






 文章讲述了如何使用Python的Pandas库处理Excel数据,将11-14时段的降雨量平均分配到每个小时,并对数据进行插值处理,以便于后续的时间序列分析。作者通过代码展示了数据清洗、时间格式转换、跨日期处理和重新采样的步骤。
文章讲述了如何使用Python的Pandas库处理Excel数据,将11-14时段的降雨量平均分配到每个小时,并对数据进行插值处理,以便于后续的时间序列分析。作者通过代码展示了数据清洗、时间格式转换、跨日期处理和重新采样的步骤。
顺便把降雨的也改了改,弄出来。一直有疑惑,这个时段降雨该对应哪个时间段,我这里把它对应在开始时段了。(求个基础扎实的大佬回答一下)
原来:
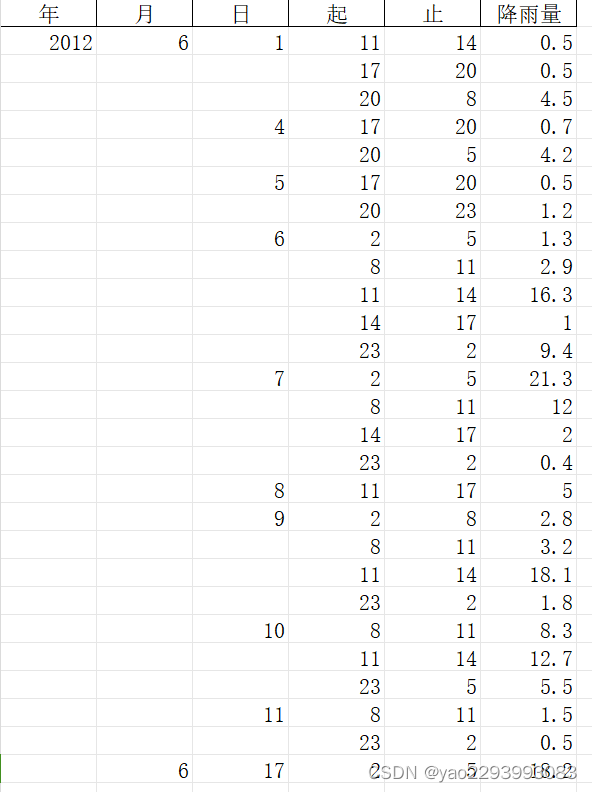
现在:
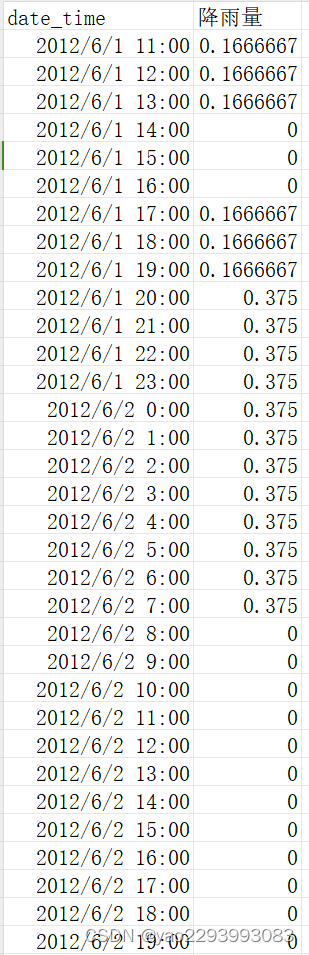
我把11-14时段的降雨,平均到每个时段初 ,14时取为0了。(不知道能不能这样平均)。
1、前置步骤
和前面洪水差不多 ,直接贴代码了。
后面两行做了点处理,一行是应对1日20:00跨到2日8时这种情况,结束时间加一天就可以了。降雨起起点这行是为后面计算均值方便,直接新加了列全为0。
# 读取数据
df = pd.read_excel('洪水要素.xlsx', sheet_name='Sheet4')
# 填补空缺值
df.fillna(method='ffill', inplace=True)
# 转换时间格式
df['date'] = df['年'].astype('int').map(str) + "/" + df['月'].astype('int').map(str) + "/" + df['日'].astype('int').map(str)
time_list1 = df['起'].copy()
time_list2 = df['止'].copy()
for i in range(len(time_list1)):
time_list1[i] = datetime.strptime(str(time_list1[i]), '%H').strftime('%H:%M:%S')
time_list2[i] = datetime.strptime(str(time_list2[i]), '%H').strftime('%H:%M:%S')
df['起'] = time_list1
df['止'] = time_list2
df['start_time'] = pd.to_datetime(df['date']) + pd.TimedeltaIndex(df['起'])
df['end_time'] = pd.to_datetime(df['date']) + pd.TimedeltaIndex(df['止'])
# 处理跨日期的情况
df.loc[df['start_time'] > df['end_time'], 'end_time'] += pd.DateOffset(days=1)
# 移除原来的年、月、日、时列
df = df.drop(columns=['年', '月', '日', '起', '止'])
df.insert(loc=2, column='降雨起点', value=0)2、计算过程
比洪水简单,只有小时尺度,直接处理就好了。
# 遍历列表进行计算
interpolated_data = []
for i in range(len(df) - 1):
start_time = df.loc[i, 'start_time']
end_time = df.loc[i, 'end_time']
start_hour = start_time.hour
end_hour = end_time.hour
prcp = df.loc[i, '降雨量']
time_diff = (end_time - start_time).total_seconds() / 3600 # 时间差, 以小时计
prcp_mean = df.loc[i, '降雨量'] / time_diff
for j in range(0, int(time_diff)):
new_time = start_time + pd.DateOffset(hours=j) # 时间偏移量
new_flow = df.loc[i, '降雨起点'] + prcp_mean
interpolated_data.append((new_time, new_flow))3、结果处理
直接放进新的Dataframe,不用考虑原来的df。重采样和Nanto0是为了填补中间缺失的时间段,也算是个小处理。
# 创建新的DataFrame
df_new = pd.DataFrame(interpolated_data, columns=['date_time', '降雨量'])
# 索引
df_new = df_new.set_index('date_time')
