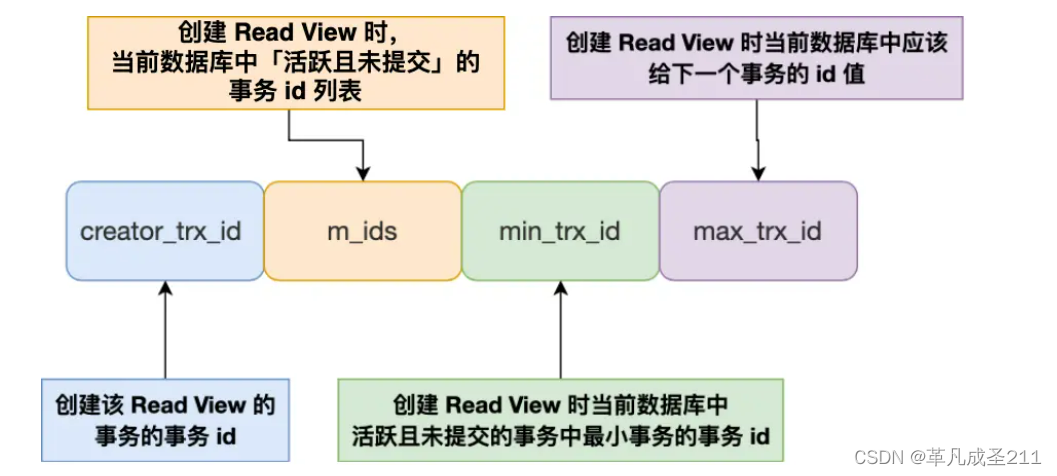
①m_ids(活跃事物id):
指的是创建Read View的时候,活跃事物的id:
当前数据库当中:已经启动但是还没有提交的事物的id
②min_trx_id(活跃事物id的最小值):
指的是活跃事物id的最小值。
③max_trx_id
这一个字段并不是活跃事物的id的最大值,而是创建Read View的时候,当前数据库中应该给下一个事物的id。也就是说,下一个事物即将开启的时候,它的id,也就是全局事物的id值+1.
④creator_trx_id(创建当前Read View的事物的id):
要知道,Read View创建,需要一个事物的启动。
一个Read View一定对应一个事物。那么,在Read View当中的creator_trx_id字段,就是创建Read View的事物的id。
了解了这四个字段之后,还需要了解,mysql当中,和Read View有关的两个字段:
【MYSQL面试常问系列】mysql的一行数据是怎样存储的_革凡成圣211的博客-CSDN博客_mysql行存储![]() https://blog.csdn.net/weixin_56738054/article/details/128510525?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_56738054/article/details/128510525?spm=1001.2014.3001.5501
一个是trx_id,另外一个是roll_pointer,在这一篇文章当中,已经详细介绍了。
在这里再提醒一下,只有insert、delete、update操作才会对这一行数据的trx_id进行改动。任何的read操作,比如select语句,是不会对这一行数据的trx_id进行改动的。
Read View的工作过程(与MVCC有关系)
一个事物创建好MVCC,去访问某一条记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
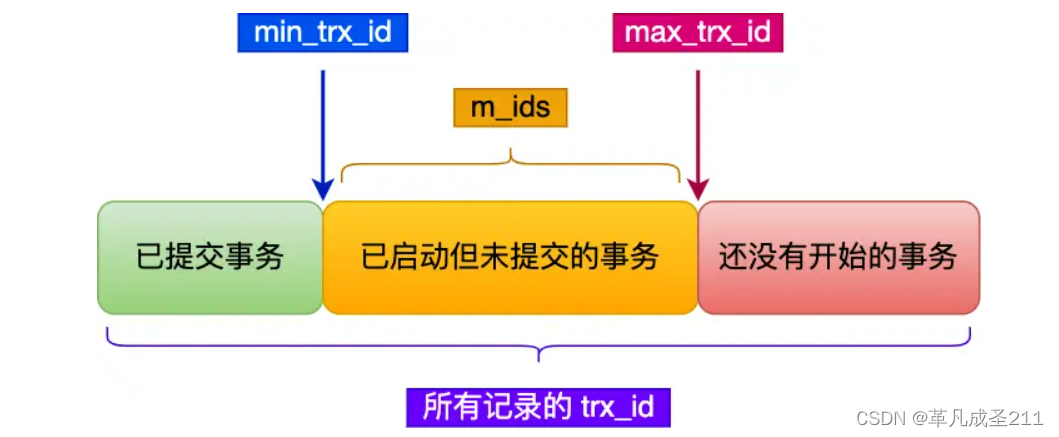
情况一、
如果在mysql表的这一行当中,记录的trx_id的值小于Read View中的min_trx_id的值,表示这个版本的记录时在创建Read View之前已经提交的事物生成的。
该版本的记录,对于当前的事物可见。
如果trx_id的值和当前Read View的事物id的值一样,那么这一行的记录对于当前事物可见。
情况二、
如果这一行记录的trx_id的值大于等于Read View的max_trx_id值的时候,表示这个版本的记录是在创建Read View之后才启动的事物生成的。
因此该版本的记录对于当前事物不可见。
情况三、
如果记录的trx_id值在当前Read View的
min_trx_id和max_trx_id之间的时候,需要判断trx_id是否在当前Read View的m_ids列表当当中.
