







 本文详细介绍了Python数据预处理的四个关键步骤:数据清洗涉及缺失值、异常值和重复值的处理;数据集成通过merge、concat和combine_first函数实现;数据变换包括特征归一化、二值化、连续特征变换和定性特征哑编码;数据归约则探讨了特征选择的各种策略。通过这些方法,可以将原始数据转化为适合模型训练的格式。
本文详细介绍了Python数据预处理的四个关键步骤:数据清洗涉及缺失值、异常值和重复值的处理;数据集成通过merge、concat和combine_first函数实现;数据变换包括特征归一化、二值化、连续特征变换和定性特征哑编码;数据归约则探讨了特征选择的各种策略。通过这些方法,可以将原始数据转化为适合模型训练的格式。
进行数据分析时,需要预先把进入模型算法的数据进行数据预处理。一般我们接收到的数据很多都是“脏数据”,里面可能包含缺失值、异常值、重复值等;同时有效标签或者特征需要进一步筛选,得到有效数据,最终把原始数据处理成符合相关模型算法的输入标准,从而进行数据分析与预测。下面将介绍数据预处理中的四个基本处理步骤:
目录
一、数据清洗
数据清洗主要将原始数据中的缺失值、异常值、重复值进行处理,使得数据开始变得“干净”起来。
1.缺失值
1.1缺失值可视化
运用python中的missingno库,此库需要下载导入
#提前进行这一步:pip install missingno
#导入相关库
import missingno as msno
import pandas as pd
import numpy as np可视化方法一:无效矩阵的数据密集显示
#读取文件
df=pd.read_csv('C:/Users/27812/Desktop/1-Advertising.csv')
#缺失值的无效矩阵的数据密集显示
fig1=msno.matrix(df,labels=True)
b=fig1.get_figure()
b.savefig('C:/Users/27812/Desktop/a.png',pdi=500)#保存图片
注意:其中白色的横条表示为缺失值,黑色部分表示有值的部分
可视化方法二:运用列的无效简单可视化
#缺失值的条形图显示
fig2=msno.bar(df)
b=fig2.get_figure()
b.savefig('C:/Users/27812/Desktop/b.png',pdi=500)#保存图片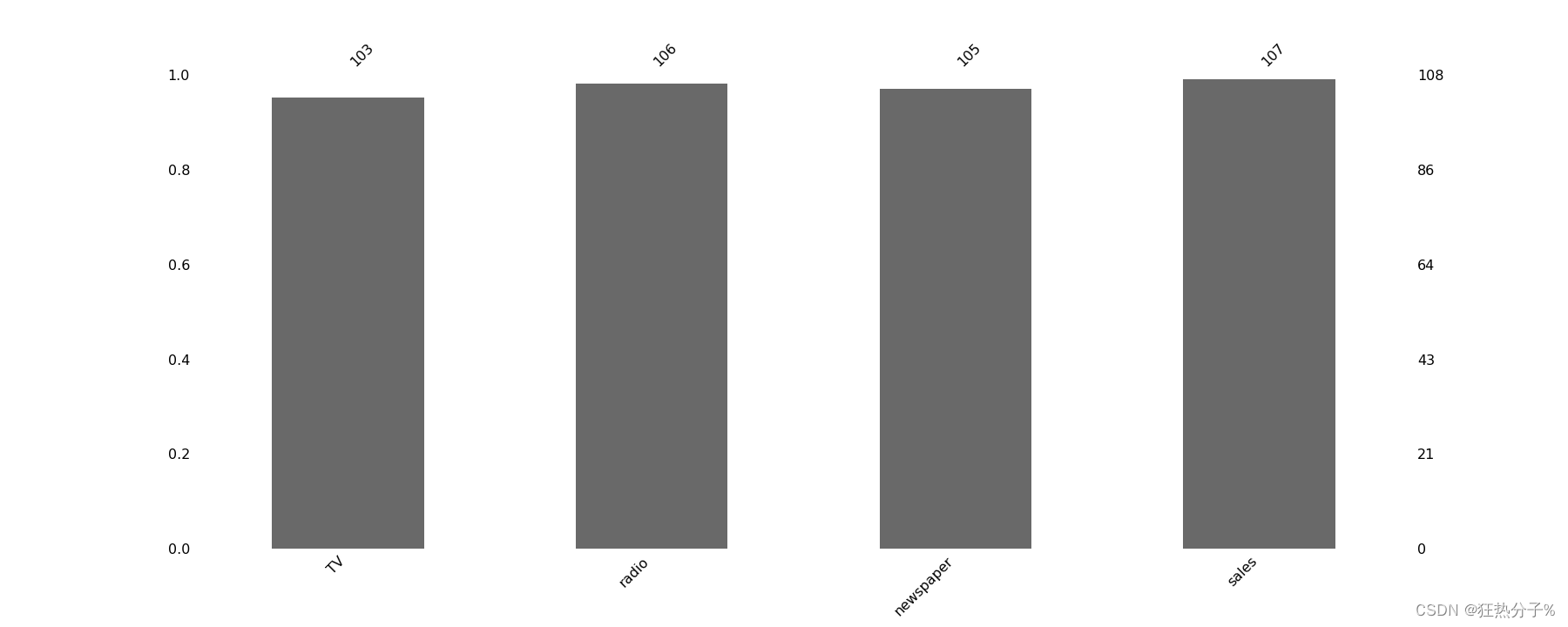
1.2缺失值处理
方法一:当缺失率少且重要度较高时,运用pandas里面的fillna函数进行填充。
方法二:当缺失率高且重要度较低时,可以运用pandas里面的dropna函数直接进行删除。
方法三:当缺失率高且重要度高时,运用插补法或建模法。其中插补法有:随机插补法、多重插补法、热平台插补、拉格朗日插值法、牛顿插值法等;建模法:利用回归、贝叶斯、决策树等模型对缺失数据进行预测。
2.异常值
异常值的来源主要分为人为误差和自然误差,例如:数据输入错误、测量误差、故意异常值、抽样错误、自然异常值、数据处理错误等等。
2.1异常值可视化
主要运用python里面的seaborn库绘制箱线图,查看异常值,如何绘制请详看上期文章
2.2异常值识别
方法一:Z-score方法
# 通过Z-Score方法判断异常值,阙值设置为正负2
# 复制一个用来存储Z-score得分的数据框,常用于原始对象和复制对象同时进行操作的场景
df_zscore = df.copy()
for col in all_colums:
df_col = df[col]
z_score = (df_col - df_col.mean()) / df_col.std() # 计算每列的Z-score得分
df_zscore[col] = z_score.abs() > 2 # 判断Z-score得分绝对值是否大于2,大于2即为异常值
print(df_zscore)#显示为True的表示为异常值
# 剔除异常值所在的行
print(df[df_zscore['列名一'] == False])
print(df[df_zscore['列名二'] == False])
print(df[df_zscore['列名三'] == False])方法二:基于正态分布的离群点检测(3原则)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7406
7406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











