







前言
参考:
《动手学强化学习》作者:张伟楠,沈键,俞勇
动手学强化学习 网页版
动手学强化学习 github代码
动手学强化学习 视频
强化学习入门这一篇就够了!!!万字长文(讲的很好)
+
参考:
强化学习入门(第二版)读书笔记
小总结(前文回顾)
先简单总结一下第一章所学的知识点:
我做了一个思维导图很方便理解
之后学习完会在这里一直更新。
自己学习时做的笔记:https://github.com/wild-firefox/Hands-on-RL
补充一下要下载的库
#第5章
pip install tqdm
#第7章
pip install torch
pip install gymnasium
这里仅记录下学习时遇到的问题,已经学了一个月了,只是忙于毕设没空来更新一下学习进度,发现踏入门槛后学习强化学习就轻松了,当然还有一些实验时学到的一些小细节,准备下个博客再更。
0.26.2版本gym环境问题
将原代码修改三处:
第1、2处:
将训练的函数改为如下:(同理off_policy也是如此)
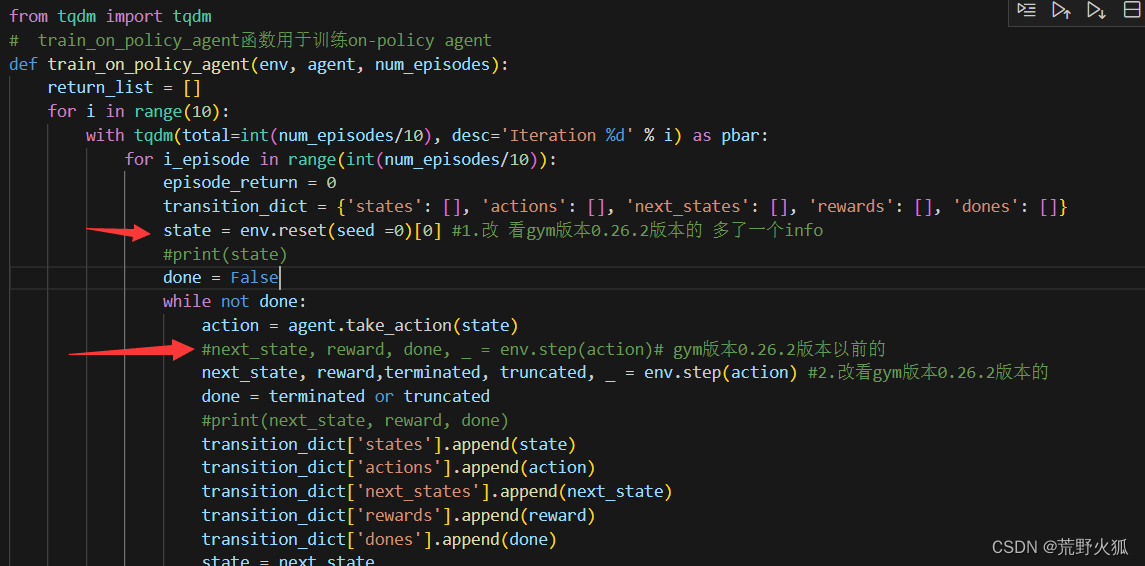
第3处:
这里注释掉,seed =0 改到为上图的在env.reset()的函数里。

问题1[第8章DQN]:
第8章:DQN改进算法

问题1:画红色横线这句话没看懂。
答:
首先:由于V值加上任意常量,并且在A中减去这个任意常量,由于这个常量的不确定,导致V不能反映state值,A不能反映advantage值。所以要将公式改成-maxA的形式。(就是将这个常量定为maxA的意思,也就得到了V=Q+maxA = maxQ)
此时已经默认优势函数A-maxA。
而这句话意思是:强制A-maxA =0,即就是A = maxA。
通俗来说,就是限制了这个常量为一个定值,取为maxA,当此时的A=maxA(下一个状态的)时,V= maxQ。
问题2[第9章策略梯度]:
第9章:策略梯度算法

