







1、下列几种数据挖掘功能中被广泛的用于购物篮分析的是( 关联分析 )
2、设X={1,2,3}是频繁项集,则可由X产生( 6 )个关联规则
3、关联规则的支持度公式为( support(A=>B)=P(A∪B) )
4、规则∅→A和A→∅的置信度是( 100% )
5、购买HDTV和购买健身器的情况如下表所示,设最小支持度阈值为0.3,最小置信度阈值为0.6,则{买HDTV }→{买健身器}的支持度为( 0.33 )
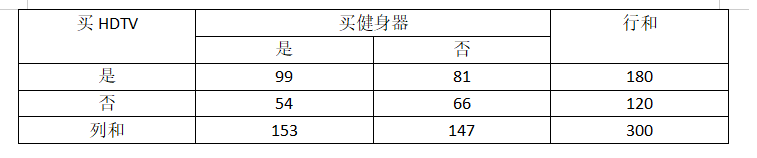
6、上一题所给的数据中,{买HDTV }→{买健身器}的置信度为( 0.55 )
7、考虑如下的频繁3-项集:{1, 2, 3},{1, 2, 4},{1, 2, 5},{1, 3, 4},{1, 3, 5},{2, 3, 4},{2, 3, 5},{3, 4, 5}。选出根据Apriori算法利用上述频繁3-项集生成的候选4-项集( {1,2,3,4};{1,2,3,5};{1,2,4,5};{2,3,4,5} )
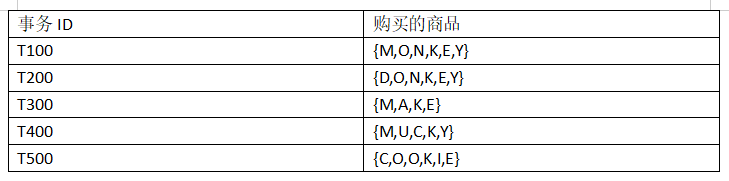
8、一个数据库有5 个事务,如下表所示。设min_sup=60%,min_conf = 80%。从下列选项中选出频繁2-项集( {M,K};{O,K};{K,E} )
9、Apriori算法包括连接和剪枝两个基本步骤。( 对 )
10、如果L2={{a,b},{a,c},{a,d},{b,c},{b,d}},则连接产生的C3={{a,b,c},{a,b,d},{a,c,d},{b,c,d}}。( 对 )
11、同时满足( 最小支持度阈值 )和( 最小置信度阈值 )的规则称之为强关联规则
12、在挖掘闭模式算法中,直接搜索闭频繁项集,并对结果进行剪枝是最常用的方法,其中剪枝的策略不包括项合并和子项集剪枝。( 错 )
13、频繁出现在数据集中的模式称为( 频繁模式 )
14、大型数据库中的关联规则挖掘包含找出所有频繁项集和由频繁项集产生强关联规则两个过程。( 对 )
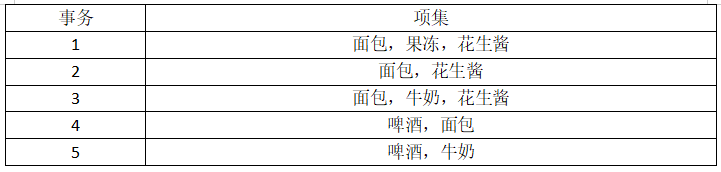
15、某个食品连锁店每周的事务记录如下表所示,每个事务表示在一项收款机业务中卖出的商品项集,假定min_sup=40%,min_conf=40%,使用Apriori算法生成的强关联规则有( {面包}->{花生酱} )和( {花生酱}->{面包} )两项
16、计算关联规则{牛奶}=>{咖啡}的支持度和置信度:( 0.40 )( 0.80 )(答案保留小数点后两位)

