






 本文详细介绍了CiteSpace的功能选择区,包括TextProcessing的TermSource参数,用于文本预处理和分析;Link分析的LinkStrength和Scope参数,用于文献间关系的计算和筛选;以及作者影响力的评估指标g-index和h-index。此外,还讨论了Pruning机制和Burstiness算法在数据处理中的作用,以揭示研究网络的核心结构和热点。
本文详细介绍了CiteSpace的功能选择区,包括TextProcessing的TermSource参数,用于文本预处理和分析;Link分析的LinkStrength和Scope参数,用于文献间关系的计算和筛选;以及作者影响力的评估指标g-index和h-index。此外,还讨论了Pruning机制和Burstiness算法在数据处理中的作用,以揭示研究网络的核心结构和热点。
一、功能选择区
1、Time Slicing
2、Text processing
指对文献摘要、标题等文本信息进行预处理和分析,以便于后续的数据可视化和分析。其中,
Term Source(术语来源)是Text Processing中的一个参数,用于指定分析文本中的术语来源。具体而言,Term Source可以指定为以下几种类型:
1、Title:表示从文献标题中提取术语作为分析的对象。
2、Abstract:表示从文献摘要中提取术语作为分析的对象。
3、Keywords:表示从文献关键词中提取术语作为分析的对象。
4、Author Keywords:表示从文献作者提供的关键词中提取术语作为分析的对象。
通过设置Term Source参数,可以在文本处理过程中选择合适的术语来源,从而更好地反映研究问题的特点。例如,如果研究问题比较关注文献标题中的术语,可以将Term Source设置为Title;如果研究问题比较关注文献作者提供的关键词,可以将Term Source设置为Author Keywords。
需要注意的是,不同的Term Source会对分析结果产生不同的影响,因此在使用Text Processing参数时需要根据具体的研究问题和数据集的特点来选择最适合的参数。
2、Node Types
3、Link
在CiteSpace中,Link是一种分析文献之间相互引用关系的方式。Link分析可以通过多个参数来定义,这些参数可以在Link Control面板中进行设置。以下是Link Control面板中常用的参数及其含义:
Link Strength(连接强度)
指定连接强度的最小值和最大值。只有连接强度在指定范围内的连接才会被保留。
在CiteSpace中,Link Strength(连接强度)是指连接两个文献之间的强度,表示它们之间的关系有多紧密。Link Strength参数可以用不同的算法来计算,常见的算法包括:
1、Cosline(余弦相似度):计算两个文献之间的相似度,具体而言,是将两个文献的关键词向量进行余弦计算,得出的结果越接近1,说明它们之间的相似度越高。
2、PMI(互信息):表示两个文献之间出现关键词的频率与它们各自单独出现的概率的乘积之比。如果两个文献之间出现的关键词频率比单独出现的概率高,则它们之间的PMI值也会比较高。
3、Dice(Dice相似系数):计算两个文献之间的相似度,具体而言,是将两个文献的关键词向量进行计算,得出的结果越接近1,说明它们之间的相似度越高。
4、Jaccard(Jaccard相似系数):计算两个文献之间的相似度,具体而言,是将两个文献的关键词向量进行计算,得出的结果越接近1,说明它们之间的相似度越高。
需要注意的是,不同的Link Strength参数计算方法会对文献之间的连接强度产生不同的影响。在使用Link Strength参数时,需要根据具体研究问题和数据集的特点来选择最适合的计算方法。
Scope
决定了计算连接强度时考虑的文献范围。具体而言,Scope参数包括:
1、Within Slices(在时间切片内):表示只考虑在同一个时间切片内的文献之间的连接强度,即同一年或同一时期内的文献之间的连接强度。
2、Across Slices(跨时间切片):表示考虑在不同时间切片内的文献之间的连接强度,即不同年份或不同时期的文献之间的连接强度。
其中,时间切片(Time Slices)是指将研究时间范围划分成若干个相同长度的时间段,每个时间段被称为一个时间切片。通过选择Scope参数,可以在计算连接强度时考虑不同的文献范围,从而更好地反映研究问题的特点。
需要注意的是,选择不同的Scope参数会对连接强度的计算结果产生不同的影响,因此在使用Link参数时需要根据具体的研究问题和数据集的特点来选择最适合的参数。
4、Selection Criteria
4.1 g-index