# 将索引转换为DatetimeIndex类型
df_new.index = pd.to_datetime(df_new.index)
# 对时间序列进行重新采样
df_new = df_new[~df_new.index.duplicated(keep='first')].resample('H').asfreq()
# 填补Nan值
df_new.fillna(0, inplace=True)
df_new.to_csv('降雨均值.csv')
print(df_new)4、完整代码
from datetime import datetime
import numpy as np
import pandas as pd
# 读取数据
df = pd.read_excel('洪水要素.xlsx', sheet_name='Sheet4')
# 填补空缺值
df.fillna(method='ffill', inplace=True)
# 转换时间格式
df['date'] = df['年'].astype('int').map(str) + "/" + df['月'].astype('int').map(str) + "/" + df['日'].astype('int').map(str)
time_list1 = df['起'].copy()
time_list2 = df['止'].copy()
for i in range(len(time_list1)):
time_list1[i] = datetime.strptime(str(time_list1[i]), '%H').strftime('%H:%M:%S')
time_list2[i] = datetime.strptime(str(time_list2[i]), '%H').strftime('%H:%M:%S')
df['起'] = time_list1
df['止'] = time_list2
df['start_time'] = pd.to_datetime(df['date']) + pd.TimedeltaIndex(df['起'])
df['end_time'] = pd.to_datetime(df['date']) + pd.TimedeltaIndex(df['止'])
# 处理跨日期的情况
df.loc[df['start_time'] > df['end_time'], 'end_time'] += pd.DateOffset(days=1)
# 移除原来的年、月、日、时列
df = df.drop(columns=['年', '月', '日', '起', '止'])
df.insert(loc=2, column='降雨起点', value=0)
# 遍历列表进行计算
interpolated_data = []
for i in range(len(df) - 1):
start_time = df.loc[i, 'start_time']
end_time = df.loc[i, 'end_time']
start_hour = start_time.hour
end_hour = end_time.hour
prcp = df.loc[i, '降雨量']
time_diff = (end_time - start_time).total_seconds() / 3600 # 时间差, 以小时计
prcp_mean = df.loc[i, '降雨量'] / time_diff
for j in range(0, int(time_diff)):
new_time = start_time + pd.DateOffset(hours=j) # 时间偏移量
new_flow = df.loc[i, '降雨起点'] + prcp_mean
interpolated_data.append((new_time, new_flow))
# 创建新的DataFrame
df_new = pd.DataFrame(interpolated_data, columns=['date_time', '降雨量'])
# 索引
df_new = df_new.set_index('date_time')
# 将索引转换为DatetimeIndex类型
df_new.index = pd.to_datetime(df_new.index)
# 对时间序列进行重新采样
df_new = df_new[~df_new.index.duplicated(keep='first')].resample('H').asfreq()
# 填补Nan值
df_new.fillna(0, inplace=True)
df_new.to_csv('降雨均值.csv')
print(df_new)

















 4481
4481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