17、从上题的数据中计算牛奶与咖啡之间的提升度和杠杆度:( 1.3 )( 0.1 )(答案保留小数点后一位)
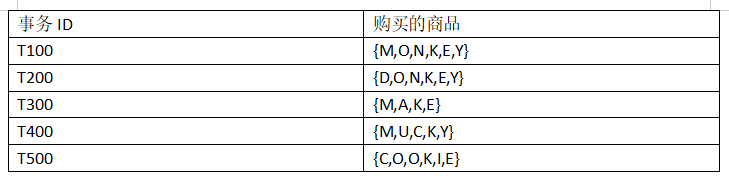
18、一个数据库有5个事务,如下表所示。设min_sup=60%,min_conf = 80%。用Apriori算法找出所有3频繁项集( {O,K,E} )
19、计算{面包(A)=>啤酒(E)}的支持度( 0.2 )(保留小数点后一位)
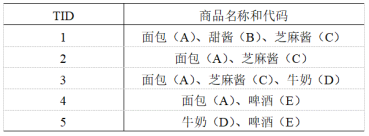
20、先验原理可以表述为:如果一个项集是频繁的,那包含它的所有项集也是频繁的。( 错 )
21、具有较高的支持度的项集具有较高的置信度。( 错 )
22、如果两个项集的提升度的值小于1,则说明两个项集正相关。( 错 )
23、极大频繁项集的直接超集都不是频繁的。( 对 )
24、Apriori算法是一种典型的关联规则挖掘算法。( 对 )
25、设最小支持度阈值为30%,最小置信度阈值为70%,如果一个项集的支持度为50%,则该项集是频繁项集。( 对 )
26、某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题( 关联规则发现 )
27、置信度(confidence)是衡量哪种兴趣度度量的指标( 确定性 )
28、下列指标中,能够度量一个规则的强度,同时衡量两个集合之间的独立性的是( 确信度 )
29、令C1, C2和C3分别是规则{p}→{q},{p}→{q,r},{p,r}→{q}的置信度。如果假定C1, C2和C3有不同的值,置信度最低的规则是( C2 )
30、如果X∈Y,且Y中至少有一项不在X中,那么Y是X的( 真超项集 )
31、下列关于Apriori算法的分析中,错误的是( Apriori算法会扫描数据库2次 )
32、下列不属于Apriori算法的缺点的是( Apriori算法分为两个阶段挖掘频繁项集 )
33、下表是一个购物篮,假定支持度阈值为40%,其中哪几个是频繁闭项集( abc;de )

34、以下关于非频繁模式说法,正确的是( 其支持度小于阈值;对异常数据项敏感 )
35、下列关于FP-growth算法优缺点的表述中,正确的有( 相比于Apriori算法,FP-growth算法运行速度要快一个数量级;FP-growth算法无须多次扫描数据库,节省了运行时间;FP-growth算法处理产生的条件树时会占用很多资源 )
36、关联规则的置信度公式为confidence(A=>B)=( P(B|A) )
37、如果一个项集的直接超集都不具有和它相同的支持度计数,则称其为( 闭项集 )
38、不包含任何考察项集的事务称为( 零事务 )
39、关联规则挖掘任务主要分为( 频繁项集的产生 )和( 关联规则的产生 )两个子任务
40、FP-growth算法的基本思想是用FP-growth( 递归增长 )形成频繁集
41、事物t={牛奶,面包,啤酒}是( 3 )项集
42、FP-growth算法在一次运行中扫描( 2 )次数据库
43、计算{面包(A)=>啤酒(E)}的支持度( 0.2 ) (保留小数点后一位)
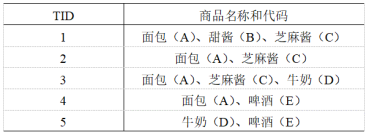
44、从上题的数据中计算规则{面包(A)}=>{甜酱(B)}的置信度( 0.25 ) (答案保留小数点后两位)
45、关联规则挖掘过程是发现满足最小支持度的所有项集代表的规则。( 错 )
46、利用先验原理可以帮助减少频繁项集产生时需要探查的候选项个数。( 对 )
47、先验原理可以表述为:如果一个项集是频繁的,那包含它的所有非空子集也是频繁的。( 对 )
48、两个项集的全置信度越大,说明两个项集的关系越紧密,反之则关系越疏远。( 对 )
49、可信度是对关联规则的准确度的衡量。( 对 )
50、关联规则是形如X=>Y的蕴含式,X和Y满足:X和Y是I的真子集,并且X和Y的交集为空集。( 对 )

















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









