






我们首先介绍下mac电脑的用处。2015年的时候让在国外留学的弟弟背回来一台英特尔处理器的,MacBookPro 。那时候我的圈子里流传着一句话“买苹果电脑如果不是为了装*那就毫无意义”,虽然直到现在那台电脑还在服役状态。但是真正作为生产力工具使用的时间加起来也就不到两年。
事情出现转机是在2020 年苹果曾向部分开发者提供搭载 A12Z Bionic 芯片的定制款 DTK Mac mini,这是苹果在个人电脑尝试使用自研芯片的开端,推出了一个能促成这篇文章的硬件,统一内存架构的Soc。
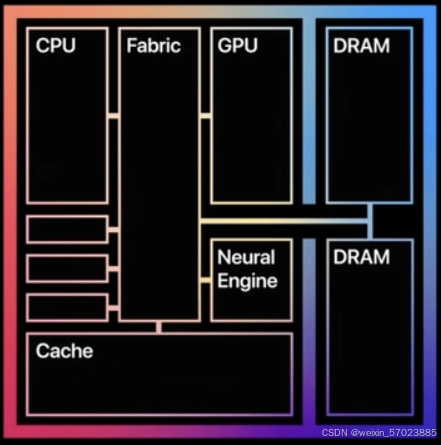
从这开始mac电脑上运行内存和显存使用了同一个存储芯片,也就是说内存就是显存。但是发展到这还不足以激起太多回响。
2022年3月 M1 Ultra 发布。顶配的macstudio 配置了128G的内存,在这考重点前面提到什么了?这128G的内存就是128G的显存。随后2022年5月 pytorch 宣布适配苹果的mps架构。再加上M系列的Ultra 内存带宽能达到800G/s 这使得一台MacStudio 上真的能运行起来一个超大的模型。
截止到我写稿,目前M系列最强芯片M3Ultra 配置了 512G的内存。

就不拿它计算等于多少张4090了。短视频还有ai社区的人已经有人测试过671B的Deepseek了,虽然是量化过的。但是也是绝无仅有的能再一台个人电脑上运行起来一个超大模型,同样配置的能跑起来这么大模型的GPU算力 起码是百万起步了,但是mac电脑的512G内存 满配 也才十万。性价比超高。说实话说苹果有性价比我都恍惚了一下。这俩词以前就像是反义词一样。

能在自己的电脑上运行起来一个大模型去做开发者大大降低了开发成本。开发者不需要再去花高价格购买一台服务器才能做ai开发,这也推动了ai整个行业的发展。
下面说一下文章标题中第二个主角MLX框架