问题2:上图箭头这里的t是不是对应下图的代码这里?
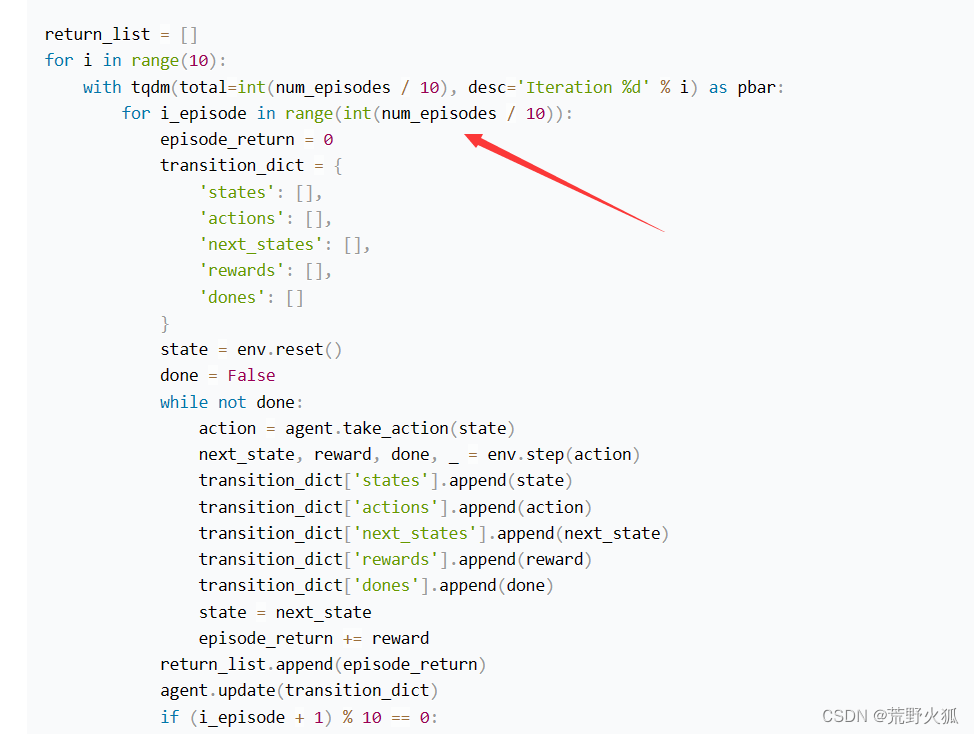
答:不是,上图的意思是:每次从一个新的序列开始时,状态重置reset,return为0,可以看作每次一个序列开始时,代表的意思是在伪代码中:for e =1 ->E do。
上图伪代码的t在代码中代表是意思是下图中的i,即计算当前一个序列eposide结束后,在更新时得到的return总和G。

问题3[第10章AC]:
第10章 A-C算法

问题3:这里箭头对应下面代码这里是没错,
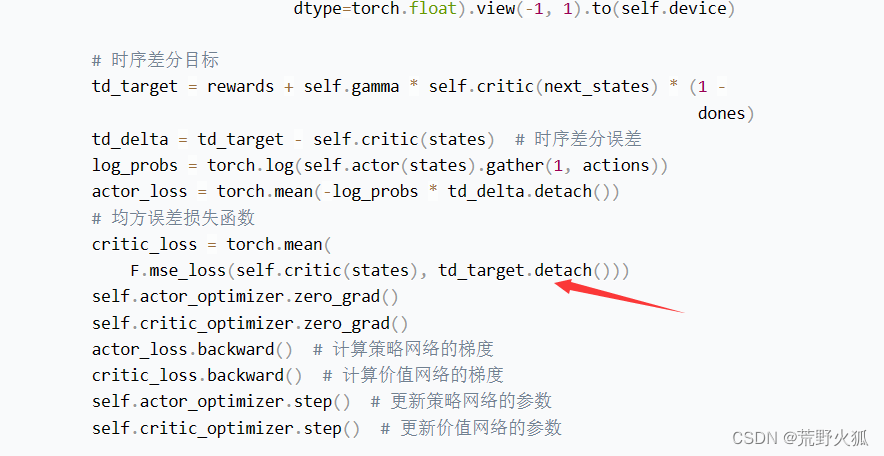
为什么下面图中,方框内td_delta也要加detach,(即不需要加梯度信息)?
(detach() 为去掉梯度信息,训练时不训练。)

答:
根据伪代码:

td_delta 在求梯度的符号的左边 所以不求梯度 加detach
td_target 只对状态函数(w参数的函数)求梯度,而不对时序差分目标求梯度, 加detach。
对应到代码里解释:
actor_loss只对log_prob求梯度
critic_loss只对self.critic(states)求梯度
经过训练测试后
原代码结果:(都加detach)

td_delta 不加detach(),td_target加detach(),测试结果如下:

