







蚁群算法(Ant Colony Optimization, ACO)
目录
一、算法起源
1.1 生物学基础
- 蚂蚁觅食行为:自然界蚂蚁通过释放**信息素(Pheromone)**标记路径,较短路径因信息素累积更快,吸引更多蚂蚁选择,形成正反馈。
- 自组织特性:单个蚂蚁行为简单,群体涌现出智能协作能力。
1.2 提出与发展
- 1992年:Marco Dorigo首次提出用于解决旅行商问题(TSP)。
- 2000年后:拓展到组合优化、机器学习、网络路由等领域。
二、核心思想
2.1 正反馈机制
- 路径强化:高质量路径(如更短距离)的信息素浓度更高。
- 挥发机制:信息素随时间挥发,防止算法过早收敛到局部最优。
2.2 分布式计算
- 并行搜索:多只蚂蚁独立探索不同路径。
- 无中心控制:仅依赖局部信息素浓度决策。
三、数学模型
3.1 路径选择概率
蚂蚁
k
k
k在节点
i
i
i选择下一节点
j
j
j 的概率:
P
i
j
k
=
[
τ
i
j
]
α
⋅
[
η
i
j
]
β
∑
l
∈
允许节点
[
τ
i
l
]
α
⋅
[
η
i
l
]
β
P_{ij}^k = \frac{[\tau_{ij}]^\alpha \cdot [\eta_{ij}]^\beta}{\sum_{l \in \text{允许节点}} [\tau_{il}]^\alpha \cdot [\eta_{il}]^\beta}
Pijk=∑l∈允许节点[τil]α⋅[ηil]β[τij]α⋅[ηij]β
- τ i j \tau_{ij} τij:边 ( i , j ) (i,j) (i,j) 的信息素浓度
- η i j = 1 / d i j \eta_{ij} = 1/d_{ij} ηij=1/dij:启发式函数 ( d i j (d_{ij} (dij为节点间距离)
- α \alpha α:信息素权重因子(通常 α ≥ 0 \alpha \geq 0 α≥0)
- β \beta β:启发式信息权重因子(通常 β ≥ 1 \beta \geq 1 β≥1)
3.2 信息素更新规则
全局更新(所有蚂蚁完成路径后):
τ
i
j
←
(
1
−
ρ
)
⋅
τ
i
j
+
∑
k
=
1
m
Δ
τ
i
j
k
\tau_{ij} \leftarrow (1-\rho) \cdot \tau_{ij} + \sum_{k=1}^m \Delta \tau_{ij}^k
τij←(1−ρ)⋅τij+k=1∑mΔτijk
Δ
τ
i
j
k
=
{
Q
/
L
k
若蚂蚁k经过边
(
i
,
j
)
0
其他
\Delta \tau_{ij}^k = \begin{cases} Q / L_k & \text{若蚂蚁k经过边}(i,j) \\ 0 & \text{其他} \end{cases}
Δτijk={Q/Lk0若蚂蚁k经过边(i,j)其他
- ρ \rho ρ:信息素挥发率 ( 0 < ρ < 1 (0 < \rho < 1 (0<ρ<1)
- Q Q Q:信息素强度常数
- L k L_k Lk:蚂蚁 k k k 的路径长度
局部更新(可选,蚂蚁每走一步后):
τ i j ← ( 1 − ξ ) ⋅ τ i j + ξ ⋅ τ 0 \tau_{ij} \leftarrow (1-\xi) \cdot \tau_{ij} + \xi \cdot \tau_0 τij←(1−ξ)⋅τij+ξ⋅τ0
- ξ \xi ξ:局部挥发率
- τ 0 \tau_0 τ0:初始信息素值
四、算法流程
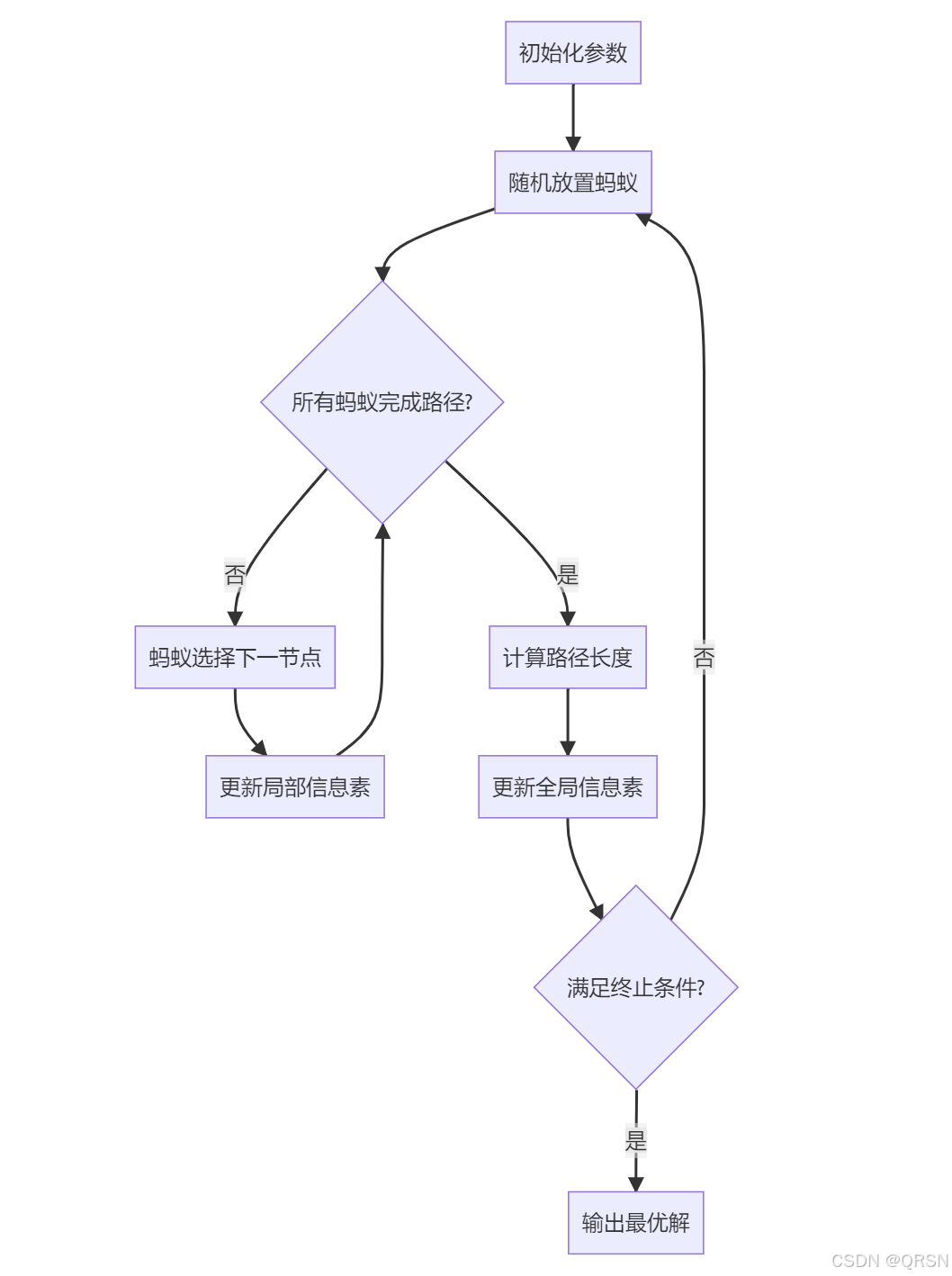
五、参数调优
| 参数 | 作用 | 典型取值 | 调整建议 |
