






 本文详细讲解了C语言中结构体的声明、初始化方法,包括自引用和嵌套结构体,以及内存对齐规则对效率的影响。还讨论了结构体传参的区别和位段的使用,提醒读者注意跨平台问题。
本文详细讲解了C语言中结构体的声明、初始化方法,包括自引用和嵌套结构体,以及内存对齐规则对效率的影响。还讨论了结构体传参的区别和位段的使用,提醒读者注意跨平台问题。
本章内容:
1 结构体类型声明及其初始化
2 结构体的自引用
3 结构体内存对齐
4 结构体传参
5 结构体实现位段(位段的填充&可移植性)
1 结构体类型声明 (struct)
结构体是一种用户自定义的数据类型,用于组合不同类型的数据项,定义结构体时使用struct
例如描述一个学生
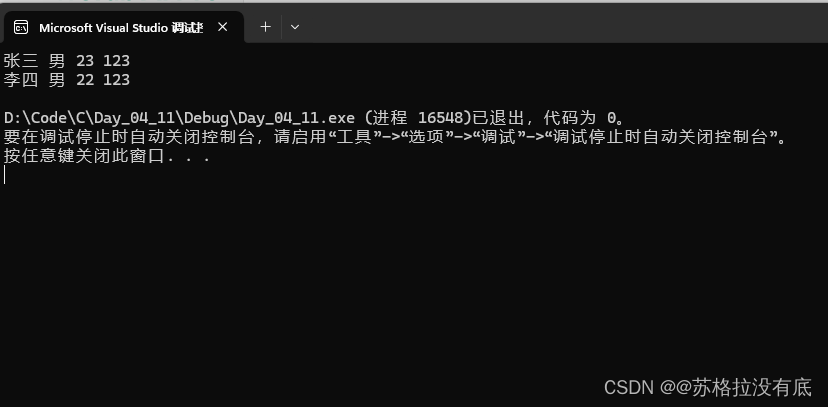
struct Student { char name[20]; char sex[3]; int age; char id[20]; }s1 = {"张三","男",23,"123"};//可以在这里定义变量并且初始化,这里是直接按顺序初始化。 //也可以这样初始化,使用. 操作符,可以按任意顺序初始化。 struct Student s2; s2 = (struct Student) {.id = "123",.age = 22,.name = "李四",.sex = "男"}; printf("%s %s %d %s\n", s1.name, s1.sex, s1.age, s1.id); printf("%s %s %d %s\n", s2.name, s2.sex, s2.age, s2.id);运行结果截图:
注意:在 C 语言中,对结构体进行赋值初始化时,只能在定义结构体变量的时候使用“成员初始化列表”,而不能在其他地方使用。
//这是错误的 struct Student s2; s2 = { .id = "123",.age = 22,.name = "李四",.sex = "男" }; //你可以这样 struct Student s2; s2 = (struct Student) {.id = "123",.age = 22,.name = "李四",.sex = "男"}; //也可以这样: struct Student s2 = { .id = "123",.age = 22,.name = "李四",.sex = "男" };;
2 结构体嵌套和自引用:
结构体嵌套:在结构体中包含一个类型为结构体成员
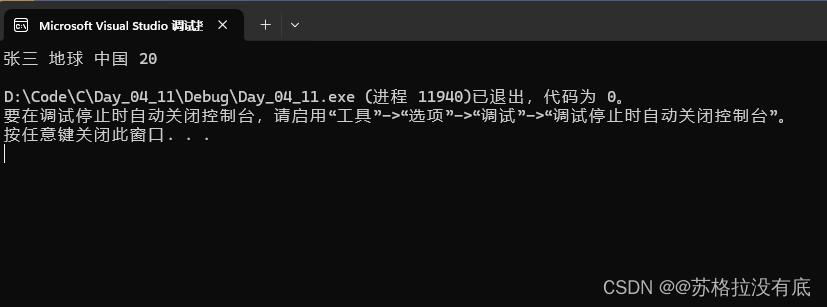
//结构体嵌套 int main() { struct Address { char city[20]; char street[20]; }; struct Student { char name[20]; struct Address address;//结构体嵌套 int age; }; //声明并初始化结构体变量 struct Student s1 = { "张三",{"地球","中国"},20 }; printf("%s %s %s %d\n", s1.name, s1.address.city, s1.address.street, s1.age); }运行结果:
结构体自引用:在结构体中包含一个类型为该结构体本身的成员。如模仿链表:
int main() { struct Node { int date; struct Node * next;//nect是一个指向结构体Node的指针。 } }
3 结构体内存对齐
观察下面代码和输出结果。
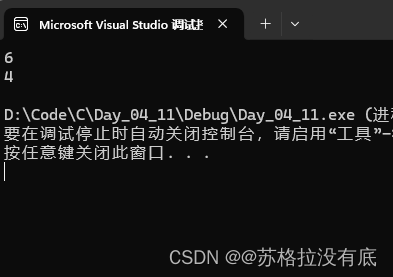
struct s1 { char a; short b; char c; }; struct s2 { char a; char b; short c; }; int main() { printf("%d\n", sizeof(struct s1)); printf("%d\n", sizeof(struct s2)); }输出结果:
可以发现两个结构体成员变量一模一样,但是所占大小却不相同
这就要了解结构体成员变量在内存中的存储了,也就是我们标题所说的结构体内存对齐
对齐规则:
对齐数:编译器默认的一个对齐数和该变量成员大小的较小值。vs默认是8。
1 第一个成员在与结构体偏移量为0的地址处。
2 其他成员变量要对齐到对其数的整数倍地址处
3 结构体总大小要为最大对齐数的整数倍
4如果嵌套了结构体,嵌套的结构体对齐到自己的最大对齐数的整数倍上,结构体的总大小就是所有最大对齐数(含嵌套结构体)的整数倍
了解规则之后我们一起分析分析上面代码
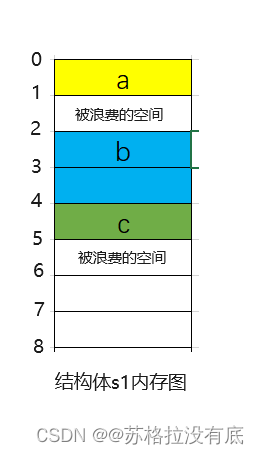
先看结构体s1
这个图是结构体变量s1的内存图,占6个字节,第一个结构体成员便量是char a;占一个字节,然后第二个结构体成员变量是short b,占两个字节,但是short的对齐数是2,vs默认的是8,取最小的是2所以short的存放要在偏移量为2的整数倍的地址上。所以偏移量要从2开始放,偏移量为1的那个地址要倍浪费掉。然后接下来是char c,vs默认偏移量是8,取小的是1,4是1的整数倍,所以直接往下放,此时已经用了5个字节的空间了,然后总大小要是最大偏移量的整数倍,这里的最大偏移量是结构体成员中最大的变量占的字节数,所以是2,现在已经占了5个字节了,为了是2的整数倍,我们还要浪费一个空间,所以占6个字节。
结构体s2
char a;要放在便宜量为0的位置,占一个字节,char 的对齐数是1,默认的是8,取较小的是1,要放在1的整数倍上,所以我们直接往下放即可,然后到short c;默认对齐数是8;short是2,取较小值所以是2,要放在2的倍数上,所以从2开始放,往后面占两个空间,最后结构体的总大小要是最大对齐数的整数倍,这里最大对齐数是2,我们现在已经占了4个空间了,所以刚刚好,一个空间都没浪费。
内存对齐的原因:
内存对齐能提高访问效率,地址的访问是以2的幂方就行访问的。在设计程序的时候我们要尽量让空间小的成员放在前面。

