






常用的定义:
读取数据加速:
input = sys.stdin.readline设置递归深度:
sys.setrecursionlimit(100000)记忆化搜索:
from functools import lru_cache
@lru_cache(maxsize=None)计数器:
Counter 类是一个非常有用的工具,用于对可迭代对象中的元素进行计数。
例如,假设您有一个列表,其中包含一些元素,您想知道每个元素在列表中出现了多少次,这时您就可以使用 Counter。
以下是一个简单的示例:
from collections import Counter # 创建一个列表
my_list = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple'] # 使用 Counter 对象统计列表中元素的出现次数
my_counter = Counter(my_list) # 输出每个元素的出现次数
print(my_counter)这将输出:
Counter({'apple': 3, 'banana': 2, 'orange': 1})自定义排序
functools.cmp_to_key(func)
旧式函数,在类似于吗sort,min等函数上使用
此函数主要用作将 Python 2 程序转换至新版的转换工具,以保持对比较函数的兼容。比较函数是任何接受两个参数,对它们进行比较,并在结果为小于时返回一个负数,相等时返回零,大于时返回一个正数的可调用对象。 键函数是接受一个参数并返回另一个用作排序键的值的可调用对象。示例:sorted(iterable, key=cmp_to_key(locale.strcoll))
蓝桥2122

import functools
n = int(input())
m = int(input())
def compare(a, b):
sum1 = sum(map(int, str(a))) # 计算a的各个数字之和
sum2 = sum(map(int, str(b))) # 计算b的各个数字之和
if sum1 > sum2:
return 1
elif sum1 == sum2:
if a < b:
return -1
else:
return 1
else:
return -1
s = list(range(1, n + 1))
s.sort(key=functools.cmp_to_key(compare))
print(s[m-1])基本数据类型:
集合的妙用:
注意,使用集合去重之后不一定能保证原来的顺序。
#!/usr/bin/python3
sites = {'Google', 'Taobao', 'Runoob', 'Facebook', 'Zhihu', 'Baidu'}
print(sites) # 输出集合,重复的元素被自动去掉
sites.add(6) # 添加元素6
sites.remobe(5) # 删除元素5
# 成员测试
if 'Runoob' in sites :
print('Runoob 在集合中')
else :
print('Runoob 不在集合中')
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(a - b) # a 和 b 的差集
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素字典
#!/usr/bin/python3
dict = {}
dict['one'] = "1 - 菜鸟教程"
dict[2] = "2 - 菜鸟工具"
tinydict = {'name': 'runoob','code':1, 'site': 'www.runoob.com'}
print (dict['one']) # 输出键为 'one' 的值
print (dict[2]) # 输出键为 2 的值
print (tinydict) # 输出完整的字典
print (tinydict.keys()) # 输出所有键
print (tinydict.values()) # 输出所有值
print (tinydict.items()) # 输出项
print (tinydict.get('name'))# 输出runoob
print (tinydict.copy()) # 复制字典
tinydict.pop('name') # runoob
tinydict.popitem('name', 'runoob')字符串
| find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
count() 方法用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
count()方法语法:
str.count(sub, start= 0,end=len(string))
- sub -- 搜索的子字符串
- start -- 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
- end -- 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
replace()方法语法:
str.replace(old, new[, max])
- old -- 将被替换的子字符串。
- new -- 新字符串,用于替换old子字符串。
- max -- 可选字符串, 替换不超过 max 次

test = "123"
test.ljust(10,'0') # 左对齐,空位补0
test.rjust(10,'0') # 右对齐,空位补0 
内置函数
list.sort( key=None, reverse=False)
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。
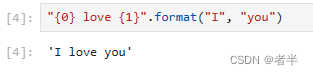
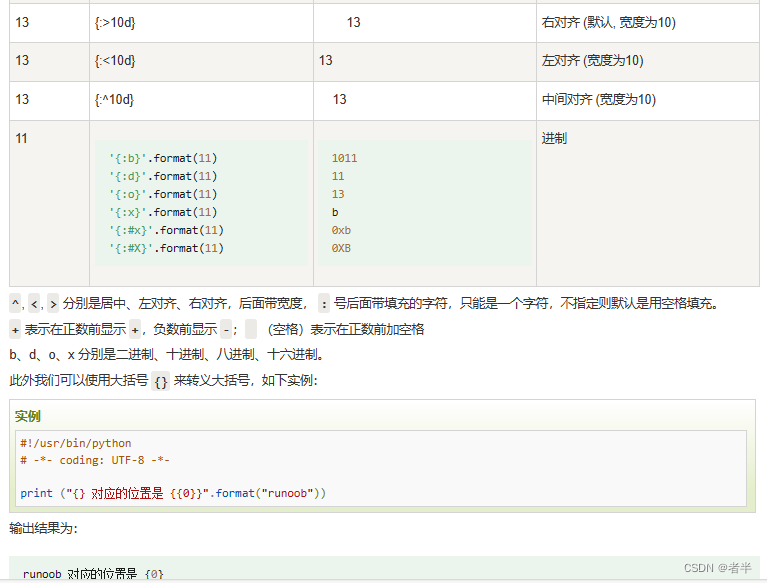
.format()格式化方法
位置参数:0,1,2

