






模糊的概念:
模糊是指容观事物差异的中间过渡中的"本分明性"或"永此办下彼性"。如高个子与矮个子、年轻人与老年人、热水与凉水、环境污染严重与不严重等。在决策中,也有这种模糊的现象,如选举一个好干部,但怎样才算一个好干部?好干部与不好干部之间没有绝对分明和固定不变的界限。这些现象很难用经典的数学来描述。


模糊集合不是非0即1,通俗来讲越靠近1就越多人认为是1(靠近1的概念,比如高,年轻)
简单来说,我理解的隶属度,就是元素属于某个模糊集合的程度,而隶属函数就是用来确定隶属度的函数。
模糊集合和隶属函数
举一个简单的例子,我们要街量"年轻"的概念A="年轻",X=(0,150)表示年龄的集合在这里我们不好直接在0-150之间画个线把年轻和不年轻区分开,我们应该给一个隶属函数来进行描述
隶属函数是不唯一的。不同的人,不同大小的样本得出来的都很有可能不同。
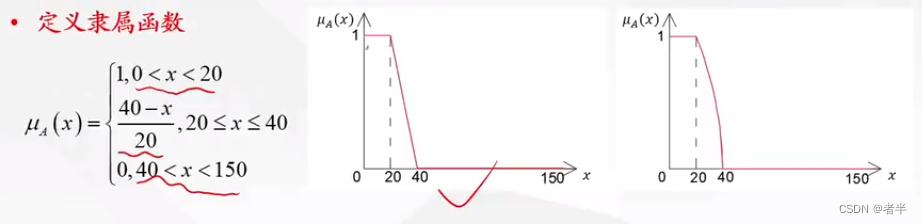



模糊集合主要有三类,分别为偏小型,中间型和偏大型。其实书也就类似于TOPSIS方法中的极大
型、极小型、中间型、区间型指标。
举个例子,"年轻"就是一个偏小型的模糊集合,因为岁数越小,隶属度越大,就越"年轻";"年老"则是一个偏大型的模糊集合,岁数越大,隶属度越大,越"年老";而"中年"则是一个中间型集合,岁数只有处在某个中间的范围,隶属度才越大。总结来说,就是考虑"元素"与"隶属度"的关系,再类比一下,就是考虑隶属函数的单调性。下图可以代表"年轻"、"中年"、"年老"这三个模糊集合的隶属函数图像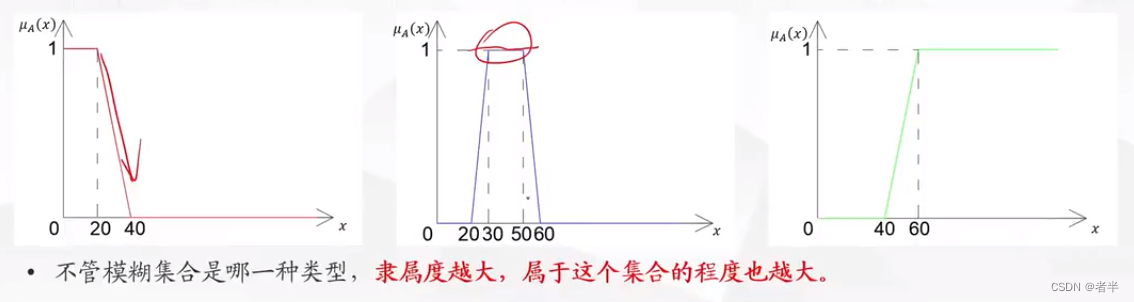
隶属函数的确定方法
(1)模糊统计法
模糊统计法的原理是,找多个人对同一个模糊概念进行描述,用康属频率去定义隶属度。例如我们想知道30岁相对于"年轻"的隶属度,那就找来n个人问一问,如果其中有m个人认为30岁属于"年轻"的范畴,那m/n就可以用来作为30岁相对于"年轻"的隶属度。n越大时,越符合实际情况,也就越准确。
这个方法比较符合实际情况,但是往往通过发放问卷或者其他手段进行调查。
2)借助已有的客观尺度
对于某些模糊集合,我们可以用已经有的指标去作为元素的隶属度。例如"小康家庭"这个模糊集合,就可以用"恩格尔系数(食品支出总额/家庭总支出)"衡量相应的隶属度。显而易见,家庭越接近小康水平,其恩格尔系数应该越低,那"1-恩格尔系数"就越大,我们便可以把"1-恩格尔系数"看作家庭相对于"小康家/庭"的隶属度。对于"质量稳定"这一模糊集合,我们可以使用正品率衡量隶属度
注意:隶属度是在[0,1]之间的。如果找的指标不在,可以进行归一化处理。
(3)指派法:自己选函数(根据单调性)