用于衡量作者的论文数量和引用次数之间的平衡程度。
定义
g-index是一种基于引用次数的指标,它通过将作者的所有论文按照引用次数从高到低排序,找到最大的g值,使得前g篇论文的总引用次数不少于g^2。例如,如果一个作者的前3篇论文的总引用次数不少于9次,但前4篇论文的总引用次数不到16次,那么g-index为3。
使用
g-index是一种用于衡量作者产出和影响力的指标。与h-index类似,它能够综合考虑作者的论文数量和引用次数,但更加注重引用次数的平衡性。通常情况下,g-index越高,说明作者在领域内的影响力越大。
判断
在CiteSpace中,可以使用g-index来对作者的影响力进行比较。例如,将多位作者的g-index进行比较,可以得出谁在领域内具有更大的影响力。需要注意的是,不同学科领域的g-index标准可能会有所不同,因此不应该将不同领域的作者的g-index进行直接比较。
设置
在CiteSpace中,可以通过在“Parameters”中的“Analysis Type”下选择“g-index”来计算g-index。在“g-index Options”中,可以设置最小g值、最大g值和步长等参数。这些参数的选择取决于具体研究的目的和数据集的大小。例如,如果数据集很大,可以选择较大的步长和最大g值,以节省计算时间。

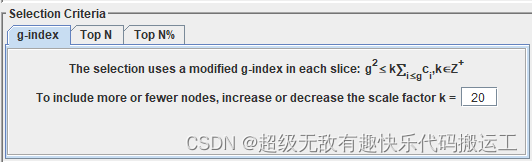
"k越大,图谱中出现的节点越多;k越小,图谱中出现的节点越少"
4.2 Top N
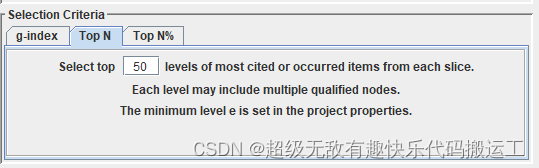
Top N是选择标准之一,用于筛选出具有最高影响力的N篇文章。具体而言,Top N将会筛选出引用次数排名前N的文章,这些文章具有较高的学术影响力和重要性
需要注意的是,Top N的设置应该根据具体情况进行调整。如果N值设置得太小,可能会导致一些影响力较小但具有一定学术价值的文章被排除在外。如果N值设置得太大,可能会导致结果过于冗长,难以进行分析和理解。因此,在设置Top N时,应该结合具体数据集的特点和研究目的进行综合考虑,以获取最优的分析结果。
"Top N代表的是选取被引次数最高的N个引文,因为我们要去找重要的文献,重要的文献怎么去找呢?我们就可以通过这样的一个文献可计量的方式去进行分析。Top N后面加上百分比(Top N%),就是说它引文所选取的百分比。"
3.2 h-index
一种基于作者的论文被引用次数来评估其学术影响力的指标
定义
h-index是指一个作者的h篇论文被引用次数至少为h次,而其他文章的引用次数小于等于h次。例如,如果一个作者的h-index为10,这意味着他/她的前10篇论文至少被引用了10次,而其他论文的引用次数不超过10次。
使用
1在CiteSpace中,可以通过设置h-index分析参数来计算和可视化作者的h-index值。在结果中,每个作者的h-index值将显示在其名称下方。
判断
h-index可以用于评估一个作者的学术影响力和研究贡献。一般来说,具有较高h-index值的作者通常被认为具有更高的学术声誉和研究水平。
设置
在CiteSpace中,可以通过设置h-index分析参数来计算和显示作者的h-index值。在设置h-index分析参数时,需要考虑以下几个因素:
最小h值
通常情况下,最小h值应该设置为2或3。这意味着一个作者的前2或3篇论文的引用次数至少为2或3次。
最大h值
最大h值的选择取决于数据集的大小和特点。如果数据集很大,可以适当增加最大h值。如果数据集比较小,可以适当减小最大h值。
步长
步长指的是每次增加h值的数量。一般来说,步长应该设置为1,以便获取尽可能多的h值。
需要注意的是,不同学术领域和文献类型具有不同的引用情况和特点,因此在设置h-index分析参数时应该根据具体情况进行调整,以确保结果的准确性和可靠性。
6、Pruning
在CiteSpace中,Pruning(修剪)是一种数据处理方法,用于过滤掉一些不重要的节点和边,从而可以更好地显示研究网络的核心结构和主要特征。Pruning可以通过设置不同的参数来实现,常用的参数包括:
-
Pathfinder:表示使用路径查找算法对研究网络进行修剪。路径查找算法会从起点出发,逐步搜索到所有其他节点,然后根据节点的重要性对网络进行修剪。Pathfinder算法可以过滤掉一些不重要的节点和边,使研究网络的结构更加简单明了。
-
Minimum Spanning Tree:表示使用最小生成树算法对研究网络进行修剪。最小生成树算法会从起点出发,逐步连接到所有其他节点,然后根据边的权重对网络进行修剪。Minimum Spanning Tree算法可以过滤掉一些不重要的边,使研究网络的结构更加简单明了。
-
