







Hadoop简介与入门
来源
由Apache Lucene创始人Doug Cutting创建的,Lucene是一个应用广泛的文本搜索系统库。Hadoop起源于开源的网络搜索引擎Apache Nutch,它诞生之初是作为Luncene项目的一个重要核心组成部分。
发展
2008年1月,Hadoop已成为Apache的顶级项目,证明了它的成功、多样化和生命力。到目前为止,除雅虎之外,还有很多公司在用Hadoop,例如Last.fm、Facebook和《纽约时报》等。
2008年4月,Hadoop打破世界纪录,成为最快的TB级数据排序系统。在一个910节点的群集,Hadoop在209秒内(不到3.5分钟)完成了对1TB数据的排序,击败了前一年的297秒冠军。同年11月,谷歌在报告中声称,它的MapReduce对1TB数据排序只用了68秒。2009年5月有报道称雅虎有一个的团队使用Hadoop对1TB数据进行排序只花了62秒。
地位
现在,Hadoop已经跃升为企业主流的部署系统。在工业界,Hadoop已经是公认的大数据通用存储和分析平台,这一事实主要体现在大量直接使用或者间接辅助Hadoop系统的产品如雨后春笋般大量涌现。一些大公司也发布Hadoop发行版本,包括EMC,IBM,Microsft和Oracle以及一些专注于Hadoop的公司,如cloudera,Hortonworks,和MapR。