虽然pytorch 适配了苹果的架构 直接修改驱动为mps就能直接适配M系列的芯片,但是对于硬件都自己造的苹果感觉还是差点意思。
于是2023年12月 苹果推出了MLX框架。
MLX 是专门为苹果系列芯片设计的科学计算框架。框架本身的设计在概念上也很简单。研究人员能够轻松地扩展和改进 MLX,以快速探索、测试新的想法。MLX 的设计灵感来自 NumPy、PyTorch、Jax 和 ArrayFire 等框架。这使得开发者在使用习惯上几不用做出改变。mlx框架宗旨是原生适配,更多的去压榨一下 M系列芯片的 性能。
下面是一些简单的示例
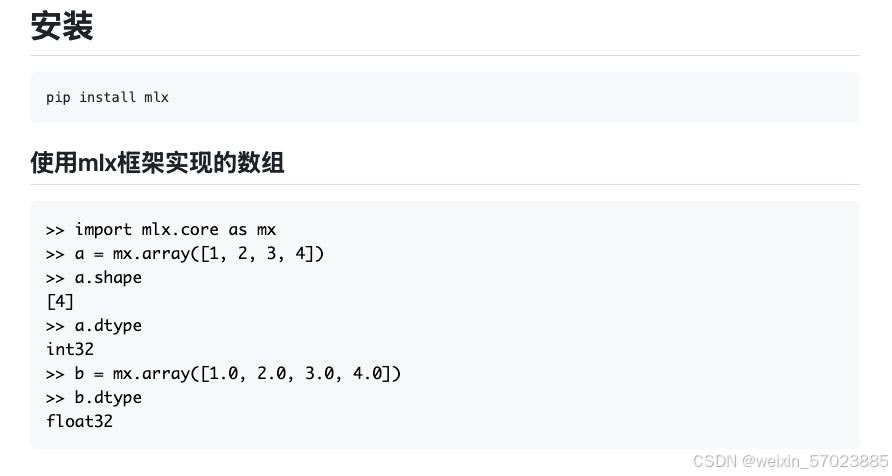
这上面是简单的介绍详细的介绍还是需要去官网去查看.
MLX — MLX 0.24.1 documentation
结合上面说的mlx框架宗旨是原生适配,更多的去压榨一下 M系列芯片的性能。我更多的是使用MLX适配芯片运行起来一个我们需要的模型。提供智能应用开发的必要条件
方法一:LMStudio上直接选择MLX适配的模型运行起来。
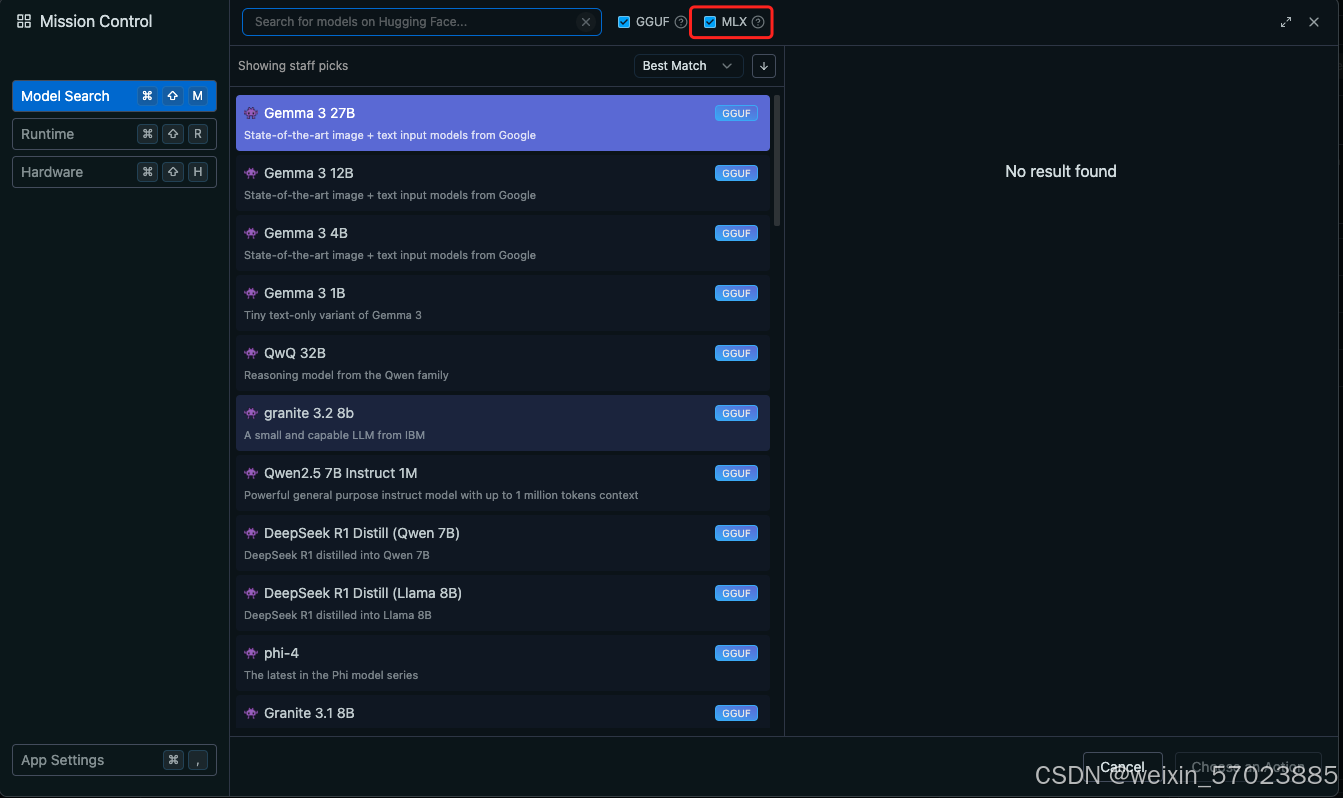
方法二:使用mlx框架直接运行一个模型,模型下载可以从modelscope还有huggingface上自行下载。
下面是 jupyter notebook上测试代码
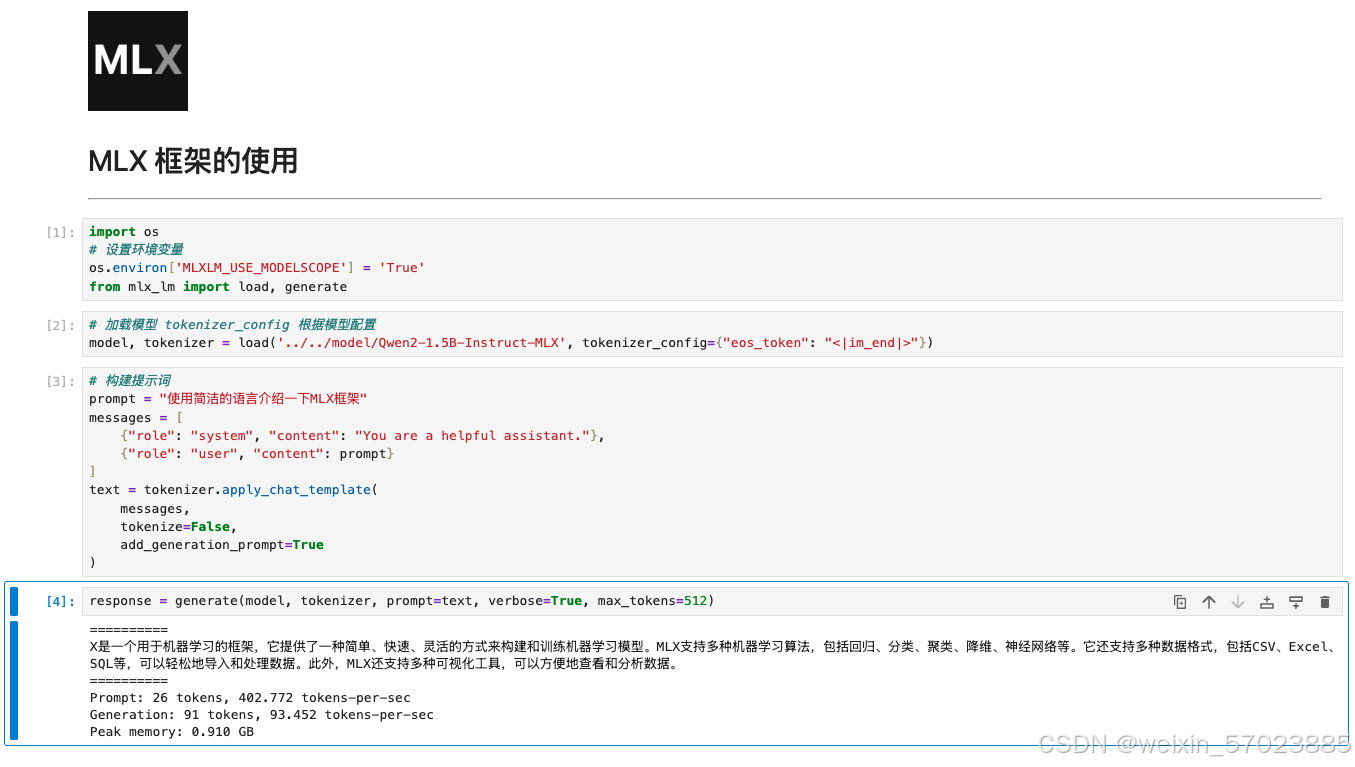
已经运行到这一步的话 后续如果需要运行一个兼容openai格式的api接口也是非常简单。小伙伴们根据需求自行开发。
在M2Ultra 发布的时候 对M2Ultra 的介绍有提到完全可以在这台机器上去训练一个大模型。训练我个人觉得不太现实,而且现在能用的大模型很多根本没有自己训练的必要。
但是精调一下还是可以的。
以Qwen2.5-1.5B-Instruct 为例简单介绍一下。
首先我们需要准备精调的文档的三个文件 里面是json格式的。但是文件名后缀为jsonl
test.jsonl
train.jsonl
valid.jsonl
这三个分别是测试集,训练集,还有验证集。
json格式内容:
{
"prompt": "<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<|im_start|>user\n{问题}<|im_end|>",
"completion": "<|im_start|>assistant\n{答案}<|im_end|>"
}微调命令:
mlx_lm.lora --model './model/Qwen2.5-1.5B-Instruct' --train --iters {训练轮数: 600} --data {训练数据集所在文件夹:data}微调之后会生成一个 adapters 文件夹,使用的时候 加载上 就可以测试微调之后的成果
挂载训练之后的权重:
mlx_lm.generate --model './model/Qwen2.5-1.5B-Instruct' --adapter adapters/ --max-tokens 1024 --prompt '{问题}'如果对微调结果满意的话 可以把微调后的权重文件合并就可以使用微调后的模型了。
mlx_lm.fuse --model './model/Qwen2.5-1.5B-Instruct' --save-path Qwen2.5-1.5B-Instruct-ft --adapter-path adapters 以上就是本次分享的全部内容谢谢大家

















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









