






一、关闭 Linux 防火墙和 SELniux 服务
1.关闭防火墙
# systemctl stop firewalld.service
# systemctl disable firewalld.service
2.关闭 SELinux 服务
# vi /etc/sysconfig/selinux将 SELINUX= enforcing 改为 SELINUX=disabled

退出后:
# setenforce 0二、安装 JDK(CentOS7 JDK 安装)(在上一期博客中,这里不在过多赘述)
三、安装 Hadoop
1.进入 opt 文件创建 hadoop 文件夹
# cd /opt上传 hadoop 到 /opt 文件夹

2.解压安装 hadoop
# tar -zxvf hadoop-2.9.2.tar.gz3.配置 hadoop 环境
# vi /etc/profile //内容如下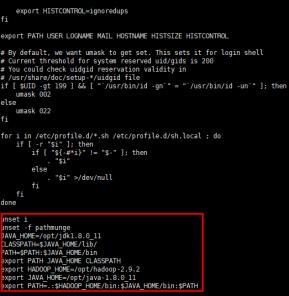
JAVA_HOME=/opt/jdk1.8.0_11
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
export HADOOP_HOME=/opt/hadoop-2.9.2
export JAVA_HOME=/opt/jdk-1.8.0_11
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
# source /etc/profile
# vi /opt/hadoop-2.9.2/etc/hadoop/hadoop-env.sh

export JAVA_HOME=/opt/jdk1.8.0_11
# source /etc/profile //配置变量
# whereis hdfs //验证环境变量
查看 hadoop 版本
# cd hadoop-2.9.2 //重要步骤,如果不进入 hadoop 文件夹则无法实现查看命令
# ./bin/hadoop version

使用 mapreduce 测试 Word Count (文字计数)
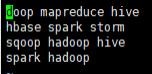
# sudo vi /home/suyu/data.input //打开后输入下列文字
doop mapreduce hive
hbase spark storm
sqoop hadoop hive
spark hadoop
//:wq 保存退出
使用下列代码: mapreduce 模块在这里的作用就是统计 data.input 文件中各个单词出现的次 数。输出为 output
# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /home/suyu/data.input output# cd ./output //进入 output 目录# ls –l //使用 ls -l 查看目录文件
# cat part-r-00000//查看统计数据 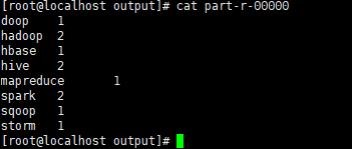
















 209
209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