①如果记录的trx_id在Read View的m_ids列表当中,表示生成当前trx_id该版本的事物仍然活跃着,因此该版本对于当前事物不可见,当前事物无法访问这一行的数据。
②如果记录的trx_id不在Read View的m_ids的列表当中的话,表示生成这个版本记录的活跃事物已经被提交,因此这一行数据可以被当前事物访问。
这种通过版本链来控制并发事物访问同一个记录时候的行为就被称为MVCC(多版本并发控制)
情况四、
如果当前事物的id正好是ReadView的事物id,那么这一行的数据也会被当前事物可见。
可重复读的工作过程
可重复读的隔离级别是启动事物的时候,生成一个Read View,然后整个事物后续的过程,直到提交之前,都在使用这个Read View。
假设此时启动了A、B两个事物,id编号分别为51、52,分别创建了两个Read View。
继续偷一下小林哥的图~~【dog】
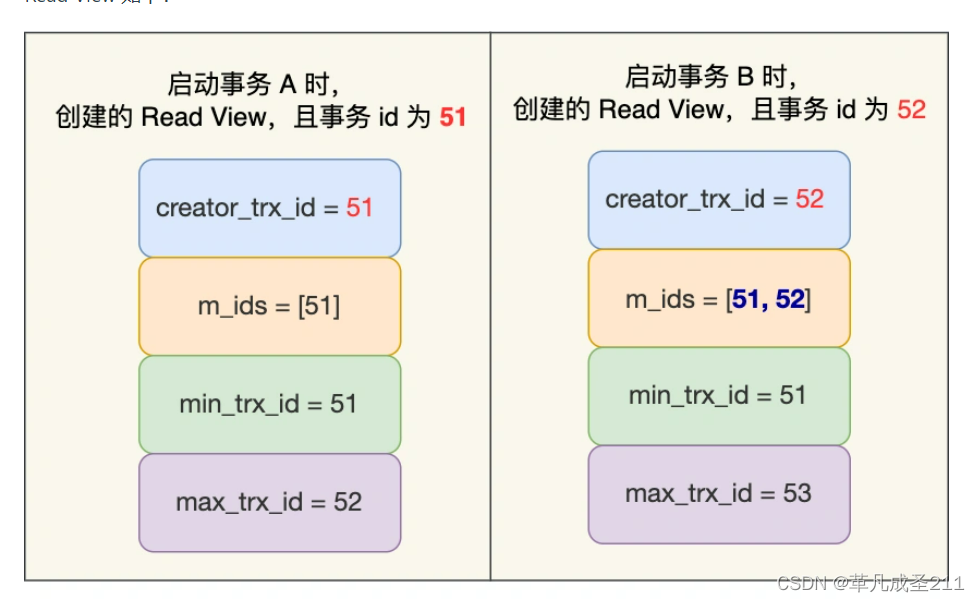
对于上面两个Read View,事物A与事物B的Read View的具体内容分析过程如下:
对于事物A:
在事物A的Read View当中,
(Ⅰ) 事物id(creator_trx_id):51
它的事物id为51。
(Ⅱ)最小活跃事物id(min_trx_id):
由于事物A为第一次启动的事物,因此此时活跃事物的事物id列表就只有51,最小也是51;
(Ⅲ)活跃事物id(m_ids)
由于此时,只有事物id为51的事物是活跃的,因此,活跃事物id为51.