Hadoop及其生态系统
尽管Hadoop因MapReduce及其分布式文件系统(HDFS)而出名,但Hadoop这个名字也用于泛指一组相关的项目,这些相关项目都使用这个基础平台进行分布式计算和海量数据处理。
主要功能:
分布式计算和海量数据处理
MapReduce
分而治之:
Map:将数据按照不同的类型分别的整理出来。
Reduce:处理不同类型的数据,进行整合,提取有用的结果。
安装Hadoop步骤:
安装Linux系统(以Ubuntu为例)
安装配置JDK
安装配置SSH(Secure Shell,可以用来进行远程控制或在计算机之间传送文件)
安装Hadoop
运行示例代码
配置Hadoop集群
操作记录
找到Java路径
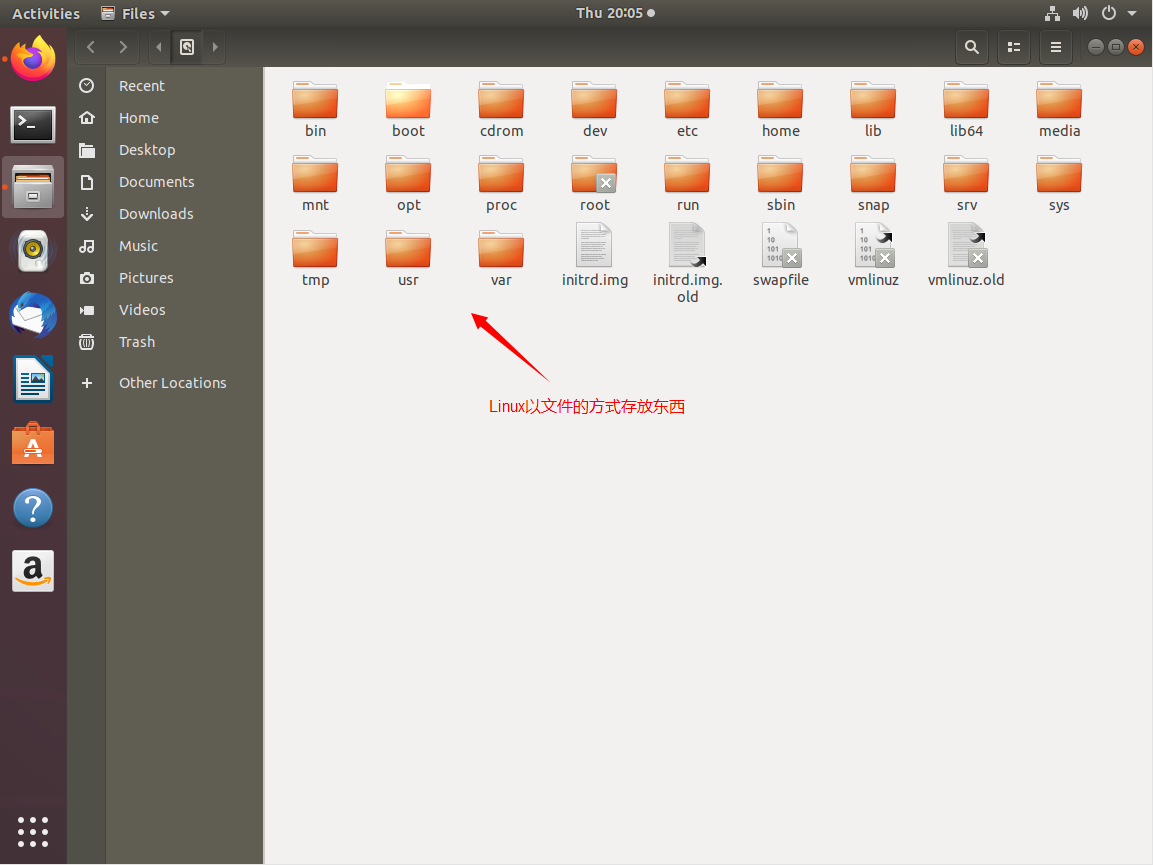
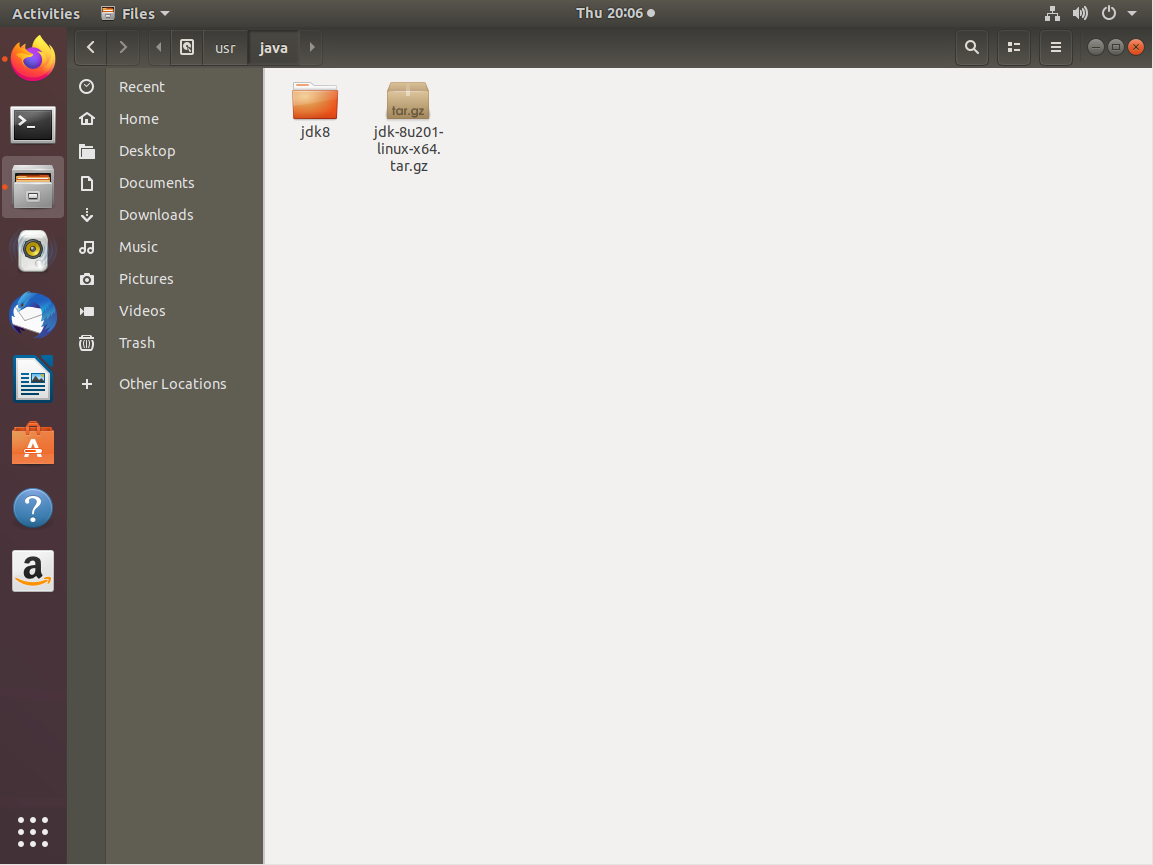
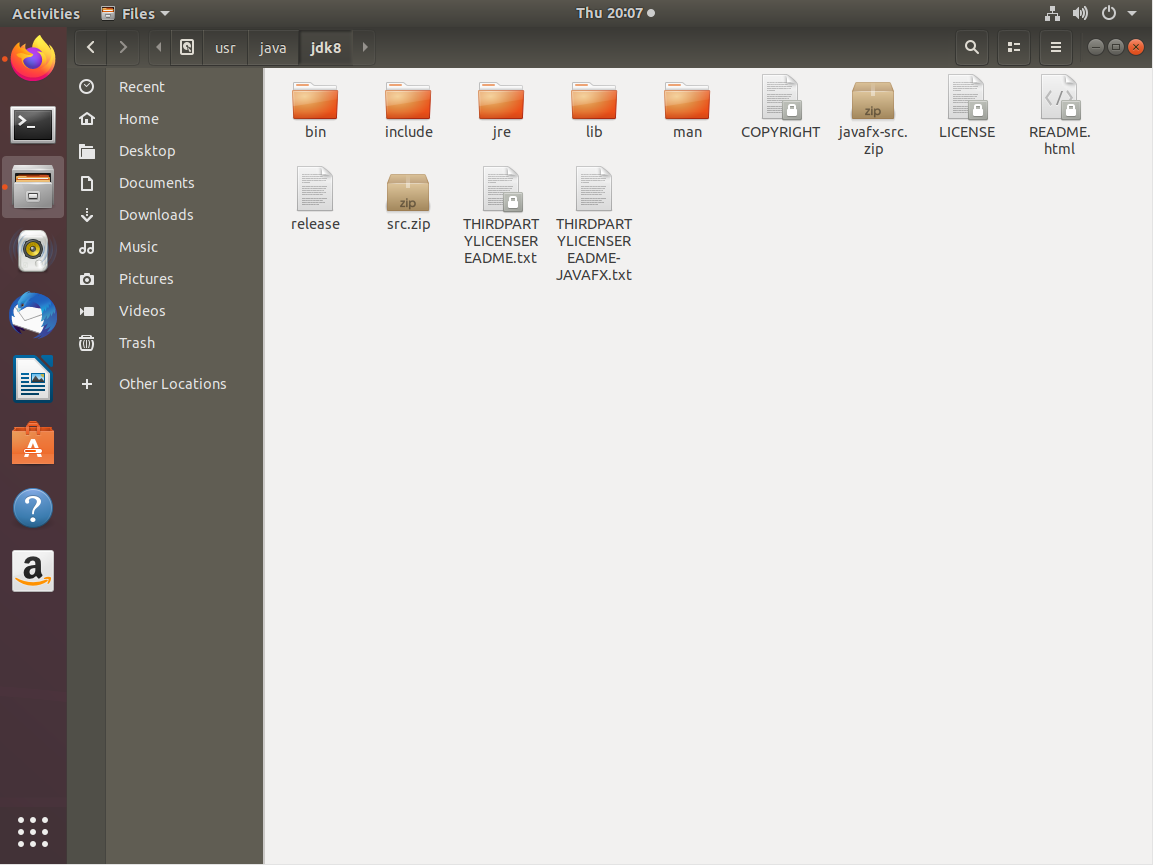
指令介绍

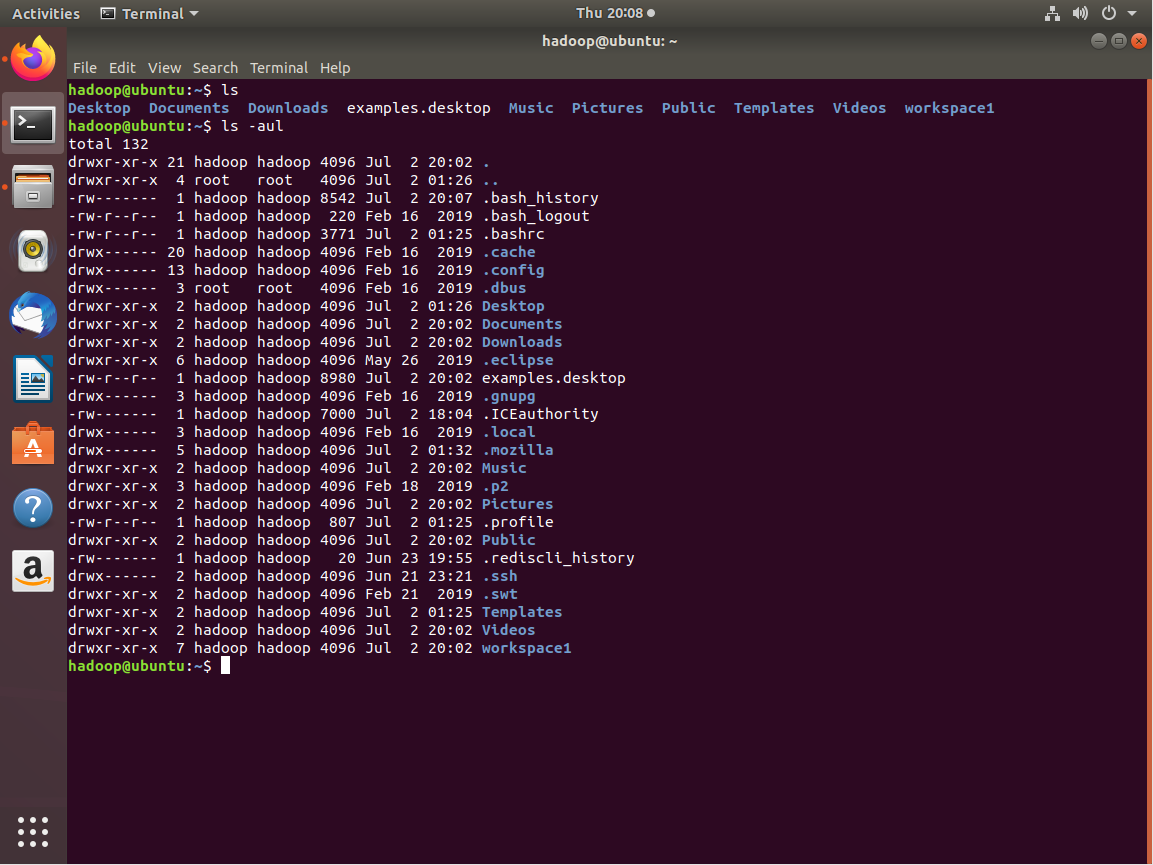
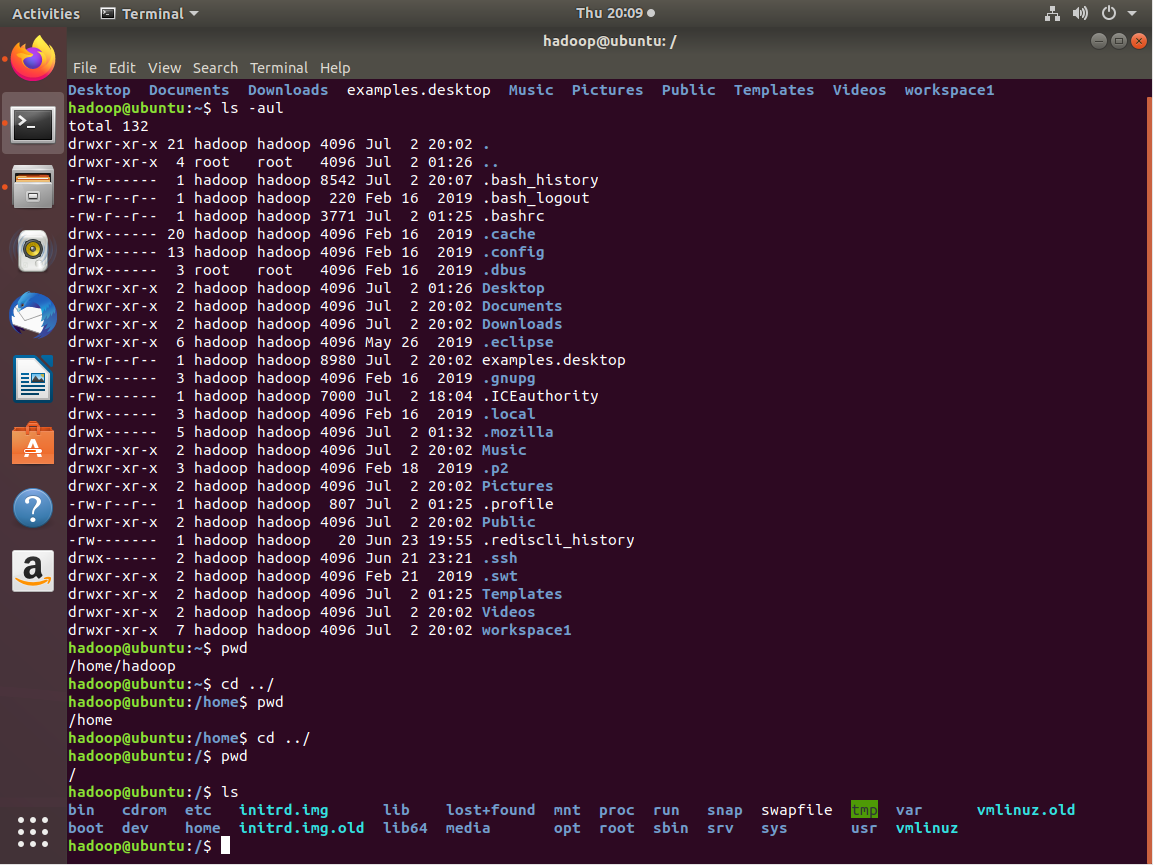
















 4331
4331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