此时我看出第二张图的效果怎么比第一张图好?
加大eposide到3000:
原文:

td_delta 不加detach(),td_target加detach(),测试结果如下:
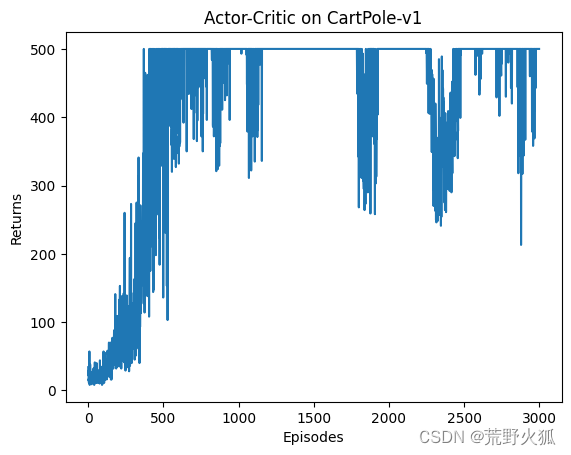
结论:原文代码是对的。
出现单次效果时,不能妄下结论,要通过加不同随机种子求均值或加大eposide来验证。
后续又测试了td_target加 和不加的情况:
td_delta 加detach(),td_target不加detach():

两者都不加:
出现报错:
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
翻译为:
RuntimeError:试图第二次向后遍历图(或者在已释放的张量之后直接访问已保存的张量)。当您调用.backward()或autograd.grad()时,将释放图中保存的中间值。如果需要第二次向后遍历图,或者在调用backward后需要访问保存的张量,则指定retain_graph=True。
参考:深度学习框架拾遗:【Pytorch(七)】——Pytorch动态计算图
了解了计算图,对这个错误的一点理解:
当着两个都进行梯度计算时,在首先进行的actor的反向传播中,结束时删除了计算图,此时的计算图包含了critic的反向传播中要进行计算的值td_target和self.critic(states)信息。
至于为什么此时计算图中包含了信息td_target和self.critic(states)?是因为在计算actor_loss时利用到了两者的信息。
而原本都带有detach时,计算图中td_delta和td_target保留了下来,然后计算他们所需要的参数也保留了下来,所以可以继续计算backward(),不会报错。
结论:原文代码没错。
追问:
想了下,为什么我会出现这个问题。
原因是前面几章的代码从来没有出现过detach()的说法,且原文没有解释为什么这里会出现detach()。
于是我翻看了一下前几章的原理,发现有些地方也确实根据原理也要加上detach而没有加,
比方说DQN的代码的这里:(类似的还有DDPG的代码)

我这里加上后:进行训练后和原文不加上的进行比对,发现结果一模一样。不知道为什么会如此。
最终解决
–2024.5.17–
后来请教了一下同门,发现原来自己前面的知识有个点忘记了:DQN和DDPG有两层网络:Critic网络和Critic Target网路,在定义adam优化器时,只对Critic网络进行优化而不对目标网络进行优化。
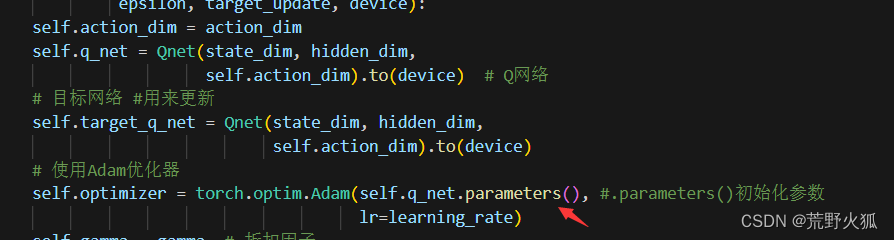
而在原代码处,td_target是由目标网络计算得出(来源于目标网络),所以在更新梯度时不会对原网路进行更改,因为只对原网路进行梯度更新,故,这里加不加都不会改变结果,最好是加一下,因为更符合原理。
而为什么在AC网络中,两个td_delta和td_target都必须要加detach?是因为在优化器只优化原网络的前提下,他们都是由原网络计算得出,故他们都会对参数的梯度更新有影响,且根据原理,他们也必须加上detach。
总结:在写代码的时候,看某个值要不要加detach ,看两个方面:
1.(影响因素)看优化器优化的是哪个网络:如果这个值不是由优化的网络计算得出,那这个值加不加detach不影响结果;如果是由优化的网络计算得出,则看下一个因素。
2.(决定因素)看算法的原理,如果这个值是由优化的网络计算得出,那么在计算损失的时候,基本上都是要加detach的,因为只对有参数(w)的函数进行梯度下降。(目前到第13章都适用。)
补充一点

第一个mean必须加上,因为backward()的必须是个标量(损失函数输出为一个标量),求mean这里意思为求期望。
第二个mean可加可不加,因为mse均方差损失函数已经有求均值的操作了。















 1980
1980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









