







 本文针对基于鲲鹏920处理器的众核NUMA架构,进行了Stencil计算的性能测试与分析。研究发现,鲲鹏920处理器在访存带宽和通信时延上表现出优越性能,使得模板计算应用如CCFD V3.0在鲲鹏平台上的运行速度约为Intel Xeon E5-2680v2的2~3倍。通过对硬件架构和软件性能的综合分析,强调了NUMA架构对模板计算类应用的优势。
本文针对基于鲲鹏920处理器的众核NUMA架构,进行了Stencil计算的性能测试与分析。研究发现,鲲鹏920处理器在访存带宽和通信时延上表现出优越性能,使得模板计算应用如CCFD V3.0在鲲鹏平台上的运行速度约为Intel Xeon E5-2680v2的2~3倍。通过对硬件架构和软件性能的综合分析,强调了NUMA架构对模板计算类应用的优势。
目录
摘要
【应用背景】 模板计算是CFD(计算流体动力学,Computational Fluid Dynamics)等科学计算的典型算法,其访存性能受到关注。NUMA架构因扩展性好,在以鲲鹏920处理器为代表的ARM架构上普遍被应用。【方法】 使用性能分析工具和benchmark程序,对鲲鹏平台的访存和通信子系统进行性能测试。针对典型stencil应用软件CCFD V3.0开展热点分析和性能测试,并建立Roofline模型。【结果】 鲲鹏920处理器依托其众核NUMA架构,单节点浮点性能、内存带宽峰值,以及通信时延均优于Intel Xeon E5-2680v2与一款国产处理器。单节点时,CCFD V3.0在鲲鹏平台的运行速度约是Intel平台的2~3倍,是国产处理器的1.5~2倍。【结论】 基于ARM架构的鲲鹏平台应用移植简单,其NUMA架构对模板计算一类访存密集性应用具有优势。
关键词: Stencil; 鲲鹏920; 性能评估; CFD
引言
模板计算(Stencil)被广泛应用于一类基于网格的科学计算中,例如计算流体力学、有限元分析、相场模拟等。模板计算中,每一个网格点的数据更新都会依赖其邻接网格,多维网格计算时将存在严重的访存不连续问题,导致较低的计算访存比,从而影响算法执行效率。因此,对模板计算的访存性能优化受到了科研人员的重视[1⇓-3]。
高性能计算技术正处于由容量(capacity)计算向能力(capability)计算发展的阶段,有两方面特征:一是大规模并行计算,并行规模向数万核乃至全机不断扩展;二是异构计算,基于“CPU+加速器”的模式被当前主流超算平台所采用。一个新的趋势是,基于精简指令集的ARM架构以其显著的低成本、高能效等优势受到了业内关注,例如富士通公司的A64FX[4]、“天河三号”采用的飞腾处理器[5],华为公司也于2019年1月发布了基于ARMv8-A架构的“鲲鹏920”处理器。
传统的SMP(对称多处理,Symmetrical Multi-Processing)架构由于总线的争用机制限制了计算核心数量和访存性能,NUMA(Non-Unified Memory Access,非统一内存访问)架构在一定程度上解决了SMP架构的扩展性问题,每一个NUMA节点都有独立的内存控制器和缓存系统,多核计算时能较大提升访存效率、发挥机器性能,在ARM架构中被普遍采用。
本文基于鲲鹏平台,针对benchmark程序以及典型模板应用软件开展了性能测试,并结合硬件架构和算法特点开展了性能分析。
1 鲲鹏920处理器
鲲鹏920处理器是基于ARMv8-A架构的服务器级芯片,采用了7nm的制造工艺和华为自研的Taishan v110微架构。鲲鹏920处理器有着较高的片上集成度,单CPU可支持32核、48核、64核,并集成了IO芯片,因此也被称为鲲鹏920处理器片上系统。内存控制器使用的是8通道DDR4(第4代双数据率,Double Data Rate 4)的SDRAM(同步动态随机存取存储器,Synchronous Dynamic Random-Access Memory)控制器,内存模式采用NUMA架构,具有高带宽特性[6]。
1.1 组织结构
以鲲鹏920-6426芯片为例,包括了两个超级内核集群(Super Core Cluster,SCCL),一个超级I/O集群(Super I/O Cluster,SICL)。SCCL由8个内核集群(Core Cluster,CCL)组成,CCL又包括4个完整实现了ARMv8-A架构的TaiShanV110处理器内核,组织架构如图1所示。
图1
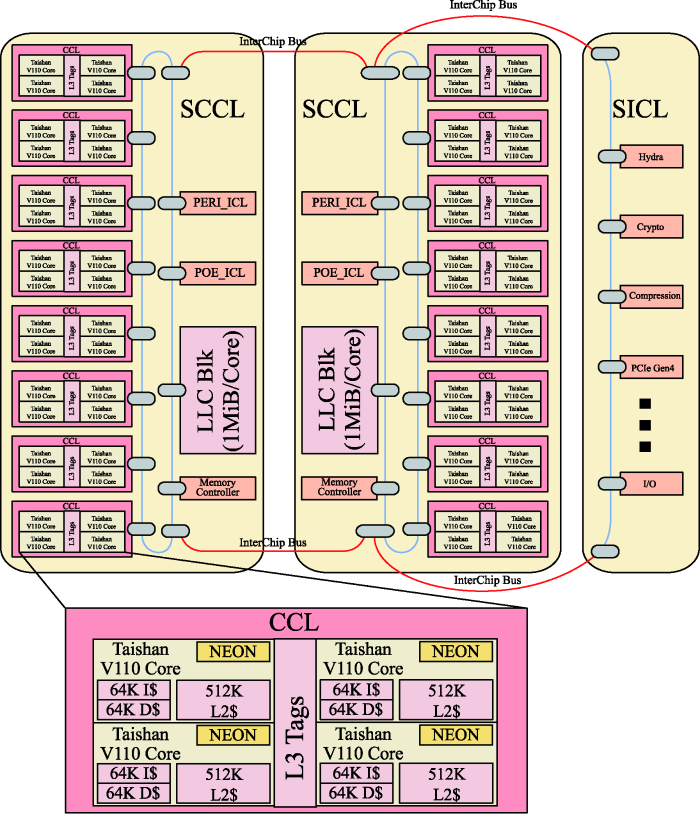
图1 鲲鹏920片上系统结构示意图[6]
Fig.1 Kunpeng 920 SoC structure diagram
1.2 内存储系统
鲲鹏920处理器的内核拥有私有的L1 Cache与L2 Cache。L1 Cache分为指令Cache(L1 I Cache)与数据Cache(L1 D Cache)两部分,均为64KB;L2 Cache为512KB。L3 Cache被处理器所有核心共享,大小为64MB,采用组相连结构,Cache line为128B。
1.3 NUMA架构
SMP是最为常见的多CPU系统,各处理器共享资源,处理器之间没有主从关系,对总线和内存的使用由操作系统统一调度,由于多CPU对内存的访问是同等的,所以也被称为UMA(Uniform Memory Access,统一内存访问)系统。SMP的缺点在于其扩展性受制于总线、内存、IO等资源,对于访存密集型算法,CPU利用率较低。
为了克服SMP因资源高度共享导致扩展性差的问题,NUMA架构采用了层次化缓存系统、分层共享和持有资源的设计思想。拥有独立内存资源和I/O资源的一组CPU或者计算核心被称为NUMA节点(Node),节点内一般由片上网络(on-chip network)互连,节点间由不同种类的通道进行互连。由于互连速度存在差异,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











