









1.n-gram
自己理解:
- n代表窗口长度,n-gram的思想就是先滑窗,然后统计频次,然后计算条件概率,你可以取前面n个的条件概率,不一定要取全部的,最后得到的是整个句子的一个概率,那这个概率可以代表句子的合理性。
详情见:
https://zhuanlan.zhihu.com/p/32829048


如何利用n-gram作为额外的特征呢?
例如:
我 爱 北京 天安门
这样词就有各种组合了:
它的一到三gram为:
[我,爱,北京,天安门,我爱,我北京,我天安门,…,我爱北京,我爱天安门,…]就是不同的组合,然后每一个词对应onehot特征里面的1维。
那么原来的我爱北京天安门的特征就是根据这段语句生成的一到三gram的组合。

https://zhuanlan.zhihu.com/p/29555001
2 NNLM(Neural Network Language Model)
NNLM模型的构造输入是前n个字的onehot特征,输出是这段文字的条件概率,也就是通过学习这个条件概率来学习embedding。

中间有激活函数,用的激活函数是双曲正切
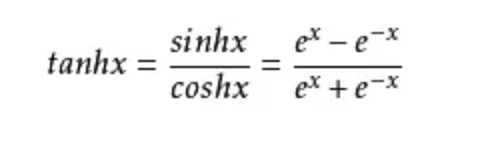

其实是一个开创性的创举,然后word2vec改了一下,让他更容易训练,训练更快了,去掉了激活函数,直接预测下一个词,感觉改得好简单啊。
3 word2vec
- 数据结构和算法——Huffman树和Huffman编码:https://blog.csdn.net/google19890102/article/details/54848262
3.1 分层softmax
https://www.cnblogs.com/guoyaohua/p/9240336.html

3.2 负采样
https://zhuanlan.zhihu.com/p/39684349
- 高频词抽样

- 负采样

4.Glove详解
看了之后一脸懵逼,实际情况是这样,因为word2vec是利用上下文特定长度窗口内的文本去训练一个词向量,这样每次看到的都是局部的信息,如果和全部词的信息利用起来呢?
g
l
o
v
e
首
先
构
造
一
个
共
线
矩
阵
,
这
个
矩
阵
通
过
一
翻
设
计
,
可
以
衡
量
两
个
词
之
间
共
同
出
现
的
概
率
关
系
,
然
后
类
似
于
w
o
r
d
2
v
e
c
,
去
学
习
这
个
共
线
矩
阵
,
这
样
得
到
的
中
间
结
果
作
为
词
向
量
,
注
意
这
里
有
两
个
词
向
量
,
都
可
以
用
,
只
是
随
机
化
参
数
不
一
样
,
最
后
可
以
取
二
者
的
平
均
,
最
后
就
是
加
了
一
个
权
重
因
子
,
来
更
好
的
对
频
次
较
高
和
较
低
的
词
做
一
些
修
正
,
具
体
详
情
如
下
:
glove首先构造一个共线矩阵,这个矩阵通过一翻设计,可以衡量两个词之间共同出现的概率关系,然后类似于word2vec,去学习这个共线矩阵,这样得到的中间结果作为词向量,注意这里有两个词向量,都可以用,只是随机化参数不一样,最后可以取二者的平均,最后就是加了一个权重因子,来更好的对频次较高和较低的词做一些修正,具体详情如下:
glove首先构造一个共线矩阵,这个矩阵通过一翻设计,可以衡量两个词之间共同出现的概率关系,然后类似于word2vec,去学习这个共线矩阵,这样得到的中间结果作为词向量,注意这里有两个词向量,都可以用,只是随机化参数不一样,最后可以取二者的平均,最后就是加了一个权重因子,来更好的对频次较高和较低的词做一些修正,具体详情如下:

通俗易懂理解——Glove算法原理:
https://zhuanlan.zhihu.com/p/42073620
GloVe详解
http://www.fanyeong.com/2018/02/19/glove-in-detail/
nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
https://zhuanlan.zhihu.com/p/56382372
其他参考链接:
https://www.cnblogs.com/guoyaohua/p/9240336.html
https://zhuanlan.zhihu.com/p/53425736
https://zhuanlan.zhihu.com/p/61635013
https://blog.csdn.net/bitcarmanlee/article/details/82291968















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









