







1.什么是Word Embedding
⾃然语⾔是⼀套⽤来表达含义的复杂系统。在这套系统中,词是表义的基本单元。顾名思义,词向量是⽤来表⽰词的向量,也可被认为是词的特征向量或表征。把词映射为实数域向量的技术也叫词嵌⼊(word embedding)。 近年来,词嵌⼊已逐渐成为⾃然语⾔处理的基础知识。
在NLP(自然语言处理)领域,文本表示是第一步,也是很重要的一步,通俗来说就是把人类的语言符号转化为机器能够进行计算的数字,因为普通的文本语言机器是看不懂的,必须通过转化来表征对应文本。早期是基于规则的方法进行转化,而现代的方法是基于统计机器学习的方法。
数据决定了机器学习的上限,而算法只是尽可能逼近这个上限,在本文中数据指的就是文本表示,所以,弄懂文本表示的发展历程,对于NLP学习者来说是必不可少的。接下来开始我们的发展历程。文本表示分为离散表示和分布式表示:
2.离散表示
2.1 One-hot表示
1、介绍: One-hot简称读热向量编码,也是特征工程中最常用的方法。其步骤如下:
1、构造文本分词后的字典,每个分词是一个比特值,比特值为0或者1。
2、每个分词的文本表示为该分词的比特位为1,其余位为0的矩阵表示。
2、例如: John likes to watch movies. Mary likes too
John also likes to watch football games.
以上两句可以构造一个词典,**{“John”: 1, “likes”: 2, “to”: 3, “watch”: 4, “movies”: 5, “also”: 6, “football”: 7, “games”: 8, “Mary”: 9, “too”: 10} **
每个词典索引对应着比特位。那么利用One-hot表示为: John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] ** ,likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] …等等,以此类推。将语段转为一个n行一列的向量**
3、缺点:
1、随着语料库的增加,数据特征的维度会越来越大,产生一个维度很高,又很稀疏的矩阵。
2、另外,这种表示方法的分词顺序和在句子中的顺序是无关的,不能保留词与词之间的关系信息。
4、原因:
1、独立编码: 因为One-Hot的目的是每个单词被独立编码为一个唯一的向量,编码结果之间没有任何联系。即使两个单词在语义上相关,它们的一热编码也完全不同,这样就会导致语段矩阵特别稀疏,但纬度又很高。
2、上下文忽略: 一热编码无法捕捉到单词之间的上下文关系。每个单词在句子中的语义可能会因为上下文的不同而变化,但一热编码无法反映这一点。

2.2 词袋模型(Bag of Word model)
1、介绍: 词袋模型(Bag-of-words model)是一种常见的文本表示方法,通过统计文本中每个单词出现的频率来表示文本,像是句子或是文件这样的文字可以用一个袋子装着这些词的方式表现,。它忽略了单词的顺序和语法,仅关注单词的出现情况,比如: I Love you,you dont love me,很显然 两个love是出现在不同地方的,但是Bag of Word model会根据单词的频率进行简单相加,因此没有考虑到单词的顺序问题和上下文的影响。
2、例子: 文档的向量表示可以直接将各词的词向量加和
John likes to watch movies. Mary likes too
John also likes to watch football games.
以上两句可以构造一个词典,{“John”: 1, “likes”: 2, “to”: 3, “watch”: 4, “movies”: 5, “also”: 6, “football”: 7, “games”: 8, “Mary”: 9, “too”: 10}
那么第一句的向量表示为:[1,2,1,1,1,0,0,0,1,1],其中的2表示likes在该句中出现了2次,依次类推。
3、词袋模型和热编码的区别:

2.3 TF-IDF
1、是什么: TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency)。
2、核心思想: 字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。
3、公式:
TF(词频): 衡量词t在文档 a 中出现的频率。词频高的词对文档的贡献更大。
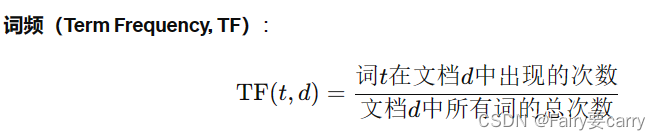
IDF(逆文档频率): 衡量词t在整个语料库 D 中的普遍性。词在多个文档中出现的频率越高其逆文档频率越低。这意味着常见词对区分文档的重要性较低。

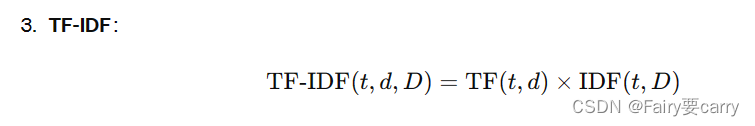
4、例子:


5、缺点: 尽管 TF-IDF 能有效衡量词在文档中的重要性,但它无法捕捉到词与词之间的顺序和关系。这是许多基于统计的方法的局限性,因此在实际应用中,**往往需要结合其他方法(如词向量、神经网络模型等)**来更全面地理解文本的语义和结构。
2.4、n-gram模型
1、是什么: n-gram模型为了保持词的顺序,做了一个滑窗的操作,这里的n表示的就是滑窗的大小,例如2-gram模型,也就是把2个词当做一组来处理,然后向后移动一个词的长度,再次组成另一组词,把这些生成一个字典,按照词袋模型的方式进行编码得到结果。改模型考虑了词的顺序。
2、比如: John likes to watch movies. Mary likes too
John also likes to watch football games.
以上两句可以构造一个词典, 【{"John likes”: 1, "likes to”: 2, "to watch”: 3, "watch movies”: 4, "Mary likes”: 5, "likes too”: 6, "John also”: 7, "also likes”: 8, “watch football”: 9, “football games”: 10}】
那么第一句的向量表示为:[1, 1, 1, 1, 1, 1, 0, 0, 0, 0],其中第一个1表示John likes在该句中出现了1次,依次类推。
3、缺点: 随着n的大小增加,词表会成指数型膨胀,会越来越大,并且向前探索词汇时难度很大**(解决:共现矩阵)**。
2.5 离散存在的问题:
由于存在以下的问题,对于一般的NLP问题,是可以使用离散表示文本信息来解决问题的,但对于要求精度较高的场景就不适合了。
1、无法衡量词向量之间的关系。
2、词表的维度随着语料库的增长而膨胀。
3、n-gram词序列随语料库增长呈指数型膨胀,更加快。
4、离散数据来表示文本会带来数据稀疏问题,导致丢失了信息,与我们生活中理解的信息是不一样的















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