Pruning Sliced Networks:表示对分片网络进行修剪,只保留与主干网络相关的节点和边,将其他节点和边过滤掉。Pruning Sliced Networks算法可以过滤掉一些不重要的节点和边,使研究网络的结构更加清晰明了。
-
Pruning the Merged Network:表示对合并网络进行修剪,只保留与研究问题相关的节点和边,将其他节点和边过滤掉。Pruning the Merged Network算法可以过滤掉一些不重要的节点和边,使研究网络的结构更加简单明了。
通过设置Pruning参数,可以过滤掉研究网络中一些不重要的节点和边,从而可以更好地展示研究网络的核心结构和主要特征。需要注意的是,Pruning参数的设置需要根据具体的研究问题和数据集的特点来进行调整,一般建议根据实际情况灵活选择,以得到更加准确和有用的分析结果。
二、control panel
2.1 burstness
f(x)=ae^(-ax), a1/a0
其中a1/a0是控制函数形状的参数,a表示控制函数的尺度参数,e是自然对数的底数。这个参数的作用是调整Burst Detection算法中burst的判定标准,即判断一段时间是否为burst的阈值。增大a1/a0可以提高判定burst的严格程度,即更严格地判定一段时间是否为burst;而减小a1/a0则可以降低判定burst的严格程度,即更容易将一段时间判定为burst。
需要注意的是,a1/a0的设置需要根据具体的数据集和研究问题来灵活选择,以得到更加准确和有用的分析结果。通常情况下,a1/a0的取值范围在0到1之间,取值越大则判定burst的标准越严格。同时,也需要结合其他Burstiness参数的影响来综合调整。
Number of States(状态数)
这个参数表示Burstiness算法中状态数的数量,也就是Burst Detection过程中被划分的状态数。这个参数可以用于控制Burst Detection算法的精度和速度,通常情况下可以根据数据集的大小和研究问题的需求来灵活选择。
如果数据集较大或需要进行更精细的Burst Detection分析,可以适当增加状态数,以提高算法的精度和准确性;如果数据集较小或时间紧迫,可以适当减少状态数,以缩短算法运行时间。需要注意的是,Number of States参数的设置也需要考虑其他Burstiness参数的影响,以得到更加准确和有用的分析结果。
γ
取值范围在[0,1]之间。γ表示在计算burst的过程中,用于衡量某个词在当前时间片中出现的频率与其历史平均出现频率之间的相对大小。具体来说,当γ为0时,只考虑当前时间片内词汇的出现频率;当γ为1时,只考虑历史平均出现频率;而当γ取值在0到1之间时,则同时考虑当前时间片内词汇的出现频率和历史平均出现频率。通过调整γ的取值,可以控制Burstiness算法在计算burst时对当前时间片内和历史时间片内词汇出现频率的权重分配,从而获得更加准确和有用的分析结果。
需要注意的是,γ的取值需要根据具体的数据集和研究问题来灵活选择,以达到更好的分析效果。通常情况下,γ的取值在0到1之间,可以根据实际需要进行微调。同时,也需要结合其他Burstiness参数的影响来综合调整。
Burst Items Found
这个参数表示在Burstiness算法中发现的burst事件的数量。Burstiness算法通过识别时间序列中的潜在burst事件来分析文献集合的研究主题和热点领域。Burst Items Found参数可以帮助用户了解整个文献集合的burst事件分布情况,从而更好地把握文献集合的研究热点和趋势。
需要注意的是,Burst Items Found参数的大小与其他参数的取值有关。一般来说,较大的Burst Items Found值可能意味着较松的参数设置,而较小的Burst Items Found值可能意味着较严格的参数设置。因此,在使用Burstiness算法时,需要灵活调整各个参数的取值,以达到更好的分析效果。
2.2 Labels
(1) Keyword|Term|Overlay Labels
By Degree
在Citespace的控制面板中,"Label"选项下的"By Degree"选项可以用于设置文献节点标签的显示方式,以度数大小来标注节点的重要性。
在Citespace中,节点的度数指的是节点所连接的边的数量,即节点的出度和入度之和。一个节点的度数越大,表示该节点与其他节点之间的连接越紧密,影响力也就越大。
"By Degree"选项提供了多种不同的方式来显示节点的度数信息,如可以将节点的度数值作为标签内容显示在节点旁边,也可以通过标签的字体大小、颜色、形状等方式来表示节点的度数大小。
通过"By Degree"选项的设置,用户可以更加直观地了解文献节点的重要性,从而更好地进行文献分析和可视化。