4 结构体传参
/结构体传参 struct S { int date[1000]; int num; }; void print1(struct S s) { printf(s.num); } void print2(struct S* N) { printf("%d", N->num); } struct S s = { {1,2,3,4,5,},5 }; int main() { print1(s);//传结构体 print2(&s);//传结构体地址 }上面两种结构体传参方式,那种更好一些呢?
显然是第二中,我们传参数的时候,如果是传结构体给函数,那么函数在调用的时候也会开辟一个零时空间,会有时间和空间的开销,但是当我们传地址时,就会避免这种情况,节约时间和空间。
4 位段:
位段结构与结构体类似:用于将数据字段拆分为比特位进行存储,从而更加灵活的利用内存空间。
//位段 struct S { unsigned int bite1 : 1;//开辟一个比特位空间,只能存储0-1的数据范围 unsigned int bite2 : 3;//开辟了三个比特位空间,只能储存000-111的数据范围 }; int main() { struct S s = { 1,7 }; printf("%d %d\n", s.bite1, s.bite2); struct S s1 = { 2,11 }; printf("%d %d", s1.bite1, s1.bite2); }运行结果:
可以看见并发现,位段表示的是开辟几个比特位,不是开辟几个字节,并且位段成员的类型只能是unsigned int ,signed int, 或者char(属于整型家族)
注意:
位段跨平台存在问题,所以在使用的时候要慎用,因为不同编译器对内存的拿取和存放是不同的。















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