|---|---|---|---|
| α \alpha α | 控制信息素的重要性 | 0.5 ~ 2 | 增大值强化已有路径依赖 |
| β \beta β | 控制启发式信息的重要性 | 1 ~ 5 | 增大值增强贪心搜索倾向 |
| ρ \rho ρ | 全局信息素挥发率 | 0.3 ~ 0.7 | 增大值提高算法探索能力 |
| Q Q Q | 信息素增强强度 | 10 ~ 100 | 与问题规模正相关 |
| 蚂蚁数量 m m m | 影响搜索空间覆盖度 | 10 ~ 50 | 过少易早熟,过多增加计算成本 |
六、改进变体
6.1 蚁群系统(Ant Colony System, ACS)
- 精英策略:仅最优蚂蚁更新信息素。
- 伪随机比例规则:以概率 q 0 q_0 q0 直接选择最优路径,否则按概率选择。
6.2 最大-最小蚂蚁系统(MMAS)
- 信息素边界限制: τ min ≤ τ i j ≤ τ max \tau_{\min} \leq \tau_{ij} \leq \tau_{\max} τmin≤τij≤τmax
- 仅全局最优蚂蚁更新信息素:防止早熟收敛。
6.3 自适应蚁群算法(Adaptive ACO)
- 动态参数调整:根据迭代进度自动调节 ρ \rho ρ 或 α \alpha α。
七、应用场景
| 领域 | 具体问题 | 优势 |
|---|---|---|
| 物流运输 | 车辆路径规划(VRP)、无人机配送路径优化 | 动态环境适应能力 |
| 通信网络 | 5G网络路由优化、数据中心流量调度 | 分布式计算优势 |
| 生产调度 | 车间作业排序、半导体晶圆制造排程 | 复杂约束处理能力 |
| 数据挖掘 | 特征选择、高维数据聚类 | 组合优化能力 |
八、优缺点分析
| 优点 | 缺点 |
|---|---|
| 1. 适应动态环境变化 | 1. 收敛速度较慢(需多次迭代) |
| 2. 天然支持并行计算 | 2. 高维连续问题效果受限 |
| 3. 避免局部最优能力强 | 3. 参数调优依赖经验 |
| 4. 无需目标函数梯度信息 | 4. 对离散问题更有效 |
九、代码框架(Python)
import numpy as np
class AntColony:
def __init__(self, distances, n_ants=20, alpha=1, beta=3,
evaporation_rate=0.5, Q=100):
self.distances = distances # 距离矩阵
self.n_ants = n_ants # 蚂蚁数量
self.alpha = alpha # 信息素权重
self.beta = beta # 启发式权重
self.evaporation = evaporation_rate # 挥发率
self.Q = Q # 信息素强度
def run(self, iterations=100):
pheromone = np.ones_like(self.distances) # 初始化信息素矩阵
best_path = None
best_length = float('inf')
for _ in range(iterations):
paths = self._generate_paths(pheromone)
pheromone = self._update_pheromone(pheromone, paths)
current_best = min(paths, key=lambda x: x[1])
if current_best[1] < best_length:
best_path, best_length = current_best