(Ⅳ)最大事物id(max_trx_id)
下一个待开启事物id为52,这个没什么好说的,就是51+1=52
对于事物B:
在事物B的Read View当中,它的事物id为52,由于事物A是活跃的,事物B也是活跃
的,因此在事物B的Read View当中,活跃事物id为一共两个:[51,52]
同理,最小活跃事物id为51,max_trx_id为53。
什么是可重复读(回顾)
假如某一条记录如下:
| id | name | balance | trx_id | roll_pointer |
| 1 | JIM | 1000000 | 50 | O |
回顾一下,如果在可重复读的隔离级别下面,会按照下面的顺序来执行:
| 时间轴 | 事物B | 事物A |
| t1 | 开启事物B | 开启事物A |
| t2 | select:balance:1000000 | |
| t3 | update:balance:2000000 | |
| t4 | select:balance:1000000 | |
| t5 | commit | |
| t6 | select:balance:1000000 | |
| t7 | commit |
可以看到,在t6时刻,事物A读取到的数据仍然是100W,即使事物B提交了,但是事物A仍然读取到的还是事物A刚刚开启时候,这一个快照Read View下面的数据
工作过程:
事物B第一次读小林的账户余额记录的时候,在找到记录之后,会首先看一下这一行的trx_id
第一步:由于trx_id<事物B的事物id:51。这样,也就意味着,trx_id为50的记录早于当前的事物,因此可以访问这一行记录,无需阻塞。
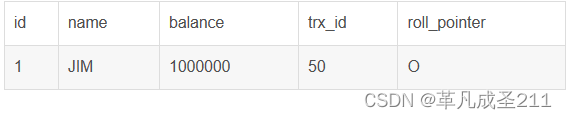
第二步:事物A开启了,并且通过update语句尝试修改这一行的数据,此时还未提交数据
此时,balance会变成200W。这个时候,myql会记录相应的undolog,并且以链表的形式串联起来,形成版本链。注意:此时修改的事物还没有提交!!!!
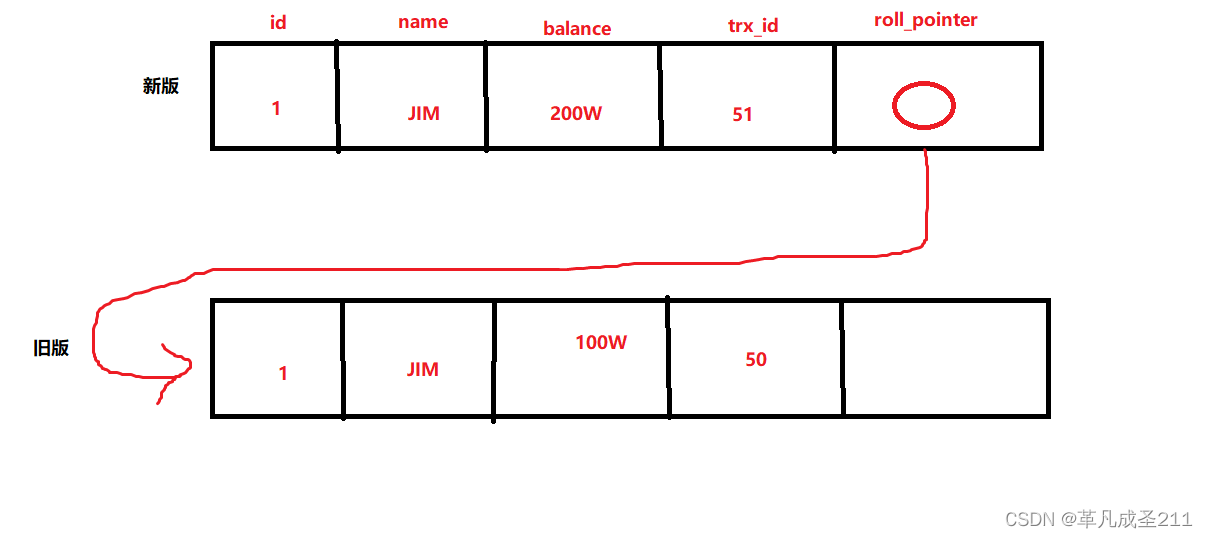
从上图可以看到,新的事物A修改了该记录,以前的记录就变成了旧版的了,于是新版的记录就和旧版的记录通过链表的方式串起来,而且最新的trx_id是事物A的事物id(trx_id=51)
然后,事物B第二次去读取记录,发现此时的trx_id为51。
由于51这个值在事物B的min_trx_id和max_trx_id之间,因此就需要查询51这个值是否在事物B的Read View的m_ids范围之内。
事物B的活跃事物id:m_ids的范围为【51】,正好在这个范围当中
说明这条记录是被还未提交的事物修改的
因此,事物B是不会读取这一条的数据的,事物B会沿着undo log链条找到旧版本的记录。直到找到比事物B的Read View的min_trx_id小的版本,也就是版本号为【50】的记录
最后,当事物A提交之后,由于当前的隔离界别为【可重复读】