enumerate(iterable)
生成二元组的迭代对象

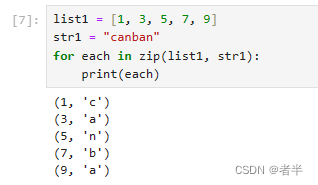
zip(iter1,iter2..)
方法用于返回各个可迭代参数共同组成的元组
小技巧冷知识:
int('2022',9) 9进制的2022转为10进制
math库
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| pow(x, y) | x**y 运算后的值。 |
| round(x [,n]) | 返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。 其实准确的说是保留值将保留到离上一位更近的一端。 |
math.log(x, base) :以base为底的对数
for else循环体

itertools
accumulate累乘
from itertools import accumulate 
time模块
import time 
t = time.localtime() # 本地时间
print(t.tm_year) # 查看年份格式化日期
# 格式化日期
t = time.strftime("%Y-%m-%d %H:%M:%S", t) # 时间转字符串
print(type(t))
print(t)输出如下:

import time
t_str = "2023--10--09 13::03::13"
t_tuple = time.strptime(t_str, "%Y--%m--%d %H::%M::%S") # 字符串转时间

datetime模块
date类
a = datetime.date(2023,10,1)
print(type(a))
print(a) 
# 获取年月日,星期
print(a.year) # 年
print(a.month) # 月
print(a.day) # 天数
print(a.weekday()) # 周几注意:weekday从0开始算,也就是星期一实际上是0

a = datetime.date(2023,10,1)
b = datetime.date(2023,10,7)
print(type(a - b))
print(a - b)
# 支持和另外一个date进行判断
print(a < b) 
time类
import datetime
a = datetime.time(10, 25, 30) # 时间不允许做加减法,但是支持判断
print(a.hour)
print(a.minute)
print(a.second)datetime类
获取方式和前面相同
但是有两个特别的
a = datetime.datetime(2023, 10, 1, 10, 25, 30)
print(a.date())
print(a.time())组合方法
a = datetime.date(2023,10,1)
b = datetime.time(10, 25, 30)
c = datetime.datetime.combine(a,b)
print(c)timedelta类
时间差:表示两个datetime对象之间的间隔
用days,seconds,microseconds(微秒)三个变量存储时间间隔
定义时可以传入:weeks,days,hours,minutes,seconds,milliseconds,microseconds然后自动转换成上述变量
datetime与timedelta进行加减可以得到新的datetime
而datetime之间进行减法,得到timedelta
a = datetime.datetime(2023,10,1,10,25,30)
delta = datetime.timedelta(days=100)
b = a + delta # 计算100天之后的日期
print(b)
格式化
import datetime
d = datetime.date(2023,10,1)
print(d.strftime("%Y--%m--%d"))
t = datetime.time(17,25,35)
print(t.strftime("%H::%M::%S"))基于这个日期,转为字符串。

应用:蓝桥611

import os
import sys
# 请在此输入您的代码
import datetime
start_time = datetime.date(1901,1,1)
end_time = datetime.date(2000,12,31)
delta = datetime.timedelta(days=1)
count = 0
while start_time < end_time:
if start_time.weekday() == 0:
count += 1
start_time += delta
print(count)一、chr
chr( {需要转换的Unicode编码} ),返回值是对应的字符
例1:输入数字 65-91,返回值是大写字母
chr(65) # Achr(90) # Z例2:输入数字 97-122,返回值是小写字母
chr(97) # achr(122) # z二、ord
ord( {需要转换的字符} ),返回值是对应的Unicode编码
例1:
ord('b') # 98













 6251
6251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