return best_path, best_length
def _generate_paths(self, pheromone):
paths = []
for _ in range(self.n_ants):
path = []
visited = set()
current = np.random.randint(len(self.distances)) # 随机起点
path.append(current)
visited.add(current)
while len(path) < len(self.distances):
probs = []
for city in range(len(self.distances)):
if city not in visited:
prob = (pheromone[current][city] ** self.alpha) * \
((1 / self.distances[current][city]) ** self.beta)
probs.append(prob)
else:
probs.append(0)
probs = np.array(probs) / np.sum(probs)
next_city = np.random.choice(len(self.distances), p=probs)
path.append(next_city)
visited.add(next_city)
current = next_city
path_length = self._calculate_length(path)
paths.append((path, path_length))
return paths
def _update_pheromone(self, pheromone, paths):
pheromone *= (1 - self.evaporation) # 挥发
best_path, best_length = min(paths, key=lambda x: x[1])
for i in range(len(best_path)-1):
city_a = best_path[i]
city_b = best_path[i+1]
pheromone[city_a][city_b] += self.Q / best_length
# 闭环路径更新
pheromone[best_path[-1]][best_path[0]] += self.Q / best_length
return pheromone
def _calculate_length(self, path):
return sum(self.distances[path[i]][path[i+1]] for i in range(len(path)-1)) \
+ self.distances[path[-1]][path[0]]
十、最新研究方向
-
多目标ACO
- 解决Pareto前沿优化问题(如同时最小化成本和时间的物流调度)。
-
混合算法
- 与深度学习结合:用神经网络预测信息素更新策略。
- 与强化学习结合:动态调整参数(如Q-learning控制 α \alpha α和 β \beta β)。
-
GPU加速
- 利用并行计算处理超大规模问题(如百万级节点的网络优化)。
-
动态ACO
- 实时响应环境变化(如交通拥堵时的即时路径重规划)。
-
离散-连续混合问题
- 扩展算法处理混合变量类型(如同时优化设备布局和连续参数)。

















 1861
1861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