因此,事物B仍然还是会基于启动任务时候创建的Read View来判断当前版本记录是否可见。
读已提交是如何工作的
回顾一下读已提交的工作过程:
还是刚才的那一行数据
| id | name | balance | trx_id | roll_pointer |
| 1 | JIM | 1000000 | 50 | O |
读已提交的工作过程:
读已提交隔离级别,不是在事物开启的时候生成一个Read View,而是在每一次读取的时候,都生成一个Read View。
| 时间轴 | 事物B | 事物A |
| t1 | 开启 | 开启 |
| t2 | (创建Read View)读取到balance为100W | |
| t3 | 修改balance为200W | |
| t4 | (创建Read View)读取到balance为100W | |
| t5 | commit | |
| t6 | (创建Read View)读取到balance为200W |
第一步,事物B执行读取操作(select语句)的时候,会创建一个Read View
此时开启一个事物B,会在事物B的Read View当中,指定4个字段
第一个:creator_trx_id=52;
第二个:由于事物A已经开启,因此,在m_ids当中,会生成一个区间,存放两个活跃的事物ID,一个是事物A的,另外一个是事物B的
第三个:最小事物id,为51。

第二步:事物A执行修改数据
除了修改balance为200W,也会修改这一行的trx_id为51,也就是修改事物A的id,也就是事物A的id
但是此时事物A还没有提交。
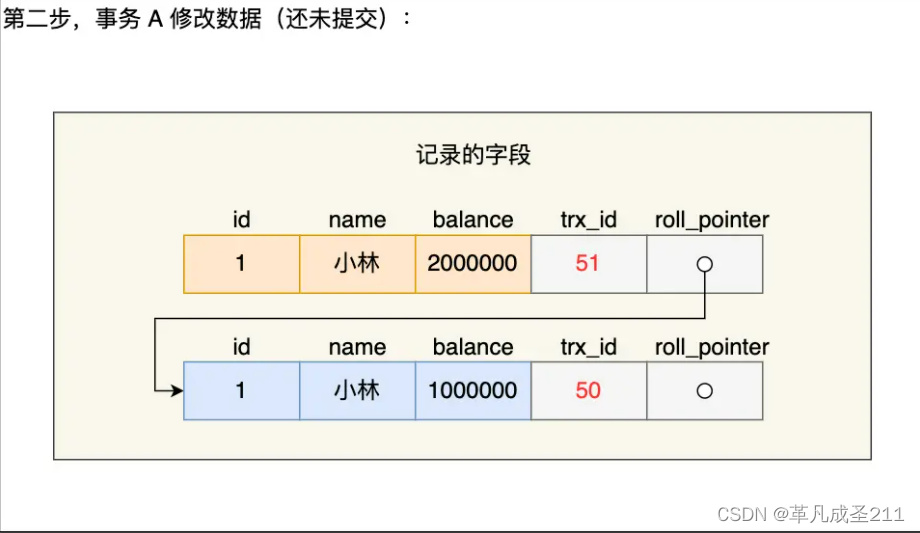
第三步:
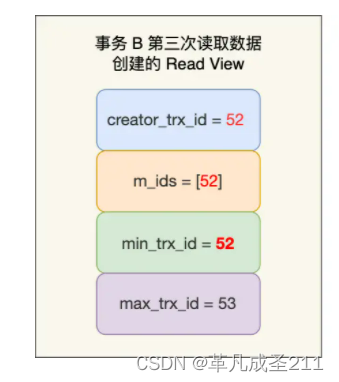
事物B读取数据,启动事物B之后,读取数据之前继续创建Read View,此时,由于事物A还没有提交,因此活跃事物id仍然为[51,52]

为什么在t4时刻,也就是第二次创建Read View的时候,读不到事物A还没有提交的数据呢?
跟前面不可重复读的道理一样,因为此时trx_id的值为事物A的值,trx_id正好在事物B的Read View的活跃事物id当中。因此事物B会沿着undo log链条,找到比事物B的id小的值。也就是找到50的记录,然后读取第二次数据
为什么事物A提交之后,事物B可以读取到最新的值呢?
当事物A提交之后,事物B对应的Read View当中,活跃事物id这一栏,已经没有事物A的id了,只有事物B的id。
此时,只有事物B仍然活跃。
然而,在真实存储的这一行当中, trx_id的值为最后修改的事物id的值,为51.
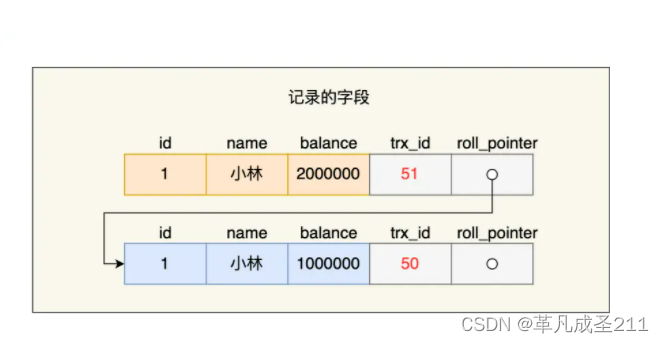
由于此时trx_id为51,小于52。因此,这就意味着,事物B会读取这一行被事物A更新的数据。















 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