评价问题概述
模糊评价问题是要把论域中的对象对应评语集中一个指定的评语或者将方案作为评语集并选
择一个最优的方案。在模糊综合评价中,引入三个集合:
1.因素集(评价指标集)
2.评语集(评价的结果)
3.权重集(指标的权重)
例:评价一名学生的表现
U={专业排名、课外实践、志愿服务、竟赛成绩}
V={优、良、差}
A = {0.4、0.2、0.1、0.3}
- 模糊综合评价模型就是给定对象,用因素集的指标进行评价,从评语集中找到一个最适合它的评语。如果评语集中是方案的话,就是选出一个最恰当的方案。那这种"合适"用什么来衡量呢?显而易见嘛,就是隶属度,隶属于某个模糊集合的程度度。
具体问题:




根据例子总结步骤:
- 确定因素集
- 确定评语集
- 确定各因素的权重
- 确定模糊综合评价矩阵,也就是各个因素属于各个评语的隶属度
- 进行矩阵运算求出得分
由于多层次展现起来过于复杂,就不进行赘述,主要就是把多个指标堪称一个指标进行不断迭代。
具体代码如下:
import numpy as np
# 1、一级模糊综合评判
# 影响运行费用的各因素的单因素评价矩阵为:
R23 = np.array([
[0.18, 0.14, 0.18, 0.14, 0.13, 0.23],
[0.15, 0.20, 0.15, 0.25, 0.10, 0.15],
[0.25, 0.12, 0.13, 0.12, 0.18, 0.20],
[0.16, 0.15, 0.21, 0.11, 0.20, 0.17],
[0.23, 0.18, 0.17, 0.16, 0.15, 0.11],
[0.19, 0.13, 0.12, 0.12, 0.11, 0.33],
[0.17, 0.16, 0.15, 0.08, 0.25, 0.19]])
# 权重分配为
A23 = np.array([0.20, 0.15, 0.10, 0.10, 0.20, 0.15, 0.10])
# 评价结果
# np.dot是Numpy库中的一个函数,用于计算两个数组的点积。对于一维数组,它计算的是这两个数组的内积。
# 对于二维数组(矩阵),它计算的是矩阵乘法。
B23 = np.dot(A23, R23)
# 2、二级模糊综合评判
# 产品情况的二级评判如下:
R1 = np.array([
[0.12, 0.18, 0.17, 0.23, 0.13, 0.17],
[0.15, 0.13, 0.18, 0.25, 0.12, 0.17],
[0.14, 0.13, 0.16, 0.18, 0.20, 0.19],
[0.12, 0.14, 0.15, 0.17, 0.19, 0.23],
[0.16, 0.12, 0.13, 0.25, 0.18, 0.16]])
A1 = np.array([0.15, 0.40, 0.25, 0.10, 0.10])
B1 = np.dot(A1, R1)
# 销售能力二级评判如下:
R2 = np.array([
[0.13, 0.15, 0.14, 0.18, 0.16, 0.25],
[0.12, 0.16, 0.13, 0.17, 0.19, 0.23],
B23,
[0.14, 0.13, 0.15, 0.16, 0.18, 0.24],
[0.16, 0.15, 0.15, 0.17, 0.18, 0.19]])
A2 = np.array([0.2, 0.15, 0.25, 0.25, 0.15])
B2 = np.dot(A2, R2)
# 市场需求的二级评判
R3 = np.array([
[0.15, 0.14, 0.13, 0.18, 0.14, 0.26],
[0.16, 0.15, 0.18, 0.14, 0.16, 0.21]])
A3 = np.array([0.55, 0.45])
B3 = np.dot(A3, R3)
# 3、三级模糊综合评判
R = np.array([B1, B2, B3])
A = np.array([0.4, 0.3, 0.3])
B = np.dot(A, R)
print(B)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