By Freq
在Citespace的控制面板中,"Label"选项下的"By Freq"选项可以用于设置文献节点标签的显示方式,以文献被引用次数(或其他频率)来标注节点的重要性。
"By Freq"选项提供了多种不同的方式来显示文献节点的引用次数信息,如可以将文献节点的引用次数值作为标签内容显示在节点旁边,也可以通过标签的字体大小、颜色、形状等方式来表示节点的引用次数大小。
通过"By Freq"选项的设置,用户可以更加直观地了解文献节点的重要性,从而更好地进行文献分析和可视化。
By Centrality
在CiteSpace的控制面板中,"Label"选项下的"By Centrality"选项可以用于设置文献节点标签的显示方式,以文献节点在网络中的中心性指标来标注节点的重要性。
中心性指标是用于衡量节点在网络中的重要性和影响力的一种指标。常见的中心性指标包括度中心性、介数中心性、接近度中心性等。在CiteSpace中,"By Centrality"选项提供了多种不同的中心性指标来设置文献节点的标签。
用户可以根据自己的分析需要选择合适的中心性指标,例如使用介数中心性来标注文献节点的重要性,或者使用PageRank算法计算文献节点的权重值来作为标签内容等。通过"By Centrality"选项的设置,用户可以更加准确地了解文献节点的重要性和影响力,从而更好地进行文献分析和可视化。
By Eigen.Centrality
"By Eigen.Centrality"是CiteSpace控制面板中的一个标签设置选项,它可以将文献节点的标签按照其在网络中的特征向量中心性(eigenvector centrality)指标大小来显示。
特征向量中心性是一种衡量节点在网络中影响力的指标,它考虑了一个节点直接邻居节点的数量和质量,同时也考虑了这些邻居节点的重要性。因此,特征向量中心性是一个比较综合的指标,可以用于评价节点在网络中的重要性和影响力。
通过使用"By Eigen.Centrality"选项,用户可以将具有较高特征向量中心性的文献节点标注为更加重要和具有更高影响力的节点,从而更好地进行文献分析和可视化。
By Burstness
"By Burstness"是CiteSpace控制面板中的一个标签设置选项,它可以将文献节点的标签按照它们在时间上的爆发性(burstness)指标大小来显示。
爆发性是指某个节点在时间序列中出现的次数与该节点在时间序列中出现的平均次数之比。如果某个节点在时间序列中的出现频率较高,那么它的爆发性就越高。
通过使用"By Burstness"选项,用户可以将具有较高爆发性的文献节点标注为更加具有代表性和重要性的节点,从而更好地进行文献分析和可视化。
Hide Labels
"Hide Labels"是CiteSpace控制面板中的一个标签设置选项,它可以将文献节点的标签隐藏或者显示。通过使用该选项,用户可以在文献共被引关系网络图中隐藏节点标签,从而更好地聚焦于节点之间的连线关系,更清晰地展现图形结构,帮助用户发现更有意义的节点和连接。
(2) Threshold
"Threshold"是CiteSpace控制面板中的一个参数,它用于控制在网络中显示的节点和边的数量。具体来说,当用户设置了一个阈值值之后,只有节点或者边的重要性大于或等于该值时,它们才会被显示在网络中。如果节点或者边的重要性低于该阈值,则会被过滤掉,从而使网络变得更加清晰简洁。该参数的合适取值需要结合具体研究的目的和数据集的特点来确定。
(3) Font Size
"Font size"是CiteSpace控制面板中的一个参数,它用于控制节点标签的字体大小。具体来说,当用户设置一个字体大小后,CiteSpace会根据节点的重要性和阈值来自动调整节点标签的大小,以使得节点的重要性更加直观地呈现出来。通常情况下,重要性较高的节点会用较大的字体标签来突出显示,而重要性较低的节点会用较小的字体标签来展示。该参数的合适取值也需要根据具体研究的目的和数据集的特点来确定。
(4) Node Size
"Node size"是CiteSpace控制面板中的一个参数,它用于控制节点的大小。具体来说,当用户设置一个节点大小后,CiteSpace会根据节点的重要性和阈值来自动调整节点的大小,以使得节点的重要性更加直观地呈现出来。通常情况下,重要性较高的节点会用较大的尺寸来展示,而重要性较低的节点会用较小的尺寸来展示。该参数的合适取值也需要根据具体研究的目的和数据集的特点来确定。在CiteSpace中,节点的大小可以反映不同的度量指标,例如:被引用次数、出现次数等等。

















 6304
6304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









